
【NLP】文本分类综述 (上)
NewBeeNLP公众号原创出品
公众号专栏作者 @lucy
北航博士在读 · 文本挖掘/事件抽取方向
本系列文章总结自然语言处理(NLP)中最基础最常用的「文本分类」任务,主要包括以下几大部分:
综述(Surveys) 深度网络方法(Deep Learning Models) 浅层网络模型(Shallow Learning Models) 数据集(Datasets) 评估方式(Evaluation Metrics) 展望研究与挑战(Future Research Challenges) 实用工具与资料(Tools and Repos)
文本分类综述
A Survey on Text Classification: From Shallow to Deep Learning,2020[1]
文本分类是自然语言处理中最基本,也是最重要的任务。由于深度学习的成功,在过去十年里该领域的相关研究激增。鉴于已有的文献已经提出了许多方法,数据集和评估指标,因此更加需要对上述内容进行全面的总结。
本文通过回顾1961年至2020年的最新方法填补来这一空白,主要侧重于从浅层学习模型到深度学习模型。我们首先根据方法所涉及的文本,以及用于特征提取和分类的模型,构建了一个对不同方法进行分类的规则。然后我们将详细讨论每一种类别的方法,涉及该方法相关预测技术的发展和基准数据集。
此外,本综述还提供了不同方法之间的全面比较,并确定了各种评估指标的优缺点。最后,我们总结了该研究领域的关键影响因素,未来研究方向以及所面临的挑战。
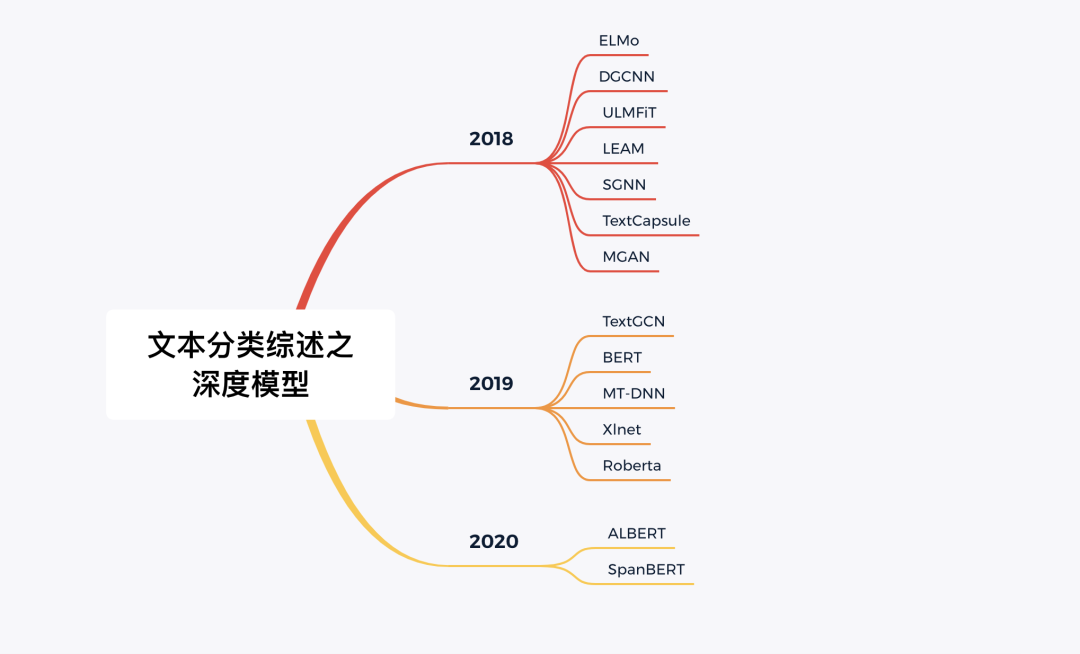
深度学习模型
本部分按年份时间顺序整理了文本分类任务相关的深度模型。
2011
Semi-supervised recursive autoencoders forpredicting sentiment distributions[2]
介绍了一种新颖地基于递归自动编码器机器学习框架,用于句子级地情感标签分布预测。该方法学习多词短语的向量空间表示。在情感预测任务中,这些表示优于常规数据集(例如电影评论)上的其他最新方法,而无需使用任何预定义的情感词典或极性转换规则。
论文还将根据经验项目上的效果来评估模型在新数据集上预测情绪分布的能力。数据集由带有多个标签的个人用户故事组成,这些标签汇总后形成捕获情感反应的多项分布。与其他几个具有竞争力的baseline相比,我们的算法可以更准确地预测此类标签的分布。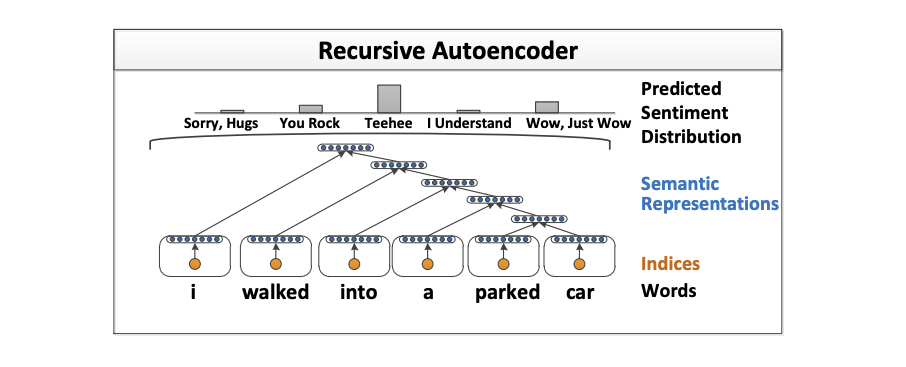
2012
Semantic compositionality through recursive matrix-vector spaces[3]
基于单个词的向量空间模型在学习词汇信息方面非常成功。但是,它们无法捕获较长短语的组成含义,从而阻止了它们更深入理解地理解语言。本文介绍了一种循环神经网络(RNN)模型,该模型学习任意句法类型和长度的短语或句子的成分向量表示。
模型为解析树中的每个节点分配一个向量和一个矩阵:其中向量捕获成分的固有含义,而矩阵捕获其如何改变相邻单词或短语的含义。该矩阵-向量RNN可以学习命题逻辑和自然语言中算子的含义。该模型在三种不同的实验中均获得了SOTA效果:预测副词-形容词对的细粒度情绪分布;对电影评论的情感标签进行分类,并使用名词之间的句法路径对名词之间的因果关系或主题消息等语义关系进行分类。
2013
Recursive deep models for semantic compositionality over a sentiment treebank[4]
尽管语义词空间在语义表征方面效果很好,但却不能从原理上表达较长短语的含义。在诸如情绪检测等任务中的词语组合性理解方向的改进需要更丰富的监督训练和评估资源, 以及更强大的合成模型。
为了解决这个问题,我们引入了一个情感树库。它在11,855个句子的语法分析树中包含215,154个短语的细粒度情感标签,并在情感组成性方面提出了新挑战。为了解决这些问题,我们引入了递归神经张量网络。在新的树库上进行训练后,该模型在多个评价指标上效果优于之前的所有方法。它使单句正/负分类的最新技术水平从80%上升到85.4%。预测所有短语的细粒度情感标签的准确性达到80.7%,相较于基准工作提高了9.7%。此外,它也是是唯一一个可以在正面和负面短语的各个树级别准确捕获消极影响及其范围的模型。
2014
Convolutional Neural Networks for Sentence Classification[5]
我们在卷积神经网络(CNN)上进行一系列实验,这些卷积神经网络在针对句子级别分类任务的预训练单词向量的基础上进行了训练。实验证明,几乎没有超参数调整和静态矢量的简单CNN在多个基准上均能实现出色的结果。
通过微调来学习针对特定任务的单词向量可进一步提高性能。此外,我们还提出了对体系结构进行简单的修改,以让模型能同时使用针对特定任务的单词向量和静态向量。本文讨论的CNN模型在7个任务中的4个上超过了现有的SOTA效果,其中包括情感分析和问题分类。
A convolutional neural network for modelling sentences[6]
准确的句子表征能力对于理解语言至关重要。本文提出了一种被称为动态卷积神经网络(Dynamic Convolutional Neural Network , DCNN)的卷积体系结构,用来对句子的语义建模。网络使用一种线性序列上的全局池化操作,称为动态k-Max池化。网络处理长度可变的输入句子,并通过句子来生成特征图, 该特征图能够显式捕获句中的短期和长期关系。该网络不依赖于语法分析树,并且很容易适用于任何语言。
本文在四个实验中测试了DCNN:小规模的二类和多类别情感预测,六向问题分类以及通过远程监督的Twitter情感预测。相对于目前效果最好的基准工作,本文的网络在前三个任务中标系出色的性能,并且在最后一个任务中将错误率减少了25%以上。
Distributed representations of sentences and documents[7]
许多机器学习算法要求将输入表示为固定长度的特征向量。当涉及到文本时,词袋模型是最常见的表示形式之一。尽管非常流行,但词袋模型有两个主要缺点:丢失了单词的顺序信息,并且也忽略了单词的语义含义。例如在词袋中,“powerful”,“strong”和“Paris”的距离相等(但根据语义含义,显然“powerful”和”strong”的距离应该更近)。
因此在本文中,作者提出了一种无监督算法,用于学习句子和文本文档的向量表示。该算法用一个密集矢量来表示每个文档,经过训练后该向量可以预测文档中的单词。它的构造使本文的算法可以克服单词袋模型的缺点。实验结果表明,本文的技术优于词袋模型以及其他用于文本表示的技术。最后,本文在几个文本分类和情感分析任务上获得了SOTA效果。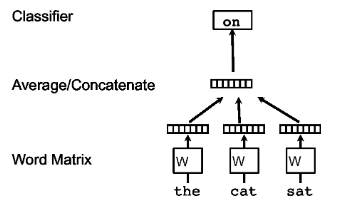
2015
Character-level convolutional networks for text classification[8]
本文提出了通过字符级卷积网络(ConvNets)进行文本分类的实证研究。本文构建了几个大型数据集,以证明字符级卷积网络可以达到SOTA结果或者得到具有竞争力的结果。可以与传统模型(例如bag of words,n-grams 及其 TFIDF变体)以及深度学习模型(例如基于单词的ConvNets和RNN)进行比较。
Improved semantic representations from tree-structured long short-term memory networks[9]
由于具有较强的序列长期依赖保存能力,具有更复杂的计算单元的长短时记忆网络(LSTM)在各种序列建模任务上都取得了出色的结果。然而,现有研究探索过的唯一底层LSTM结构是线性链。由于自然语言具有句法属性, 因此可以自然地将单词与短语结合起来。
本文提出了Tree-LSTM,它是LSTM在树形拓扑网络结构上的扩展。Tree-LSTM在下面两个任务上的表现优于所有现有模型以及强大的LSTM基准方法:预测两个句子的语义相关性(SemEval 2014,任务1)和情感分类(Stanford情感树库)。
Deep unordered composition rivals syntactic methods for text classification[10]
现有的许多用于自然语言处理任务的深度学习模型都专注于学习不同输入的语义合成性, 然而这需要许多昂贵的计算。本文提出了一个简单的深度神经网络,它在情感分析和事实类问题解答任务上可以媲美,并且在某些情况下甚至胜过此类模型,并且只需要少部分训练事件。尽管本文的模型对语法并不敏感, 但通过加深网络并使用一种新型的辍学变量,模型相较于以前的单词袋模型上表现出显著的改进。
此外,本文的模型在具有高句法差异的数据集上的表现要比句法模型更好。实验表明,本文的模型与语法感知模型存在相似的错误,表明在本文所考虑的任务中,非线性转换输入比定制网络以合并单词顺序和语法更重要。
Recurrent convolutional neural networks for text classification[11]
文本分类是众多NLP应用中的一项基本任务。传统的文本分类器通常依赖于许多人工设计的特征工程,例如字典,知识库和特殊的树形内核。与传统方法相比,本文引入了循环卷积神经网络来进行文本分类,而无需手工设计的特征或方法。
在本文的模型中,当学习单词表示时,本文应用递归结构来尽可能地捕获上下文信息,相较于传统的基于窗口的神经网络,这种方法带来的噪声更少。本文还采用了一个最大池化层,该层可以自动判断哪些单词在文本分类中起关键作用,以捕获文本中的关键组成部分。
本文在四个常用数据集进行了实验, 实验结果表明,本文所提出的模型在多个数据集上,特别是在文档级数据集上,优于最新方法。
2016
Long short-term memory-networks for machine reading[12]
在本文中,作者解决了如何在处理结构化输入时更好地呈现序列网络的问题。本文提出了一种机器阅读模拟器,该模拟器可以从左到右递增地处理文本,并通过记忆和注意力进行浅层推理。阅读器使用存储网络代替单个存储单元来对LSTM结构进行扩展。这可以在神经注意力循环计算时启用自适应内存使用,从而提供一种弱化token之间关系的方法。该系统最初设计为处理单个序列,但本文还将演示如何将其与编码器-解码器体系结构集成。在语言建模,情感分析和自然语言推理任务上的实验表明,本文的模型与SOTA相媲美,甚至优于目前的SOTA。
Recurrent neural network for text classification with multi-task learning[13]
基于神经网络的方法已经在各种自然语言处理任务上取得了长足的进步。然而在以往的大多数工作中,都是基于有监督的单任务目标进行模型训练,而这些目标通常会受训练数据不足的困扰。在本文中,作者使用多任务学习框架来共同学习多个相关任务(相对于多个任务的训练数据可以共享)。
本文提出了三种不同的基于递归神经网络的信息共享机制,以针对特定任务和共享层对文本进行建模。整个网络在这些任务上进行联合训练。在四个基准文本分类任务的实验表明,模型在某一任务下的性能可以在其他任务的帮助下得到提升。
Hierarchical attention networks for document classification[14]
本文提出了一种用于文档分类的层次注意力网络。该模型具有两个鲜明的特征:(1)具有分层模型结构,能反应对应层次的文档结构;(2)它在单词和句子级别上应用了两个级别的注意机制,使它在构建文档表征时可以有区别地对待或多或少的重要内容。
在六个大型文本分类任务上进行的实验表明,本文所提出的分层体系结构在很大程度上优于先前的方法。此外,注意力层的可视化说明该模型定性地选择了富有主要信息的词和句子。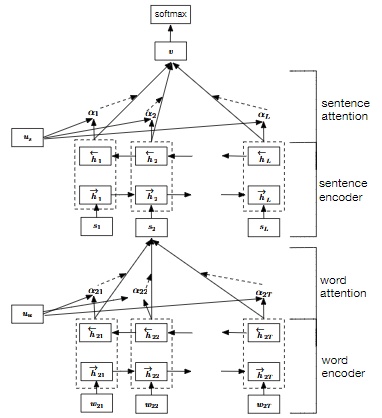
2017
Recurrent Attention Network on Memory for Aspect Sentiment Analysis[15]
本文提出了一种基于神经网络的新框架,以识别评论中意见目标的情绪。本文的框架采用多注意机制来捕获相距较远的情感特征,因此对于不相关的信息鲁棒性更高。多重注意力的结果与循环神经网络(RNN)进行非线性组合,从而增强了模型在处理更多并发情况时的表达能力。加权内存机制不仅避免了工作量大的特征工程工作,而且还为句子的不同意见目标提供了对应的记忆特征。
在四个数据集上的实验验证了模型的优点:两个来自SemEval2014,该数据集包含了例如餐馆和笔记本电脑的评论信息; 一个Twitter数据集,用于测试其在社交媒体数据上的效果;以及一个中文新闻评论数据集,用于测试其语言敏感性。实验结果表明,本文的模型在不同类型的数据上始终优于SOTA方法。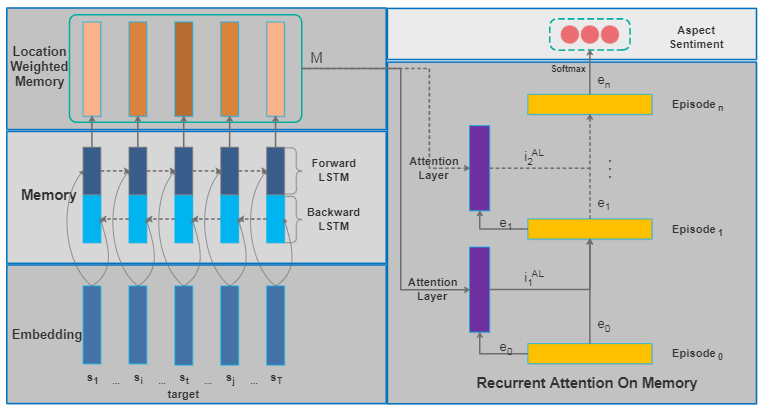
Interactive attention networks for aspect-level sentiment classification[16]
方面级别(aspect-level)的情感分类旨在识别特定目标在其上下文中的情感极性。先前的方法已经意识到情感目标在情感分类中的重要性,并开发了各种方法,目的是通过生成特定于目标的表示来对上下文进行精确建模。但是,这些研究始终忽略了目标的单独建模。
在本文中,作者认为目标和上下文都应受到特殊对待,需要通过交互式学习来学习它们自己的特征表示。因此,作者提出了交互式注意力网络(interactive attention networks , IAN),以交互方式学习上下文和目标中的注意力信息,并分别生成目标和上下文的特征表示。通过这种设计,IAN模型可以很好地表示目标及其搭配上下文,这有助于情感分类。在SemEval 2014数据集上的实验结果证明了本文模型的有效性。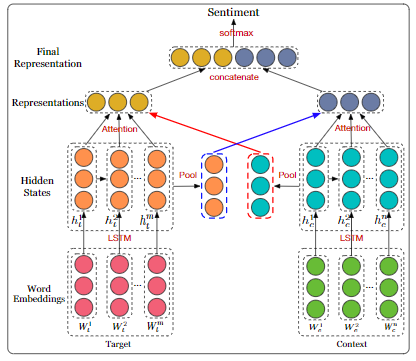
Deep pyramid convolutional neural networks for text categorization[17]
本文提出了一种用于文本分类的低复杂度的词语级深度卷积神经网络(CNN)架构,该架构可以有效地对文本中的远程关联进行建模。在以往的研究中,已经有多种复杂的深度神经网络已经被用于该任务,当然前提是可获得相对大量的训练数据。然而随着网络的深入,相关的计算复杂性也会增加,这对网络的实际应用提出了严峻的挑战。
此外,最近的研究表明,即使在设置大量训练数据的情况下,较浅的单词级CNN也比诸如字符级CNN之类的深度网络更准确,且速度更快。受这些发现的启发,本文仔细研究了单词级CNN的深度化以捕获文本的整体表示,并找到了一种简单的网络体系结构,在该体系结构下,可以通过增加网络深度来获得最佳精度,且不会大量增加计算成本。相应的模型被称为深度金字塔CNN(pyramid-CNN)。在情感分类和主题分类任务的六个基准数据集上,本文提出的具有15个权重层的模型优于先前的SOTA模型。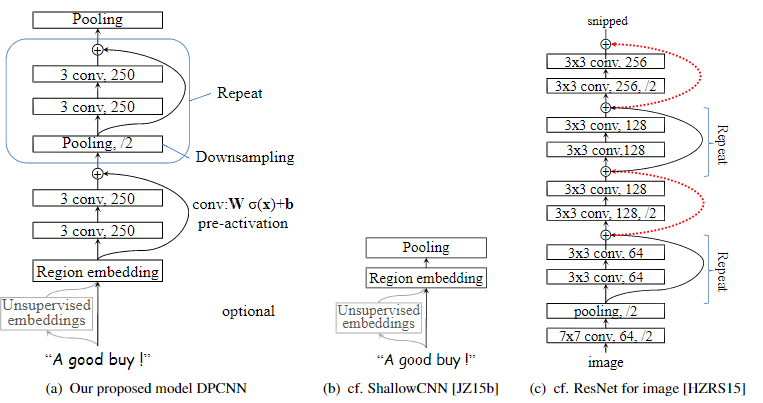
Bag of tricks for efficient text classification[18]
本文探讨了一种简单有效的文本分类基准。实验表明,本文的快速文本分类器fastText在准确性方面可以与深度学习分类器相提并论,而训练和预测速度要快多个数量级。可以使用标准的多核CPU在不到十分钟的时间内在超过十亿个单词的数据集上训练fastText,并在一分钟之内对属于312K个类别的50万个句子进行分类。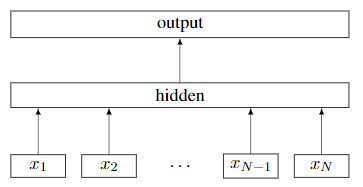
ok,不知不觉接近一万字,为了方便大家精准讨论,我们新建立了文本分类讨论组,欢迎过来玩耍~ 如果下方二维码过期或者人满,可以添加微信『text_b』,手动邀请你呀
下期预告
本文参考资料
A Survey on Text Classification: From Shallow to Deep Learning,2020: https://arxiv.org/pdf/2008.00364.pdf
[2]Semi-supervised recursive autoencoders forpredicting sentiment distributions: https://www.aclweb.org/anthology/D11-1014/
[3]Semantic compositionality through recursive matrix-vector spaces: https://www.aclweb.org/anthology/D12-1110/
[4]Recursive deep models for semantic compositionality over a sentiment treebank: https://www.aclweb.org/anthology/D13-1170/
[5]Convolutional Neural Networks for Sentence Classification: https://www.aclweb.org/anthology/D14-1181.pdf
[6]A convolutional neural network for modelling sentences: https://doi.org/10.3115/v1/p14-1062
[7]Distributed representations of sentences and documents: http://proceedings.mlr.press/v32/le14.html
[8]Character-level convolutional networks for text classification: http://papers.nips.cc/paper/5782-character-level-convolutional-networks-for-text-classification
[9]Improved semantic representations from tree-structured long short-term memory networks: https://doi.org/10.3115/v1/p15-1150
[10]Deep unordered composition rivals syntactic methods for text classification: https://doi.org/10.3115/v1/p15-1162
[11]Recurrent convolutional neural networks for text classification: http://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/view/9745
[12]Long short-term memory-networks for machine reading: https://doi.org/10.18653/v1/d16-1053
[13]Recurrent neural network for text classification with multi-task learning: https://www.ijcai.org/Abstract/16/408
[14]Hierarchical attention networks for document classification: https://doi.org/10.18653/v1/n16-1174
[15]Recurrent Attention Network on Memory for Aspect Sentiment Analysis: https://www.aclweb.org/anthology/D17-1047/
[16]Interactive attention networks for aspect-level sentiment classification: https://www.ijcai.org/Proceedings/2017/568
[17]Deep pyramid convolutional neural networks for text categorization: https://doi.org/10.18653/v1/P17-1052
[18]Bag of tricks for efficient text classification: https://doi.org/10.18653/v1/e17-2068
- END -
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: