
【NLP】文本分类微调技巧实战2.0
讯飞比赛答辩结束,笔者和小伙伴们参加了一些讯飞的比赛,今年讯飞文本分类比赛相比去年更加多元化,涉及领域、任务和数据呈现多样性,听完各位大佬的答辩之后,结合之前经验和以下赛题总结下文本分类比赛的实战思路。
讯飞文本分类赛题总结
1.1 非标准化疾病诉求的简单分诊挑战赛2.0 top3方案总结
赛事任务
进行简单分诊需要一定的数据和经验知识进行支撑。本次比赛提供了部分好大夫在线的真实问诊数据,经过严格脱敏,提供给参赛者进行单分类任务。具体为:通过处理文字诉求,给出20个常见的就诊方向之一和61个疾病方向之一
赛题特点
分类标签有两个,问诊方向和疾病方向,并且评估指标分别为macro-f1和micro-f1 疾病方向有不少数是缺失标签,数据集中值为-1 文本方向和疾病方向两种标签有一定约束关系,表现为比如问诊方向为“小二消化疾病”,疾病方向为“小儿消化不良” 数据特点
就诊方向标签中,其中内科、小儿保健、咽喉疾病数量比较多,骨科、甲状腺疾病问诊人数较少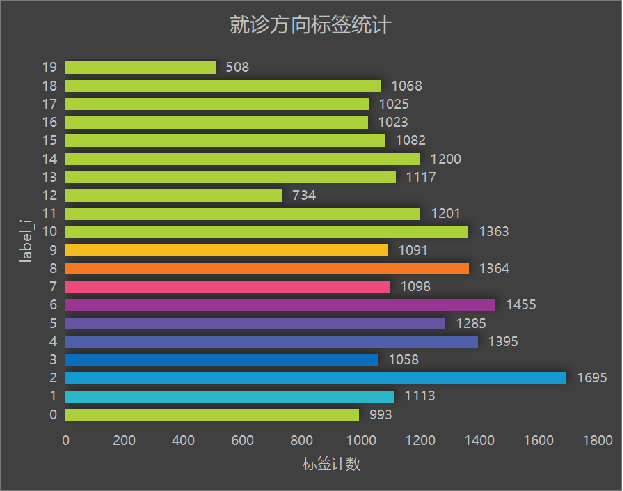
疾病方向标签中,其中内科其他最多,宫腔镜疾病人数较少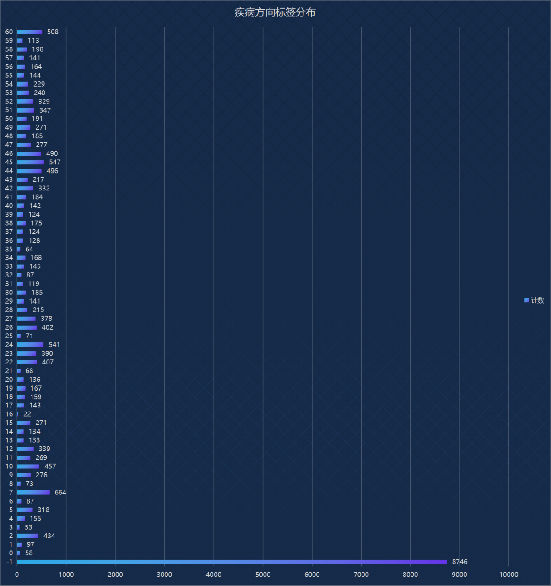
数据预处理
(1) 对于文本字段,缺失值直接用空字符串“”填充
(2) 对于spo.txt文件,根据第一列疾病名称构建聚合文本,用于文本语义增强,比如
(3)如果文本文本中含有疾病名称,就根据拼接对应疾病的聚合文本,然后按照文本信息曝光量拼接文本,比如疾病名称很大程度上指定了患者疾病类别归属, 注意:title和hopeHelp字段存在重复的情况,此时仅保留title即可
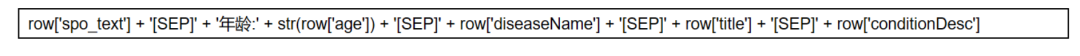
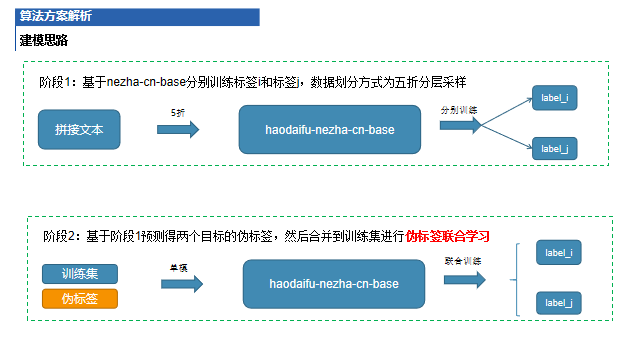
建模思路
赛题总结
问诊疾病的知识文本,每条包含主体/(属性)/客体的利用对标签学习具有提升效果 联合训练问诊方向与疾病方向标签相比单独训练各自标签的模型效果要好 伪标签学习能够进一步提升在疾病方向的效果
致谢队友:我的心是冰冰的、江东、pxx_player
1.2 中文语义病句识别挑战赛 top2方案总结
赛事任务
中文语义病句识别是一个二分类的问题,预测句子是否是语义病句。语义错误和拼写错误、语法错误不同,语义错误更加关注句子语义层面的合法性,语义病句例子如下表所示。
赛题特点
本次比赛使用的数据一部分来自网络上的中小学病句题库,一部分来自人工标注,比赛一开始拿到数据的时候,真的让人去做病句识别就很难 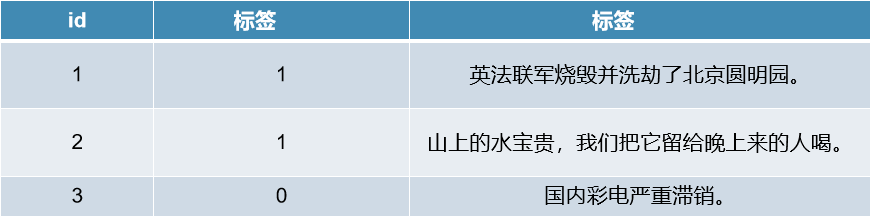
标签分布比较特殊,数据量比较大,1的数据是0的数量约3倍 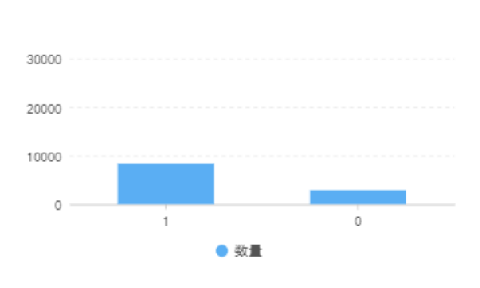
数据预处理
在比赛过程中,选手们可以发现这个数据比较容易拟合,通过分析其中有部分数据比较相似、甚至有些是重复数据,所以需要过滤去除重复数据,减少线差 数据划分采用多折分层采样
建模思路
在实验过程中,我们尝试了一些中文预训练模型,比如选择macbert或者具有纠错能力的模型,效果不错的是macbert和electra
shibing624/macbert4csc-base-chinese
hfl/chinese-macbert-base、hfl/chinese-macbert-large
nezha-large-zh
hfl/chinese-electra-large-discriminator
hfl/chinese-roberta-wwm-ext
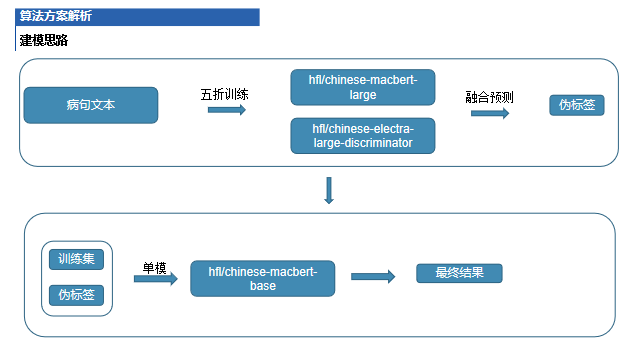
赛题总结
中文病句识别的预训练底座基础选型比较重要,其中electra和macbert不错,除此看其他大佬使用了prompt learning、pert模型 数据去重可以减少线差
致谢队友:江东、A08B06365ECB216A
1.3 人岗匹配挑战赛 top2方案总结
赛题任务
智能人岗匹配需要强大的数据作为支撑,本次大赛提供了大量的岗位JD和求职者简历的加密脱敏数据作为训练样本,参赛选手需基于提供的样本构建模型,预测简历与岗位匹配与否。
数据预处理
本次比赛为参赛选手提供了大量的岗位JD和求职者简历,其中:
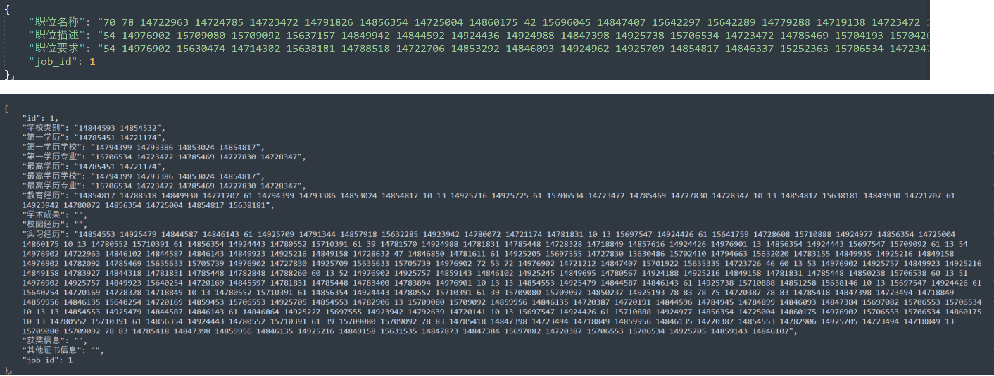
岗位JD数据包含4个特征字段:job_id, 职位名称, 职位描述, 职位要求
求职者简历数据包含15个特征字段:
id, 学校类别, 第一学历, 第一学历学校, 第一学历专业, 最高学历, 最高学历学校, 最高学历专业, 教育经历, 学术成果, 校园经历, 实习经历, 获奖信息, 其他证书信息, job_id。
在训练集中,job_id的数量分布如下,可以看出岗位4和12数量最多,38和37岗位比较少 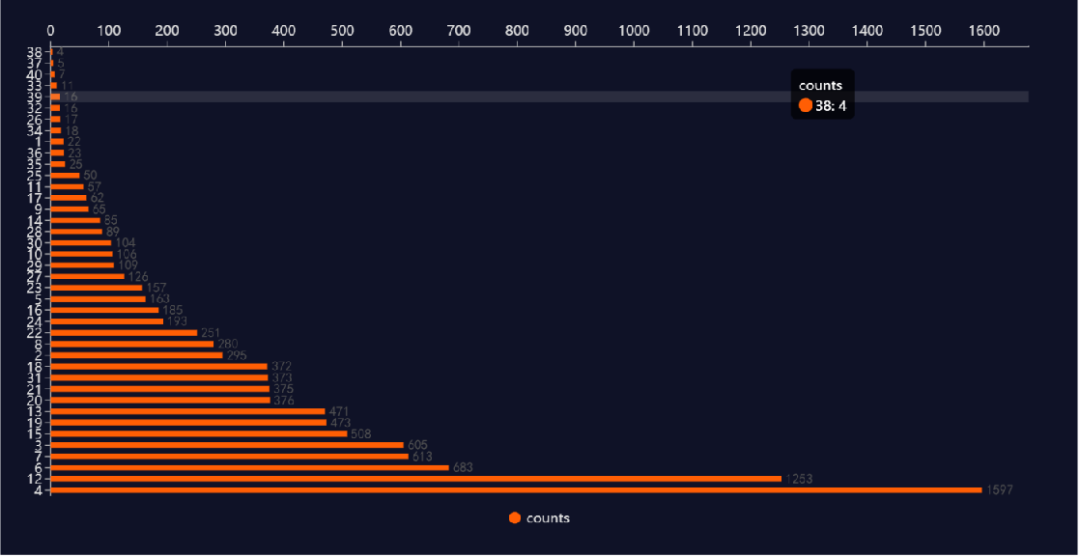
建模思路
词表构建
由于本次比赛数据为匿名数据,开源中文预训练模型不适用,因此需要重新构建词表、语料,进而重新训练预训练模型
第一步,构建词汇表,根据训练集、测试集和JD数据,按照空格分词,对所有文本进行切分,然后构建词汇表,另外需要加入五个特殊字符,[PAD]、[UNK]、[CLS]、[SEP]、[MASK],最后词汇表大小为4571预训练语料构建
由于本次比赛数据为匿名数据,开源中文预训练模型不适用,因此需要重新构建词表、语料,进而重新训练预训练模型
第二步,构建预训练语料,直接将学校类别, 第一学历, 第一学历学校, 第一学历专业, 最高学历, 最高学历学校, 最高学历专业, 教育经历, 学术成果, 校园经历, 实习经历, 获奖信息, 其他证书信息这些字段的文本拼接在一起,生成一个人的简历描述。

预训练任务
在实验过程中,我们选择了两种预训练模型结构:Bert和Nezha,其中Nezha效果要明显优于Bert
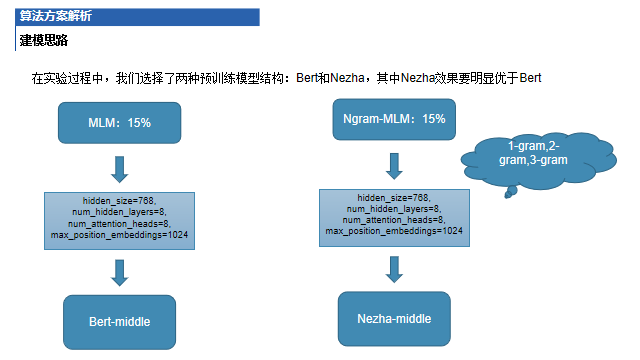
分类微调
将人岗匹配任务看做是文本分类任务,对简历文本进行多分类
赛题总结
在人岗匿名数据上微调,能够有效地捕获语义知识,并识别出不同岗位类型 NEZHA基于BERT模型,并进行了多处优化,能够在一系列中文自然语言理解任务达到先进水平 老肥队伍、举哥采用的思路都不同,给了很大启发,统计特征以及传统NN网络对文本分类进一步提升
致谢队友:WEI Z/江东/小泽/跟大佬喝口汤
优化算法合集
下面是一些常规套路,不一定每一个任务都有作用,和数据集、预训练模型有很大关系,大家可以酌情选择
FGM EMA PGD FreeLB AWP MultiDropout
-MixOut
微调方法总结
文本分类还有一些微调的小技巧,也欢迎大家补充
分层学习率 多折交叉验证 伪标签学习 Freeze Embedding Fp16混合精度训练
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码