
涨点神器GSA:全局自注意力网络,打造更强注意力模型

极市导读
本文提出一个新的全局自注意力模块:GSA,该模块足够高效,可以用作backbone组件。其由两个并行层组成:内容注意力层和位置注意力层,表现SOTA!性能优于SAN(CVPR 2020)等注意力网络。>>加入极市CV技术交流群,走在计算机视觉的最前沿
1、简介
由于自注意力的二次计算和存储复杂性,这些工作要么仅将注意力应用于深层网络后期的低分辨率特征图,要么将每层的注意力感受野限制在较小的局部区域。为了克服这些限制,本文引入了一个新的全局自注意力模块,称为GSA模块,该模块足够高效,可以用作深度网络的backbone组件。
该模块由两个并行层组成:一个内容注意力层,仅基于像素的内容对其进行关注;一个位置关注层,其基于像素的空间位置进行关注。该模块输出是两层输出的总和。在提出的GSA模块的基础上引入了独立的基于全局注意力的网络,该深度网络使用GSA模块来建模像素交互。由于所提出的GSA模块具有全局范围,所以GSA网络能够在整个网络中对远距离像素间的相互作用进行建模。
实验结果表明,GSA网络在使用较少的参数和计算量的情况下,在CIFAR-100和ImageNet数据集上显著优于基于卷积的网络。在ImageNet数据集上,提出的GSA网络也优于现有的各种基于注意力的网络。
2、相关方法
2.1、Auxiliary Visual Attention
Non-Local Block首次在计算机视觉中采用dot-product attention注意力机制进行long-range dependency建模,实验验证了该算法在视频分类和目标检测方面的有效性。
最近,一系列的工作将Transformer引入了计算机视觉领域。使用深度CNN模型提取语义特征,然后由Transformer对特征之间的高层交互进行建模。有学者使用Transformer建模对象级的交互以进行对象检测,也有学者使用Transformer建模帧间的依赖关系以进行视频表示学习。
这些辅助注意力方法在大部分卷积的网络中或仅在网络的末端使用注意模块。它们增强了CNN的远程交互建模,但仍然将大部分特征建模归为卷积操作。
2.2、Bacbone Visual Attention
由于Non-Local Block高昂的开销使得无法广泛替换卷积层,导致最终的模型仍然有大部分卷积模块。有研究人员将感受野限制在一个local内(通常是7*7)来解决这个问题。也有研究人员利用global attention的轴向分解来解决这个问题。
3、本文方法

3.1、Content Attention Layer
这一层使用以下基于内容的全局注意操作来生成新的特性:
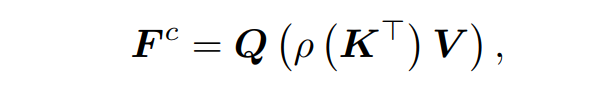
式中,为K的矩阵转置,表示对每一行分别进行softmax归一化的运算。这种注意力机制可以被视为第一个像素特征V通过使用中的权重聚合到dk全局上下文向量,然后重新分配全局上下文向量回每个像素使用Q。这个操作的计算和内存复杂度是O(N)。
3.2、Positional Attention Layer
内容注意层不考虑像素的空间位置,因此与像素变换是等变的。就其本身而言,它并不最适合处理空间结构化数据(如图像)的任务。本文通过使用位置注意层来解决这个问题,该层根据像素本身的内容及其相对于相邻像素的空间位置来计算像素的Attention map。对于每个像素,位置注意层关注它的L×L近邻spatial。
本文将这个注意层实现为一个仅存在列的注意层,然后是一个仅存在行的注意层。在仅列关注层中,输出像素只关注其列上的输入像素,而在仅行关注层中,输出像素只关注其行上的输入像素。让是一组L补偿,表示L沿着一条列可学的相对位置嵌入相应的矩阵空间偏移量。设为像素(a,b)的L列邻居处的值组成的矩阵。设表示像素点处的无列位置注意层的输出(a,b)。然后,仅列位置注意力机制,使用相对位置嵌入作为关键,可以描述使用:
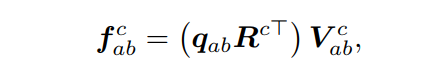
其中为像素点(a,b)处的查询。由于每个像素只关心L列邻居,因此这个仅列位置注意层的计算和存储复杂性为O(NL),其中N为像素的个数。类似地,可以使用L行邻居对应的L可学习相对位置嵌入来定义具有O(NL)计算和内存复杂性的仅行位置注意层。
3.3、GSA Network
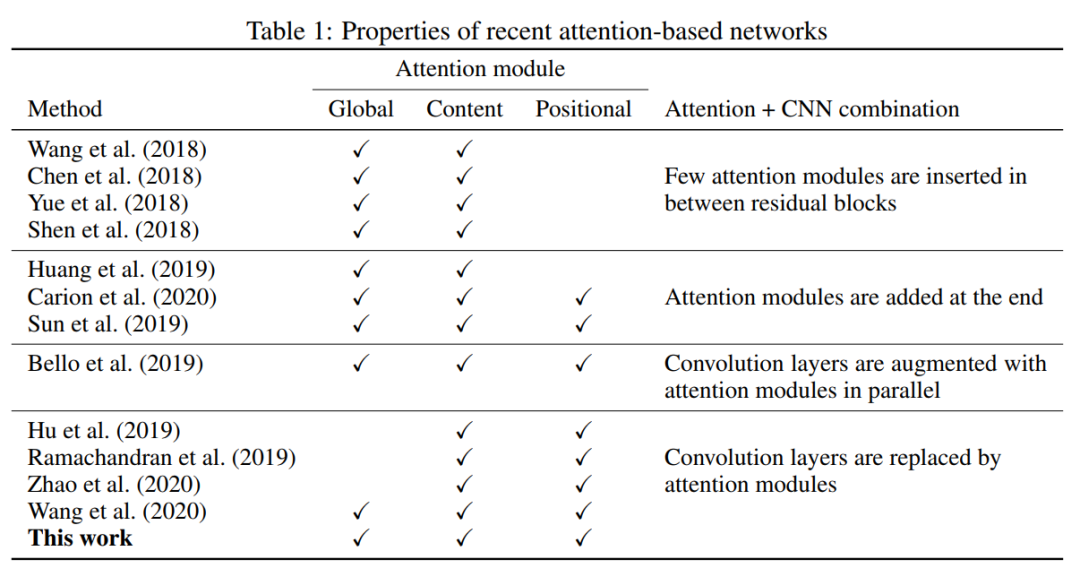
GSA网络是使用GSA模块而不是空间卷积来建模像素交互的深度网络。表1显示了GSA网络与最近各种基于注意力的网络的区别。
4、实验结果
4.1、基于CIFAR-100实验
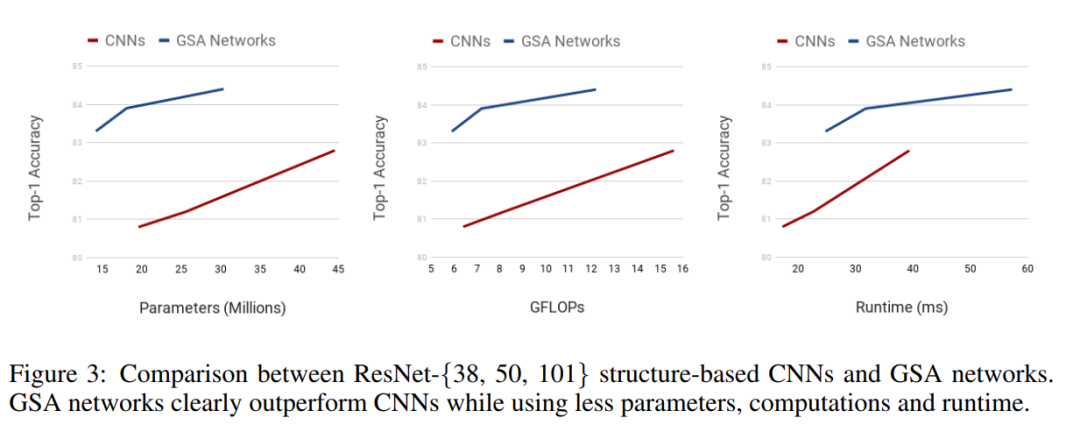
可以看出在CIFAR-100数据集上基于GSA的设计,参数更少,精度更高;
4.2、基于ImageNet实验

可以看出在ImageNet数据集上基于GSA的设计,参数更少,精度更高;
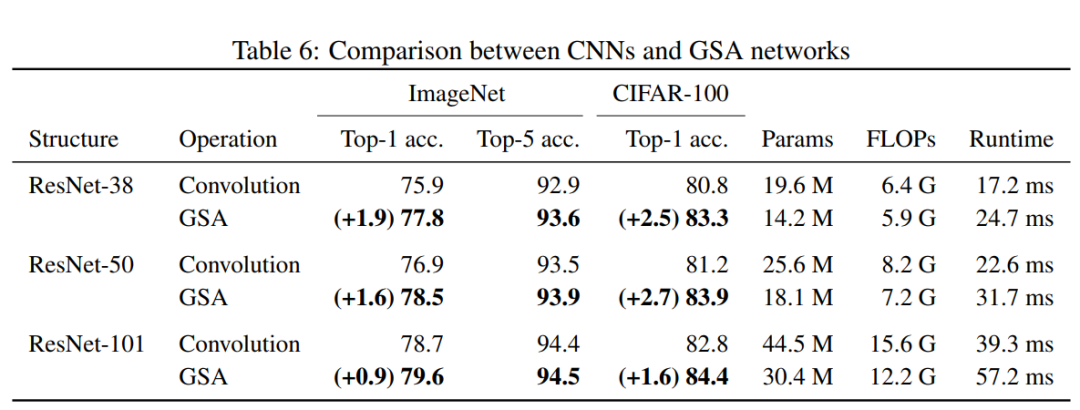
更为详细内容可以参见论文中的描述。
References
[1] GLOBAL SELF-ATTENTION NETWORKS
推荐阅读
