
【即插即用】涨点神器AFF:注意力特征融合(已经开源,附论文和源码链接)

这篇文章一种新注意力特征融合机制AFF!性能优于SKNet、SENet等方法,可应用于分类、语义分割和目标检测等方向。
1、简介
特征融合是指来自不同层或分支的特征的组合,是现代网络体系结构中很常见的一种操作。它通常通过简单的操作(例如求和或串联)来实现,但这可能不是最佳选择。在本论文中提出了一个统一而通用的方案,即注意力特征融合,该方案适用于大多数常见场景,包括由short and long skip connections以及在Inception层内的特征融合。
为了更好地融合语义和尺度不一致的特征,提出也了一个多尺度的通道注意力模块,该模块解决了在融合不同尺度的特征时出现的问题。同时还通过添加另一个注意力级别(称为迭代注意力特征融合)来缓解特征图的初始集成的瓶颈。
2、相关工作
2.1、Multi-scale Attention Mechanism
深度学习中的注意机制模仿人类视觉注意机制,比如Squeeze-and-Excitation Networks (SENet)将全局空间信息压缩到通道描述中,以捕获与通道的依赖关系。近年来,研究者开始考虑注意机制的scale尺度问题:
第1类:将多个尺度上的特征或它们连接的结果输入注意模块生成多尺度上的Faeture map,注意模块内上下文聚合的特征尺度要保持统一。 第2类:也被称为多尺度空间注意,通过大小不同的卷积核或从注意模块内的金字塔聚集上下文的特征。
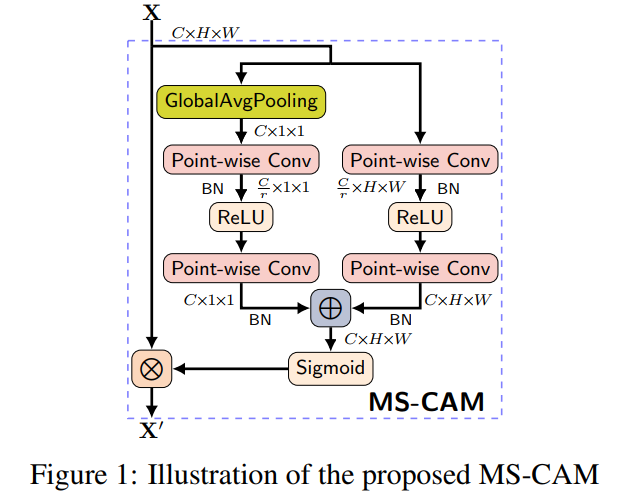
提出的MS-CAM遵循ParseNet的思想,结合局部和全局特征和空间注意的想法融合注意力模块内部的多尺度特征,在以下2个重要方面有所不同:
1)、MS-CAM通过逐点卷积来关注通道的尺度问题,而不是大小不同的卷积核。 2)、MS-CAM不是在主干网中,而是在通道注意力模块中局部本地和全局的特征上下文特征。
2.2、Skip Connections in Deep Learning
skip connection可以分为:Short Skip和Long Skip;
Short Skip:即在Res Block中添加的标识映射快捷方式,为反向传播期间梯度流提供了一种连续的替代路径;
Long Skip:通过连接较低层次的细节特征和较粗分辨率的高级语义特征,帮助网络获得高分辨率的语义特征。
最近,一些基于注意的方法,如全局注意Upsampe(GAU)和跳跃注意(SA),被提出使用高级特征作为引导来调节长跳跃连接中的低级特征。然而,调制特征的融合权重仍然是固定的。Highway Networks(高速公路网络)首次引入在跳连机制(skip connection)中引入选择机制(selection mechanism),而在某种程度上,注意力跳连接的提出可以被视为其后续,但是有3个不同点:
1)、高速公路网络使用一个简单的完全连接层,只能生成一个标量融合权重,MSCAM通过dynamic soft选择元素的方式生成融合权重大小相同的特征图; 2)、高速公路网络只使用一个输入特征来生成权重,而AFF模块同时感知这两个特征; 3)、指出了初始特征集成的重要性,提出了iAFF模块作为解决方案;
3 本文方法---MS-CAM
3.1、Multi-Scale Channel Attention Module(MS-CAM)
其核心思想是通过改变空间池的大小,可以在多个尺度上实现通道关注。为了使其尽可能轻量化只在attention模块中将局部上下文添加到全局上下文中。选择逐点卷积(PWConv)作为通道上下文融合器,它只利用每个空间位置的点向通道融合。
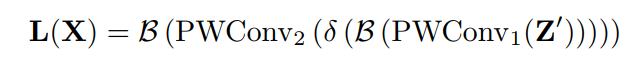
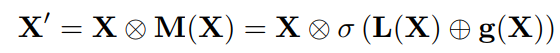
class ResGlobLocaChaFuse(HybridBlock):
def __init__(self, channels=64):
super(ResGlobLocaChaFuse, self).__init__()
with self.name_scope():
self.local_att = nn.HybridSequential(prefix='local_att')
self.local_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.local_att.add(nn.BatchNorm())
self.global_att = nn.HybridSequential(prefix='global_att')
self.global_att.add(nn.GlobalAvgPool2D())
self.global_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.global_att.add(nn.BatchNorm())
self.sig = nn.Activation('sigmoid')
def hybrid_forward(self, F, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = F.broadcast_add(xl, xg)
wei = self.sig(xlg)
xo = 2 * F.broadcast_mul(x, wei) + 2 * F.broadcast_mul(residual, 1-wei)
return xo
4. 模块
4.1、AFF模块
基于多尺度信道的注意模块M,Attentional Feature Fusion (AFF) 可以被表达为:
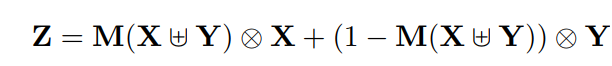
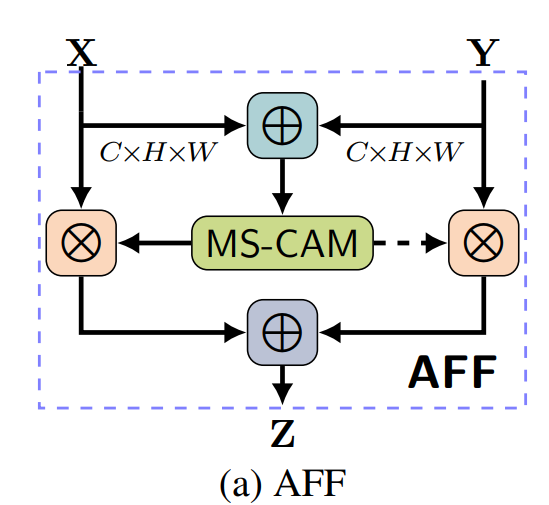
class AXYforXplusYAddFuse(HybridBlock):
def __init__(self, channels=64):
super(AXYforXplusYAddFuse, self).__init__()
with self.name_scope():
self.local_att = nn.HybridSequential(prefix='local_att')
self.local_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.local_att.add(nn.BatchNorm())
self.global_att = nn.HybridSequential(prefix='global_att')
self.global_att.add(nn.GlobalAvgPool2D())
self.global_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.global_att.add(nn.BatchNorm())
self.sig = nn.Activation('sigmoid')
def hybrid_forward(self, F, x, residual):
xi = x + residual
xl = self.local_att(xi)
xg = self.global_att(xi)
xlg = F.broadcast_add(xl, xg)
wei = self.sig(xlg)
xo = F.broadcast_mul(wei, residual) + x
return xo
4.2、iAFF模块
完全上下文感知方法有一个不可避免的问题,即如何初始地集成输入特性。初始融合质量作为注意力模块的输入会对最终融合权重产生影响。由于这仍然是一个特征融合问题,一种直观的方法是使用另一个attention模块来融合输入的特征,即iterative Attentional Feature Fusion (iAFF):
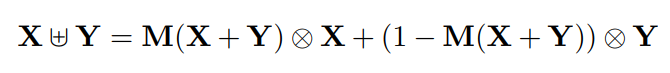
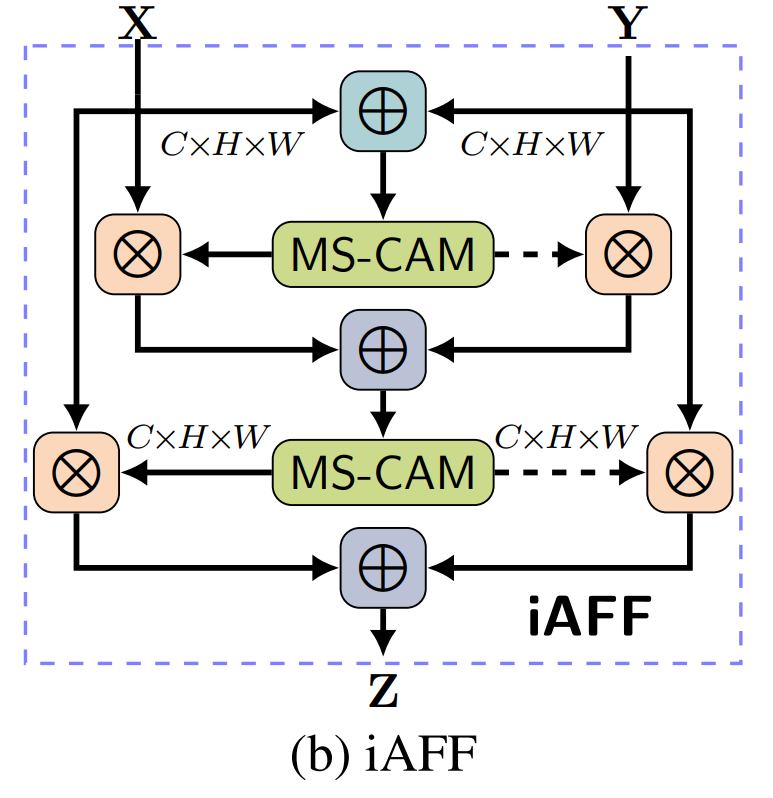
class AXYforXYAddFuse(HybridBlock):
def __init__(self, channels=64):
super(AXYforXYAddFuse, self).__init__()
with self.name_scope():
self.local_att = nn.HybridSequential(prefix='local_att')
self.local_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.local_att.add(nn.BatchNorm())
self.global_att = nn.HybridSequential(prefix='global_att')
self.global_att.add(nn.GlobalAvgPool2D())
self.global_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.global_att.add(nn.BatchNorm())
self.sig = nn.Activation('sigmoid')
def hybrid_forward(self, F, x, residual):
xi = x + residual
xl = self.local_att(xi)
xg = self.global_att(xi)
xlg = F.broadcast_add(xl, xg)
wei = self.sig(xlg)
xo = F.broadcast_mul(wei, xi)
return xo
5 实验和可视化结果
以下是作者根据现存的模型设计的部分模块以进行实验和对比: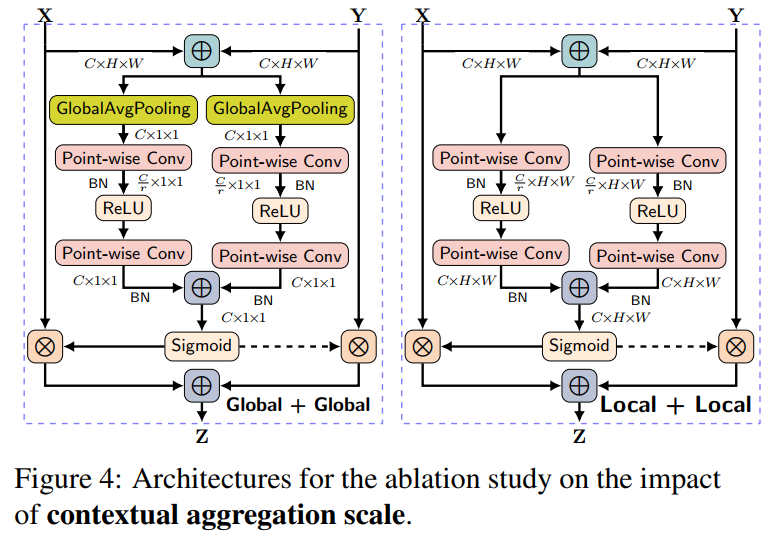
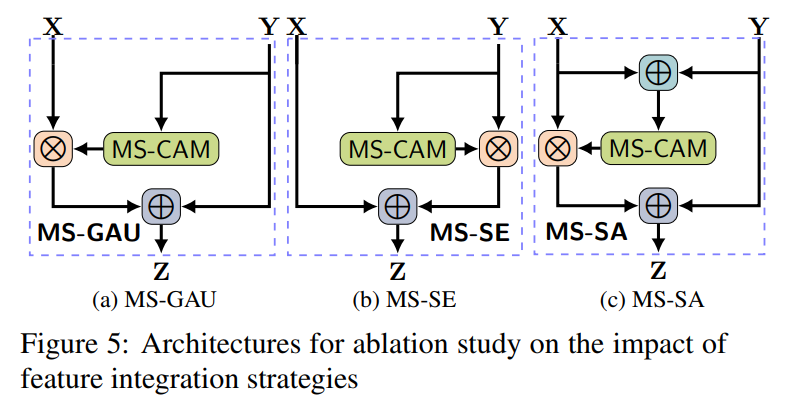
通过下面的表格可以看出本文所提方法的效果: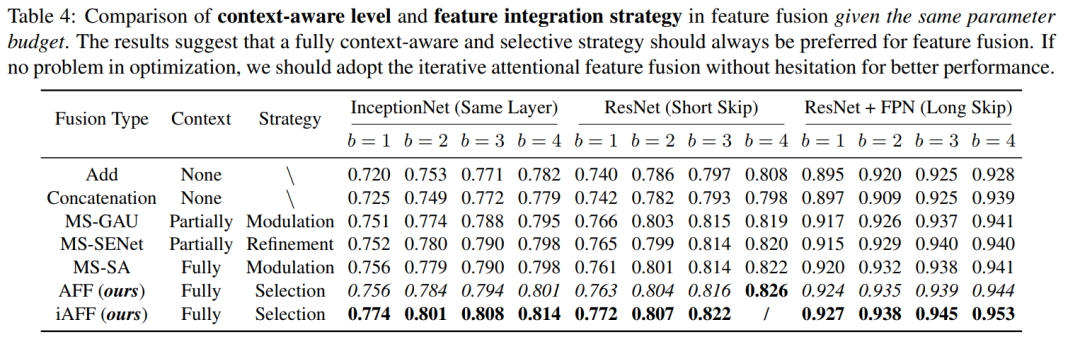
以下是基于Cifar100进行的实验: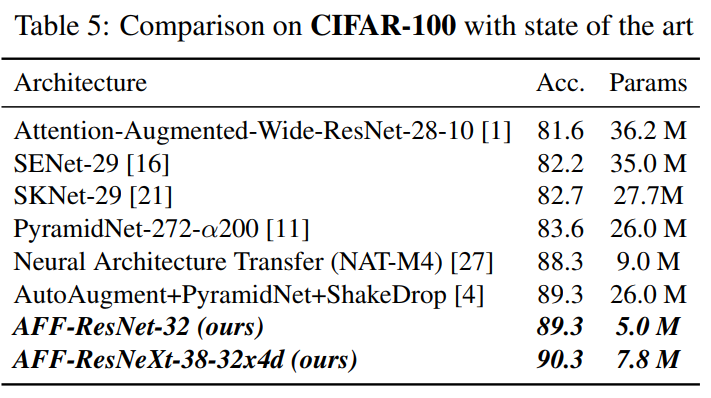
以下是基于ImageNet进行的实验: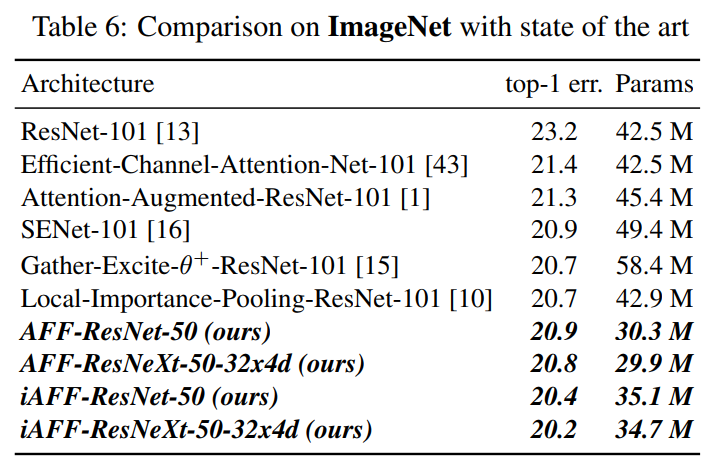
以下是Heatmap的输出图,可以看出该方法的注意力的聚焦更加的集中和突出重点: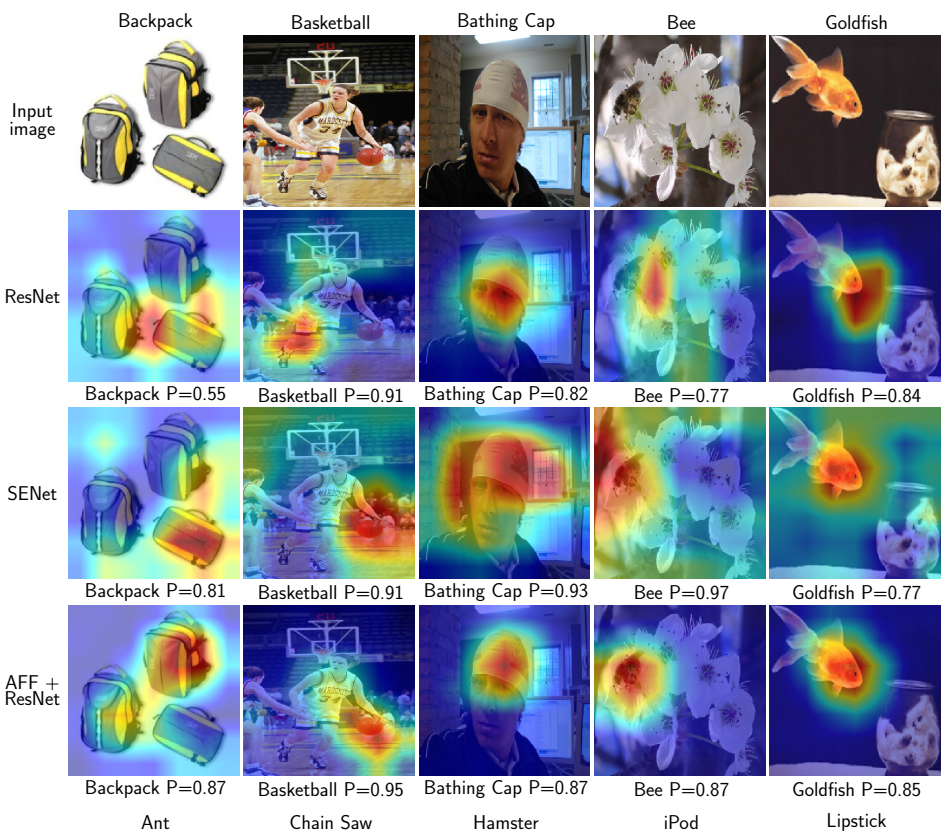

更多详细信息,可以参考论文原文:链接如下:
https://arxiv.org/abs/2009.14082
https://github.com/YimianDai/open-aff
参考:
[1].Attentional Feature Fusion
END
在【机器视觉CV】公众号后台回复 CPP,获取 CPP 开发手册

下载 2
在【机器视觉CV】公众号后台回复
YOLO 获取 YOLO 权重,回复 深度学习 获取学习资源,回复 表情识别 获取表情识别实战项目
机器视觉 CV
与你分享 AI 和 CV 的乐趣
分享数据集、电子书、免费GPU
长按二维码关注我们