
用于手语识别的自注意力机制
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


提出了一种用于连续手语识别的注意网络。该方法利用相互独立的数据流对手语模态进行建模。这些不同的信息渠道可以在彼此之间共享一个复杂的时间结构。出于这个原因,我们将注意力应用于同步,并帮助捕获不同符号语言组件之间的相互依赖关系。尽管手语是多通道的,但手形是手语解释的中心实体。在正确的语境中看到手形可以定义符号的含义。考虑到这一点,我们利用注意机制来有效地聚合具有适当时空背景的手部特征,从而更好地进行符号识别。我们发现,通过这样做,该模型能够识别围绕支配手和面部区域的基本手语成分。我们在rth - phoenix - weather 2014基准数据集上测试了我们的模型,得出了竞争结果。
本文提出了一种基于注意的序列符号语言比对识别方法。与以前的作品不同,我们的方法的独创性在于明确地从非手工手语组件中提取和聚合上下文信息。在没有任何领域注释的情况下,我们的方法能够在预测手势时独家识别与手势形状相关的最相关的特征。本文的主要贡献可以总结如下:
设计一个端到端的序列符号语言识别框架,利用自我注意进行时间建模。
阐述了一种更有效的方法,将手形与它们的时空背景结合起来进行手语识别。
在rth - phoenix - weather 2014基准数据集上,在单词错误率方面取得有竞争力的结果。
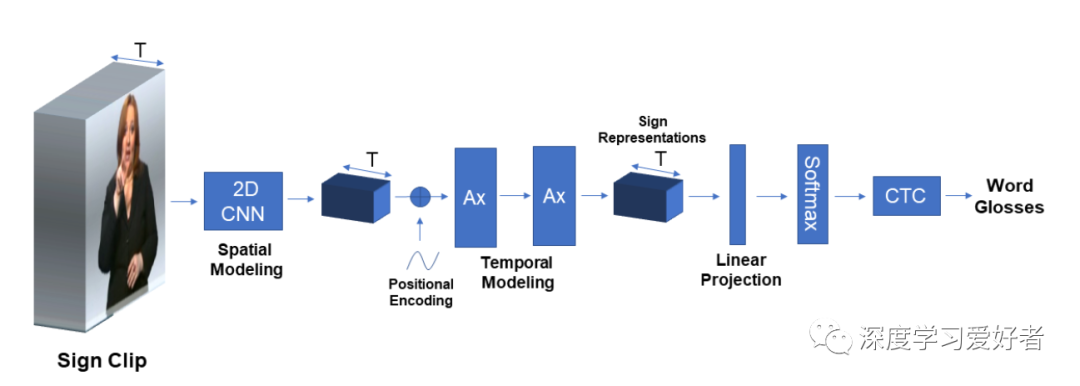
我们的注意网络的概述,采取一系列的全帧图像,并输出目标词的注释。Ax单元代表了[13]中引入的注意堆栈,它由一个多头自注意机制和一个全连接层组成。我们应用一个层范数[28],然后每个都有一个残差连接,而不是原始的论文中的结构。
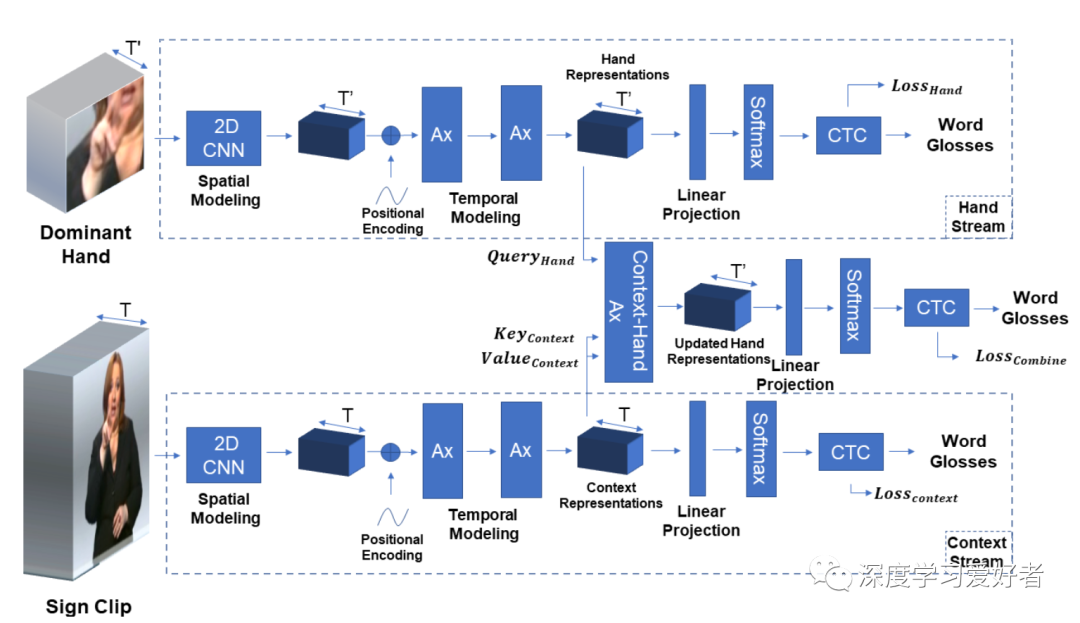
全帧和手形的组合通过上下文-手的注意层。

在框架嵌入激活的热图定位,突出模型用来预测特定标志的重要区域。上面的序列是我们的SAN网络的输出结果。中间是带有手持式流的SAN,底部是带有手持式流和本地上下文屏蔽的SAN。注意,这个示例是随机选择的,而不是精心挑选的。
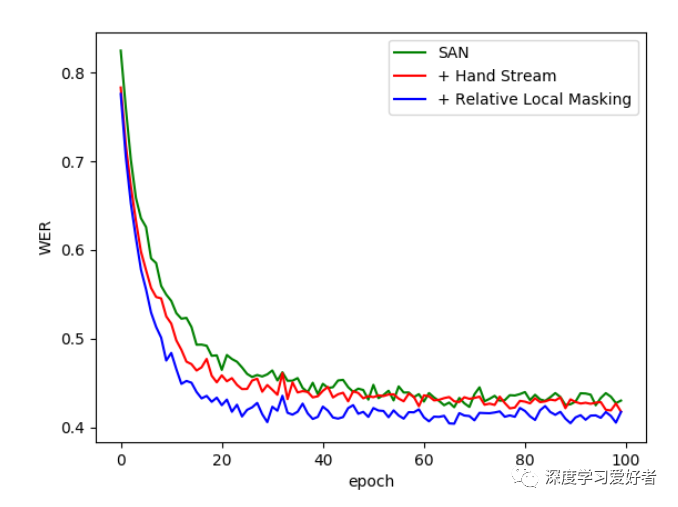
在RWTH-PHOENIX-Weather数据集上,我们的SAN变量用于CSLR任务的单词错误率学习曲线。
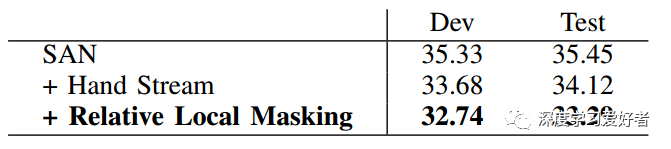
RWTH-PHOENIX-WEATHER 2014符号注意网络变体的单词错误率%比较(越低越好)
在这项工作中,我们提出了一种新的方法,利用注意力来有效地结合手部查询特征和它们各自的时间全身上下文,而不需要任何额外的监督。我们已经证明了这种方法对连续手语识别任务的有效性。在未来的研究中,我们将有兴趣研究在我们的架构上使用强制对齐算法的效果,类似于[7],[16]。如[7]所示,依靠强制对齐可以显著改善识别,它是一种流行的解决方案,通过迭代地改进和训练标签-图像预测来克服薄弱的监督。我们也可以使用HMMs代替CTC进行序列比对,因为他们已经被证明在[10]中更优。另一个重要的探索地点是进一步扩展这项工作,通过将我们的架构应用于类似于[12]和[14]的手语翻译任务(SLT),并通过注意机制来研究将手部特征与其全局非手动上下文结合起来的效果
论文链接:https://arxiv.org/pdf/2101.04632.pdf

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~