
5分钟NLP:Python文本生成的Beam Search解码

来源:Deephub Imba 本文约800字,建议阅读5分钟 本文介绍了Python文本生成的Beam Search的解码。

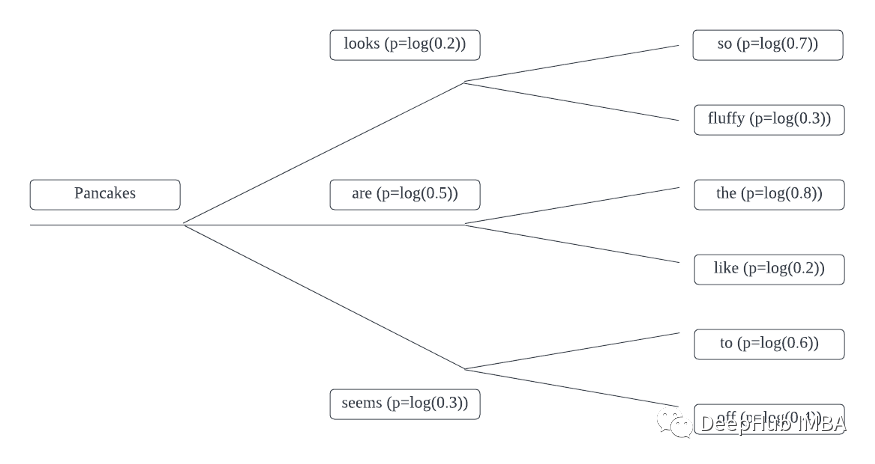
Pancakes looks so = log(0.2) + log(0.7)= -1.9Pancakes looks fluffy = log(0.2) + log(0.3)= -2.8
import torch.nn.functional as Fdef log_probability_single(logits, labels):logp = F.log_softmax(logits, dim=-1)logp_label = torch.gather(logp, 2, labels.unsqueeze(2)).squeeze(-1)return logp_labeldef sentence_logprob(model, labels, input_len=0):with torch.no_grad():result = model(labels)log_probability = log_probability_single(result.logits[:, :-1, :],:, 1:])sentence_log_prob = torch.sum(log_probability[:, input_len:])return sentence_log_prob.cpu().numpy()
input_sentence = "A love story, a mystery, a fantasy, a novel of self-discovery, a dystopia to rival George Orwell’s — 1Q84 is Haruki Murakami’s most ambitious undertaking yet: an instant best seller in his native Japan, and a tremendous feat of imagination from one of our most revered contemporary writers."max_sequence = 100input_ids = tokenizer(input_sentence,return_tensors='pt')['input_ids'].to(device)output = model.generate(input_ids, max_length=max_sequence, do_sample=False)greedy_search_output = sentence_logprob(model,output,input_len=len(input_ids[0]))print(tokenizer.decode(output[0]))

beam_search_output = model.generate(input_ids,max_length=max_sequence,num_beams=5,do_sample=False,no_repeat_ngram_size=2)beam_search_log_prob = sentence_logprob(model,beam_search_output,input_len=len(input_ids[0]))print(tokenizer.decode(beam_search_output[0])): {beam_search_log_prob:.2f}")

编辑:王菁
校对:林亦霖
评论