
【NLP】文本生成专题1:基础知识
大家好,好久不见,疫情封控在家两个月写文章都不利索了😂。
在这段时间我反思了一下之前写的东西,基本是最近用了什么、看到什么就写什么,感觉系统性比较差。后面我打算少写一些零散话题,多总结一些更有体系的内容。第一个小专题我想总结一下我最近关注比较多的领域,文本生成。文本生成领域很广泛,我主要会聚焦在文本摘要(Text Summarization)和数据驱动生成(Data2Text)。
这篇文章是第一篇,将介绍以下的内容:
问题定义和数据集
文本摘要
数据驱动生成
常用的评价指标
ROUGE
BLEU
目前的技术水平
后面的安排
除了第二部分外都比较像科普文,没有相关技术背景的朋友也可以看懂。
问题定义和数据集
文本摘要
摘要这个问题比较好理解,就是把长的文章,例如学术论文、新闻等等缩写成更短的文本,并且保留重要的信息。
摘要领域常见的典型数据集CNN/DailyMail[1], arXiv[2], Pubmed[3], XSUM[4]等。其中CNN/DailyMail的原始文本是大约几百个词的新闻,摘要(ground truth)是人写的,大概五六十个词。中间两个都是来自学术论文的数据集,原始文本比新闻长不少。学术论文通常都需要作者提供摘要,一般一百来个词,天然适合拿来做摘要的数据集。X-SUM是里面摘要长度最短的数据集,基本是一句话的长度。还有一些数据集,大家可以参考papwerswithcode[5]。

数据驱动生成
数据驱动生成则是给定一些结构化的数据,例如餐馆信息、实体间的关系等,生成一段自然语言。
这个领域典型的数据集有WebNLG[6]和E2E[7]。WebNLG的每条样本会提供一系列用三元组描述的实体及关系,以及一段陈述三元组表达事实的自然语言文本作为标签。

E2E数据集则提供了成对的餐馆结构化信息和自然语言描述。自然语言描述相比于WebNLG数据集更简短一些。更多数据集大家参考这个页面[8]。

常用的评价指标
除了数据集,要理解一个技术的发展水平,另一个很重要的方面是理解评价指标。评价机器生成的文本,最常用的指标是ROUGE和BLEU。
ROUGE
摘要里最常用的指标是ROUGE,它的全称是Recall-Oriented Understudy for Gisting Evaluation,是在2004年的论文ROUGE: A Package for Automatic Evaluation of Summaries[9]里提出的。从名字可以看出来它比较关注recall。它有很多形式,在论文里比较常看到的有ROUGE-N(N=1,2,3...)和ROUGE-L两种。
对于ROUGE-N,计算方式就是生成结果和参考文本中都出现的ngram占参考文本ngram的比例。ROUGE-L比较麻烦,需要考虑最长公共子串,但相比于预设ngram大小的ROUGE-N有一定的优势。单句的ROUGE-L是最长子串长度除以参考句的长度,举一个论文里的例子
S1. police killed the gunman S2. police kill the gunman S3. the gunman kill police
假设S1是参考句,那S2和S3的ROUGE-2都是1/3(匹配上了the gunman),但S2的ROUGE-L是3/4比S3的2/4大,实际情况确实是S2更好一些。
可以看出ROUGE,特别是ROUGE-N是比较考察和参考文本用词的一致性的,理论上不是个语义上的评价,这也和后面会写到的一些trick有直接的关联。
ROUGE指标的python实现可以参考这个repo[7],看代码应该是是最清楚的。
BLEU
在Data2Text领域常用的指标是BLEU,全称是bilingual evaluation understudy,从名字也能看出来,最开始是在机器翻译的评价里使用。BLEU像是一个precision指标,基本是在算生成结果和参考文本都出现的ngram和参考文本长度的比值。主要考虑的问题是多次匹配,例如
candidate:ha ha ha reference: only saying ha is not good
candidate只有一种词,且在标签中出现了,但若BLEU是100分,显然是不合理的。因为ha在reference中只出现一次,所以只能匹配一次,所以BLEU是1/3。
另一个要解决的问题是防止candidate过短而导致的高分。因为precision的分母是自己ngram的数目,只输出有把握的词是可以提高分数的。这里引入了一个叫brevity penalty的参数。这个参数的计算公式如下:
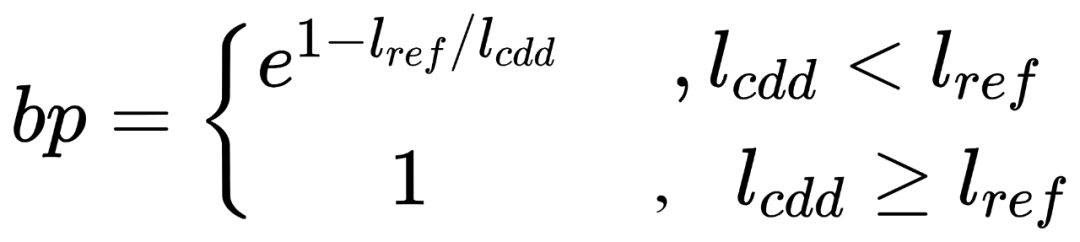
确定n 统计每种n-gram在reference和candidate中的出现次数,reference中出现次数后面作为匹配数的上限 对于candidate中的每种n-gram,计算匹配次数, 计算BLEU-N, 用几何平均计算综合得分,,通常k为4
目前的技术水平
首先我想说通过ngram的召回或准确率去评价文本生成的水平是一个非最优但比较有效的方式。指标的小幅提升并不能说明产出的文本真的有与之对应的肉眼可见的质量变化。
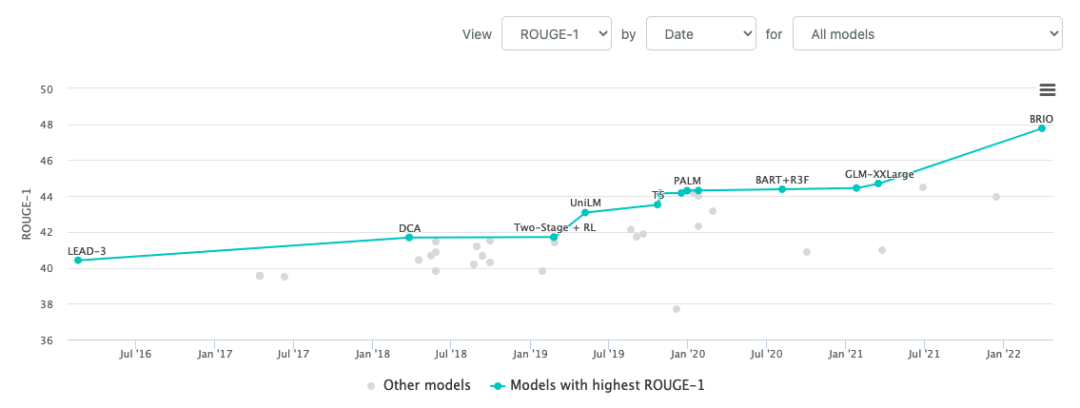
我们可以从papwerswithcode上看到近几年在上述的几个典型数据集模型表现的变化。下图是CNN/DailyMail数据集从16年到现在的SOTA变化图[8],拉长时间看,这五年多来的提升还是非常明显的。绝对值上看,不到50%的召回率似乎不尽如人意,但实际使用下来其实还是不错的,大家可以看后面的例子。分数低的主要原因还是段落长度的文字自由度实在太高了。
我们可以再去huggingface上体验一下实际的模型能力。我们选用如下一个同样的文本,来生成摘要
The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct.
2019年问世的BART模型得出的摘要如下,这个模型在数据集上的ROUGE-1得分是44.16:
The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world.
2022年ACL新鲜出炉的SOTA模型BRIO[9]得出的摘要如下,这个模型在数据集上的ROUGE-1得分是47.78:
The Eiffel Tower is 324 metres tall and the tallest structure in Paris. The tower is the same height as an 81-storey building. It was the tallest man-made structure in the world until the Chrysler Building in 1930. It is the second tallest free-standing structure in France after the Millau Viaduct.
可以看到,两个摘要都挺流畅,除了前面两句比较像,到后面两个模型的关注点就有点分叉了,BART更关注原文的开头部分,BRIO还带到了结尾的信息,但就这个例子看很难说哪个好。
我觉得这个领域很有意思的一点是它并没有像NLP的其他领域一样,被大规模预训练语言模型一下拉高SOTA的水平。对于其原因,我也没想明白,但我倾向于归因于问题的自由度太高了,长文本摘要本没有标准答案。从技术角度讲,对于摘要这种技术ROUGE这种评价体系可能已经不适用了;而对于从业者,关注这个技术如何落地比刷排行榜上的几个点可能更重要得多。
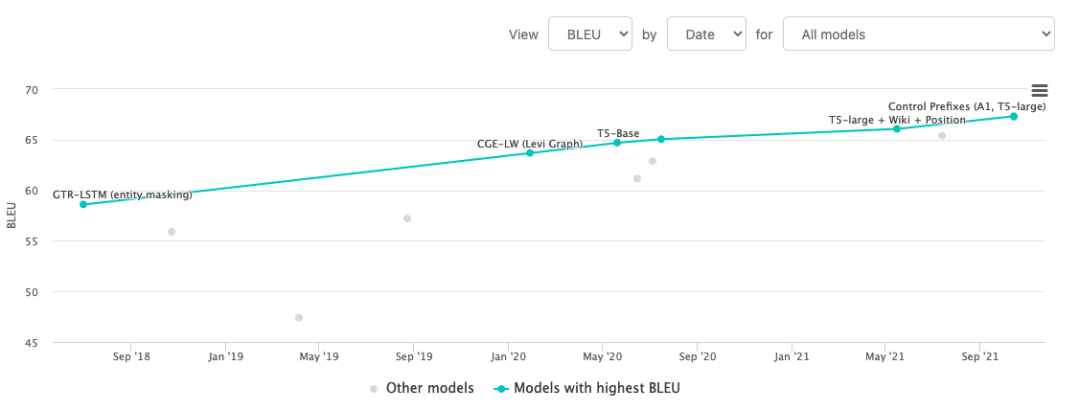
看WebNLG的话这几年的进步更大一些,如下图[10]所示,BLEU涨了快十个点
后面的安排
这篇文章算是开头,后面我打算用几篇文章分别总结下这几个方面的学习成果:
摘要生成的主流算法框架,包括抽取式、生成式和一些结合两种框架的方法,以及一些刷榜的方法 摘要生成中长文本的处理方法 数据驱动生成的主流算法框架
如果你对这些话题感兴趣,可以关注这个公众号,及时获得更新。
参考资料
CNN/DailyMail: https://github.com/abisee/cnn-dailymail
[2]arXiv: https://snap.stanford.edu/data/cit-HepTh.html
[3]Pubmed: https://linqs.soe.ucsc.edu/data
[4]XSUM: https://github.com/EdinburghNLP/XSum/tree/master/XSum-Dataset
[5]文本摘要数据集: https://paperswithcode.com/task/text-summarization
[6]WebNLG: https://aclanthology.org/P17-1017.pdf
[7]E2E: https://arxiv.org/pdf/1706.09254v2.pdf
[8]数据驱动生成数据集: https://paperswithcode.com/task/data-to-text-generation
[9]ROUGE: A Package for Automatic Evaluation of Summaries: https://aclanthology.org/W04-1013/
[10]ROUGE in Python: https://github.com/pltrdy/rouge
[11]CNN/DailyMail SOTA变化图: https://paperswithcode.com/sota/abstractive-text-summarization-on-cnn-daily
[12]BRIO: Bringing Order to Abstractive Summarization: https://arxiv.org/abs/2203.16804v1
[13]WebNLG近年SOTA变化情况: https://paperswithcode.com/sota/data-to-text-generation-on-webnlg,