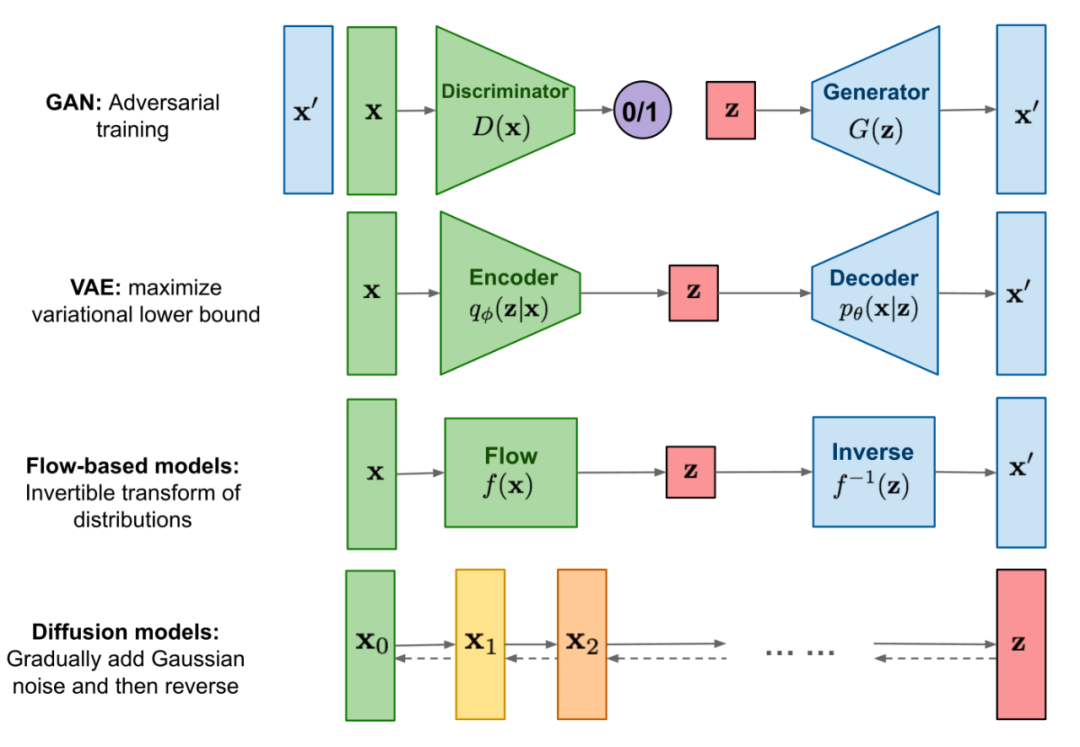
文本生成图像的技术演变
目前多模态任务成为行业热点,本文梳理了较为优秀的多模态文本图像模型:DALL·E、CLIP、GLIDE、DALL·E 2 (unCLIP)的模型框架、优缺点,及其迭代关系。


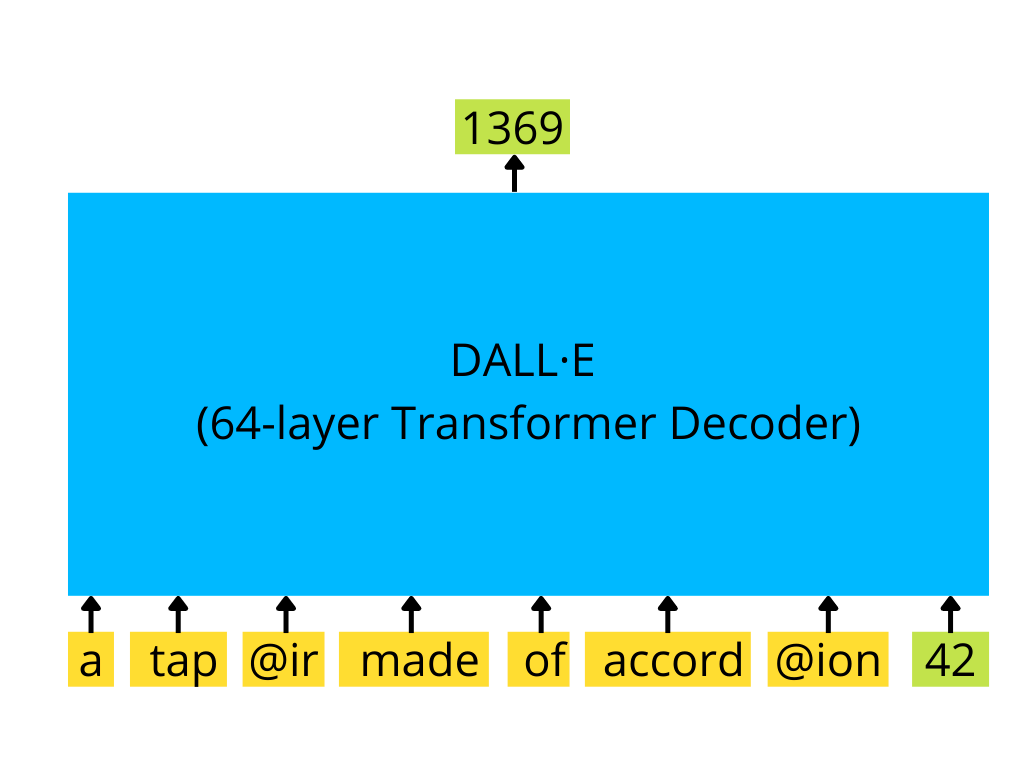

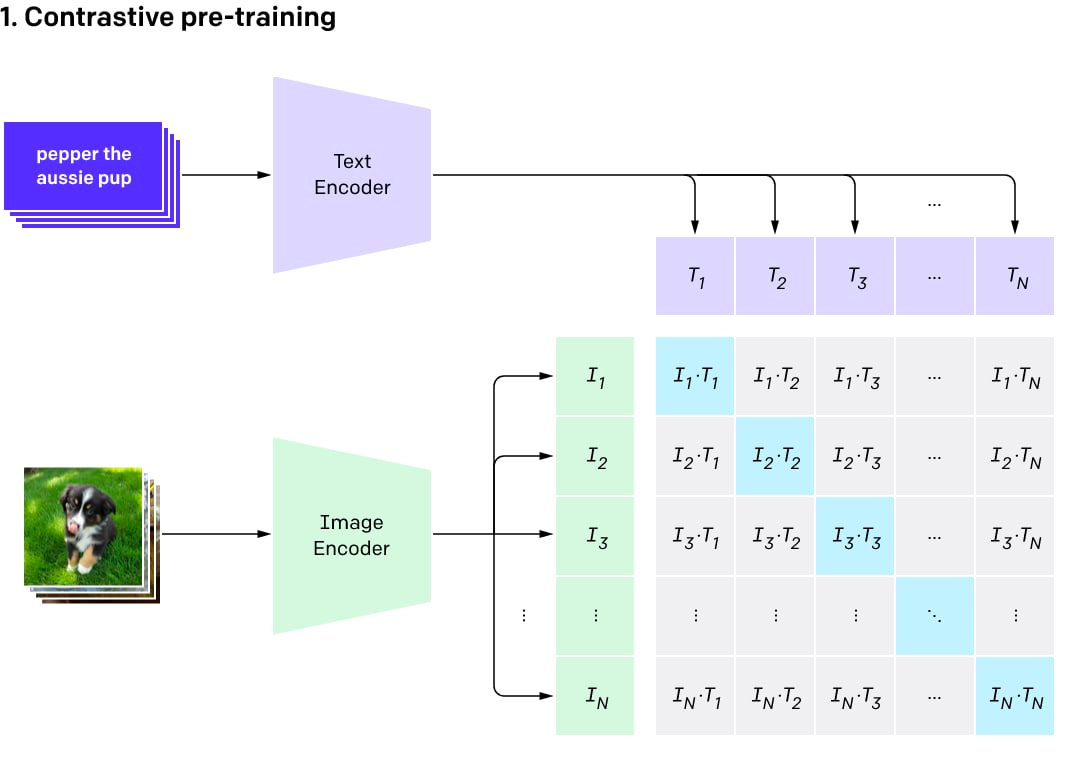
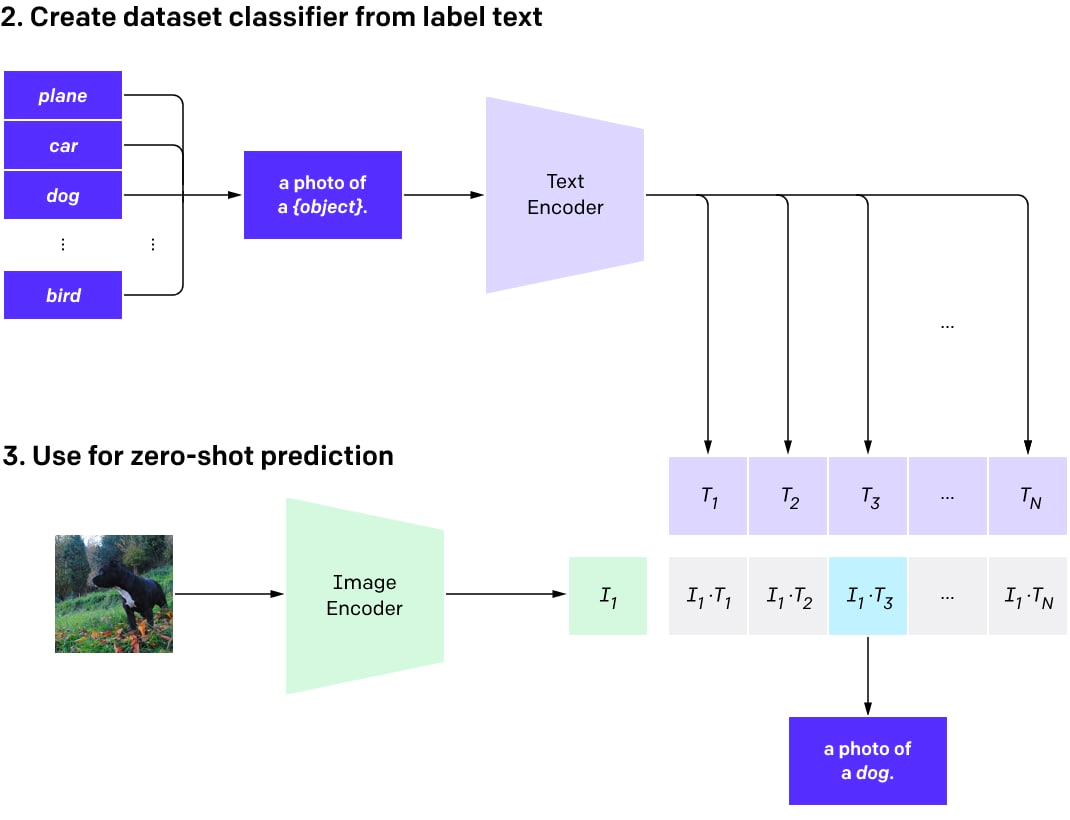



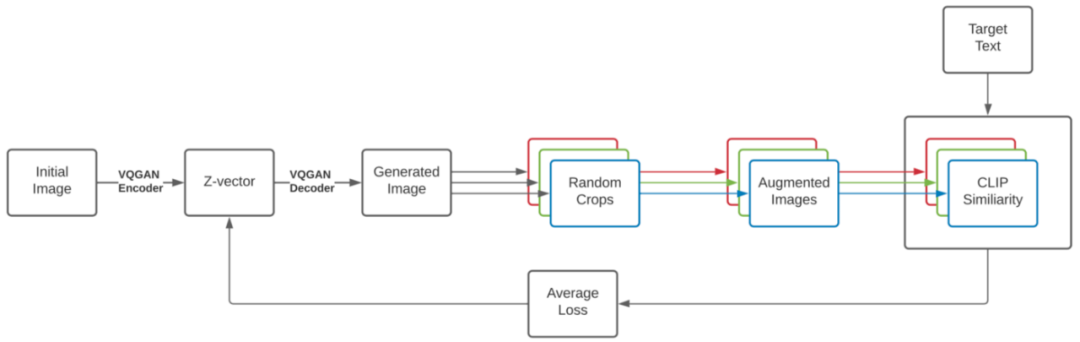










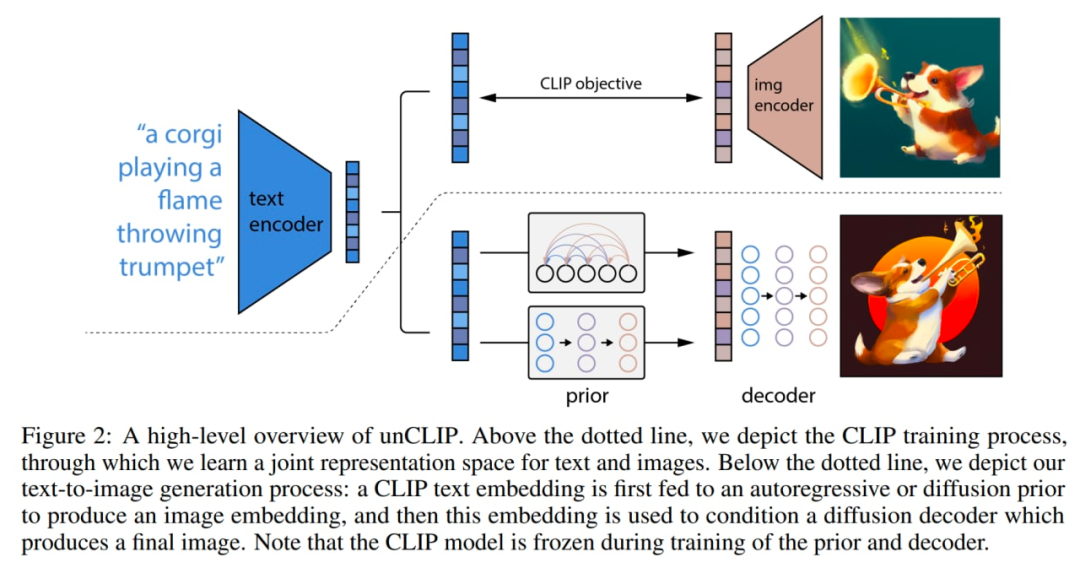
编码的文本
CLIP 文本嵌入
扩散时间步长的嵌入
噪声 CLIP 图像嵌入
最终的嵌入,其来自 Transformer 的输出用于预测无噪声 CLIP 图像嵌入。








猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》
评论
 下载APP
下载APP目前多模态任务成为行业热点,本文梳理了较为优秀的多模态文本图像模型:DALL·E、CLIP、GLIDE、DALL·E 2 (unCLIP)的模型框架、优缺点,及其迭代关系。
编码的文本
CLIP 文本嵌入
扩散时间步长的嵌入
噪声 CLIP 图像嵌入
最终的嵌入,其来自 Transformer 的输出用于预测无噪声 CLIP 图像嵌入。
猜您喜欢:
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》