
Pandas处理时间序列的数据
import pandas as pdimport numpy as npfrom datetime import datetimepd.to_datetime('2021-05-20') ##output: Timestamp('2021-05-20 00:00:00')pd.Timestamp('2021-05-20') ##output: Timestamp('2021-05-20 00:00:00')
a = pd.Timestamp('2021-10-01')a.day_name() ## Friday,看来今年的10月1日是周五哈?a.month_name() ## October 十月份a.day(), a.month(), a.year() ## 1, 10, 2021,查看年月日等信息
df = pd.DataFrame({"time_frame": ["2021-01-01", "2021-01-02", "2021-01-03", "2021-01-04", "2021-01-05"]})df['time_frame'] = pd.to_datetime(df['time_frame'])
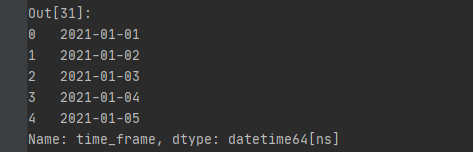
date_string = [str(x) for x in df['time_frame'].tolist()]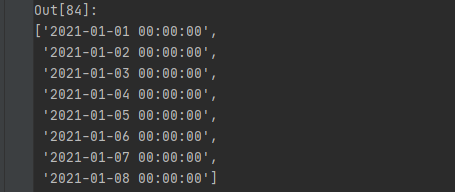
time_string = ['2021-02-14 00:00:00', '2021-02-14 01:00:00', '2021-02-14 02:00:00', '2021-02-14 03:00:00', '2021-02-14 04:00:00', '2021-02-14 05:00:00', '2021-02-14 06:00:00']pd.to_datetime(time_string, infer_datetime_format = True)

import datetimetext_1 = "2021-02-14"datetime.datetime.strptime(text_1, '%Y-%m-%d')
l求某个日期对应的星期数(2021-06-22是第几周)
l判断一个日期是周几(2021-02-14是周几)
l判断某一日期是第几季度,等等
df = pd.DataFrame({"time_frame": ["2021-01-01", "2021-01-02", "2021-01-03", "2021-01-04", "2021-01-05", "2021-01-06", "2021-01-07", "2021-01-08"]})df["time_frame"] = pd.to_datetime(df["time_frame"])# 一周中的第几天df.time_frame.dt.dayofweek[0]# 返回对应额日期df.time_frame.dt.date[0]# 返回一周中的第几天,0对应周一,1对应周二df.time_frame.dt.weekday[0]
pd.date_range(start='2021-02-14', periods=10, freq='M')
pd.period_range('2021', periods=10, freq='M')
pd.timedelta_range(start='0', periods=24, freq='H')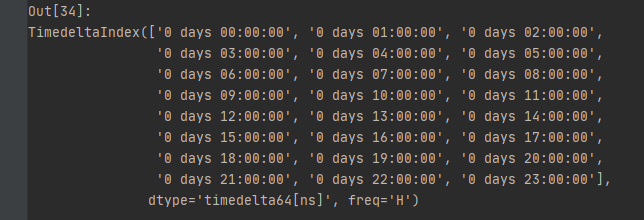
A = pd.date_range('2021-01-01', periods=30, freq='D')values = np.random.randint(10, size=30)S = pd.Series(values, index=A)
S.resample('5D').sum()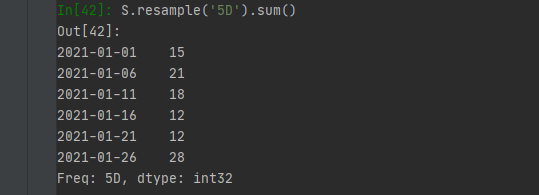
index = pd.date_range('2021-01-01',periods=30)data = pd.DataFrame(np.arange(len(index)),index=index,columns=['test'])
主要有“rolling”方法和“expanding”方法,“rolling”方法考虑的是一定的时间段内的数据,而“expanding”考虑的则是之前所有的数据,例如
# 移动3个值,进行求和data['sum'] = data.test.rolling(3).sum()# 移动3个值,进行求平均数data['mean'] = data.test.rolling(3).mean()
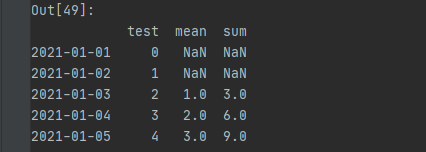
data['mean'].fillna(method = 'backfill')
相关阅读:
评论