
Python数据分析实战:用Pandas 处理时间序列
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
pjme_file = 'data/PJME_hourly.csv'
pjmw_file = 'data/PJMW_hourly.csv'
df_1 = pd.read_csv(pjme_file)
df_2 = pd.read_csv(pjmw_file)
print(df_1.info())
print(df_2.info())
RangeIndex: 145366 entries, 0 to 145365
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Datetime 145366 non-null object
1 PJME_MW 145366 non-null float64
dtypes: float64(1), object(1)
memory usage: 2.2+ MB
None
RangeIndex: 143206 entries, 0 to 143205
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Datetime 143206 non-null object
1 PJMW_MW 143206 non-null float64
dtypes: float64(1), object(1)
memory usage: 2.2+ MB
None
print(df_1['Datetime'].describe())
count 145366
unique 145362
top 2015-11-01 02:00:00
freq 2
df_1['Datetime'] = pd.to_datetime(df_1['Datetime'],format='%Y-%m-%d %H:%M:%S')
print(df_1['Datetime'].describe())
count 145366
unique 145362
top 2014-11-02 02:00:00
freq 2
first 2002-01-01 01:00:00
last 2018-08-03 00:00:00
Name: Datetime, dtype: object
Datetime PJME_MW
0 2002-12-31 01:00:00 26498.0
1 2002-12-31 02:00:00 25147.0
2 2002-12-31 03:00:00 24574.0
3 2002-12-31 04:00:00 24393.0
4 2002-12-31 05:00:00 24860.0
出现重复的时间戳及样本,需要我们移除
样本排序混乱
其实该数据集是单纯的重复类型,保留第一个,最后一个,或者求均值,结果是一致的
重要的是想展示一个pivot_table的用法。
df_1 = pd.pivot_table(data=df_1,values='PJME_MW',index='Datetime',aggfunc='mean').reset_index()
df_1.sort_values(by='Datetime',inplace=True)
df_1.set_index('Datetime',inplace=True)
# plot data
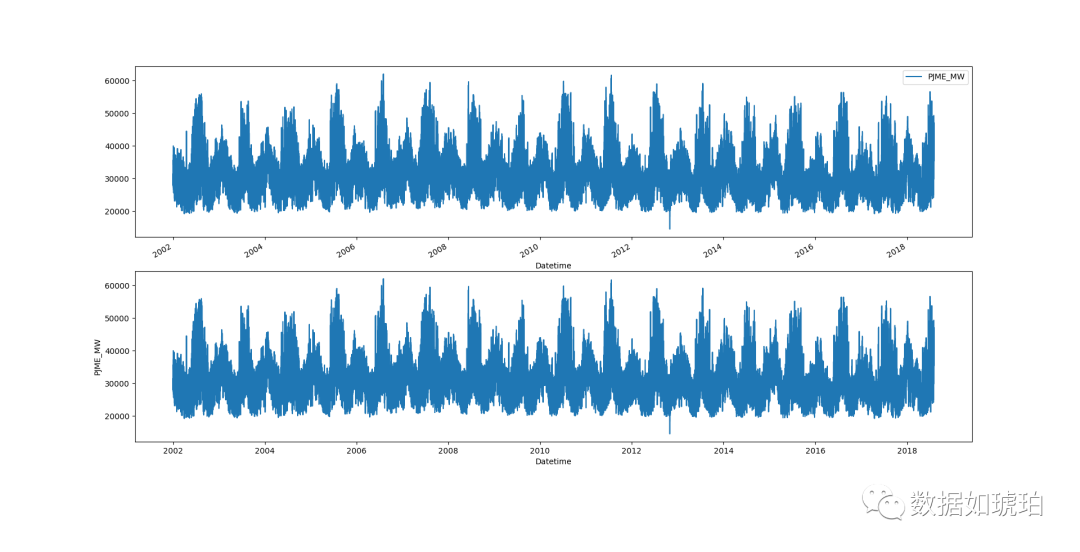
fig,ax = plt.subplots(2,1)
df_1.plot(ax =ax[0])
sns.lineplot(data=df_1,x=df_1.index,y='PJME_MW',ax=ax[1])
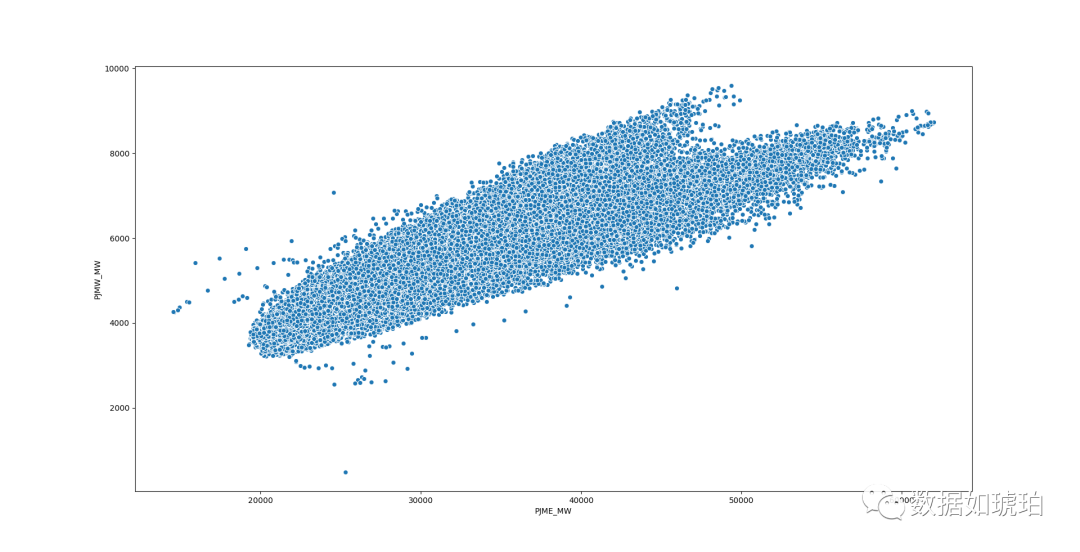
df = pd.concat([df_1,df_2],axis=1)
sns.scatterplot(x='PJME_MW',y='PJMW_MW',data=df)
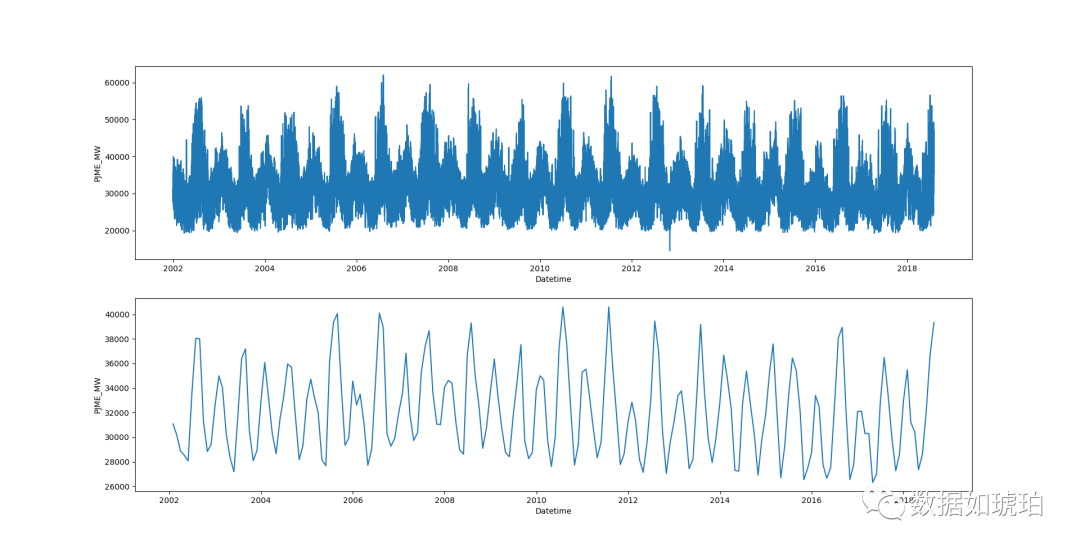
# resample data
day_df = df_1.resample(rule='D').mean()
week_df = df_1.resample(rule='W').mean()
month_df = df_1.resample(rule='M').mean()
quarter_df = df_1.resample(rule='Q').mean()
year_df = df_1.resample(rule='Y').mean()
print(month_df.info())
fig,ax = plt.subplots(2,1)
sns.lineplot(data=df_1,x=df_1.index,y='PJME_MW',ax=ax[0])
sns.lineplot(data=month_df,x=month_df.index,y='PJME_MW',ax=ax[1])
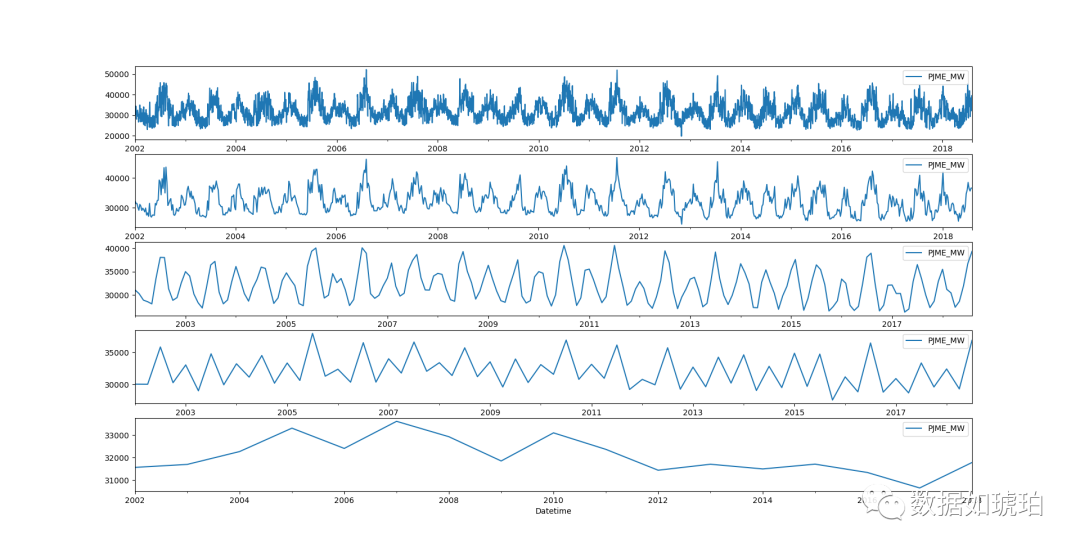
num_ax = 5
fig,ax = plt.subplots(num_ax,1)
#[ax[i].set_ylim(10000,22000) for i in range(num_ax)]
day_df.plot(ax=ax[0])
week_df.plot(ax=ax[1])
month_df.plot(ax=ax[2])
quarter_df.plot(ax=ax[3])
year_df.plot(ax=ax[4])
month_sum_df = df_1.resample(rule='M').sum()
DataFrame数据用时间戳作为索引,最大的好处是可以快速对样本进行索引和切片。进行索引和切片时,不一定需要完全匹配时间戳的格式,比如,你可以快速索引某个年度的所有样本。
print(day_df.loc['2014-02-12']) #获得某一天的样本
print(day_df['2015']) #获得某一年的额样本
print(day_df['2014-02-12':'2014-02-19']) #获取某个时间段
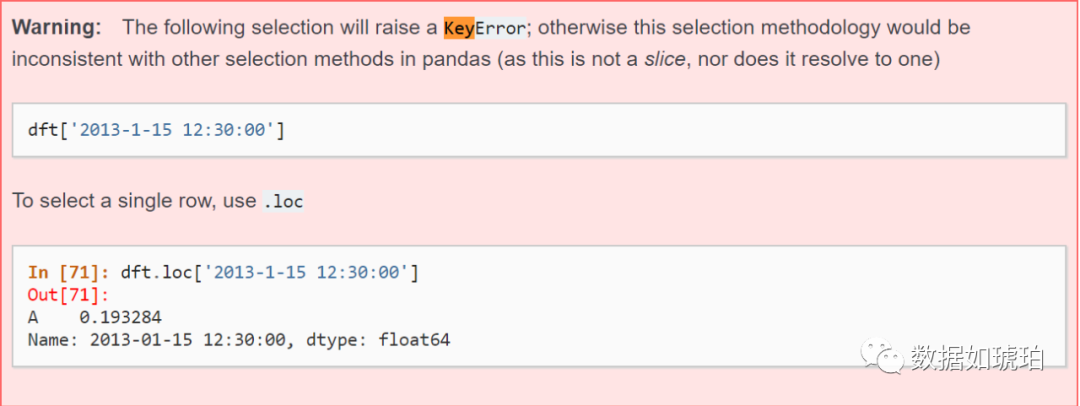
#print(day_df['2014-02-12']) !!!这是错误示例
print(month_df.asof('2014-02')) #获取某一月
#print(day_df['2014-02-12']) !!!这是错误示例。因为day_df的每一天只有一个样本,此时只有iloc可以进行索引。详细的解释参考如下。
时间信息的提取
基于时间窗口的时域统计
基于时间窗口的频域统计
# get more datetime attributes
df_1['day']= df_1.index.day # means which day in this month
df_1['dayofweek']= df_1.index.dayofweek
df_1['dayofyear']= df_1.index.dayofyear
df_1['days_in_month']= df_1.index.days_in_month # how many days in this month
df_1['daysinmonth']= df_1.index.daysinmonth # same as days_in_month
df_1['is_month_end']= df_1.index.is_month_end
df_1['is_month_start']= df_1.index.is_month_start
df_1['is_quarter_start']= df_1.index.is_quarter_start
df_1['is_quarter_end']= df_1.index.is_quarter_end
df_1['month']= df_1.index.month
df_1['week']= df_1.index.week
df_1['weekofyear']= df_1.index.weekofyear # same as week
df_1['year']= df_1.index.year
df_1['date']= df_1.index.date
df_1['time']= df_1.index.time
df_1['window_mean']= df_1['PJME_MW'].rolling(window=24,center=True).mean() # it will generate null
print(df_1.head(24))
PJME_MW window_mean
Datetime
2002-01-01 01:00:00 30393.0 NaN
2002-01-01 02:00:00 29265.0 NaN
2002-01-01 03:00:00 28357.0 NaN
2002-01-01 04:00:00 27899.0 NaN
2002-01-01 05:00:00 28057.0 NaN
2002-01-01 06:00:00 28654.0 NaN
2002-01-01 07:00:00 29308.0 NaN
2002-01-01 08:00:00 29595.0 NaN
2002-01-01 09:00:00 29943.0 NaN
2002-01-01 10:00:00 30692.0 NaN
2002-01-01 11:00:00 31395.0 NaN
2002-01-01 12:00:00 31496.0 NaN
2002-01-01 13:00:00 31031.0 31017.500000
2002-01-01 14:00:00 30360.0 30922.833333
2002-01-01 15:00:00 29798.0 30846.666667
2002-01-01 16:00:00 29720.0 30802.666667
2002-01-01 17:00:00 31271.0 30787.416667
2002-01-01 18:00:00 35103.0 30801.916667
2002-01-01 19:00:00 35732.0 30889.166667
2002-01-01 20:00:00 35639.0 31114.875000
2002-01-01 21:00:00 35285.0 31436.458333
2002-01-01 22:00:00 34007.0 31743.916667
2002-01-01 23:00:00 31857.0 32008.208333
2002-01-02 00:00:00 29563.0 32231.666667
↓扫描二维码添加好友↓ 推荐阅读
(点击标题可跳转阅读)
评论