
利用pandas处理Excel数据
新建一个excel表格(table1.csv)用于案例讲解:
导库
import pandas as pd
import numpy as np
读取数据
df = pd.read_excel('table1.xlsx') # 相对路径
# df = pd.read_excel(r'E:\Anaconda\hc\dataScience\table1.csv') # 绝对路径
显示数据
显示数据的行与列数
df.shape
(6, 5)
显示数据格式dtpyes
df.dtypes
Name object
Age int64
Sex int64
Class int64
Score float64
dtype: object
显示列名
df.columns
Index(['Name', 'Age', 'Sex', 'Class', 'Score'], dtype='object')
显示前数据前2行
df.head(2)

显示数据后3行
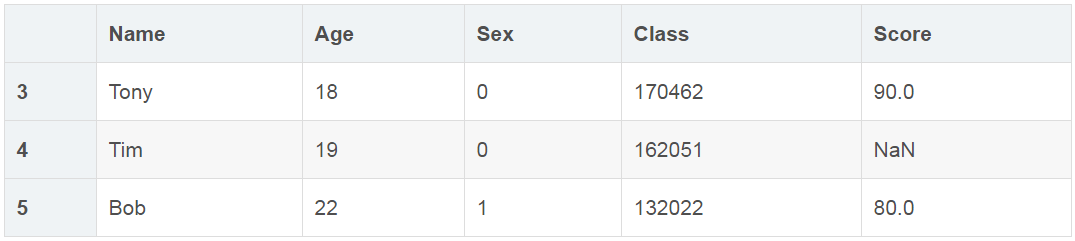
df.tail(3)
显示数据唯一值(unique函数)
df['Score'].unique()
array([ 80., 90., 100., nan])
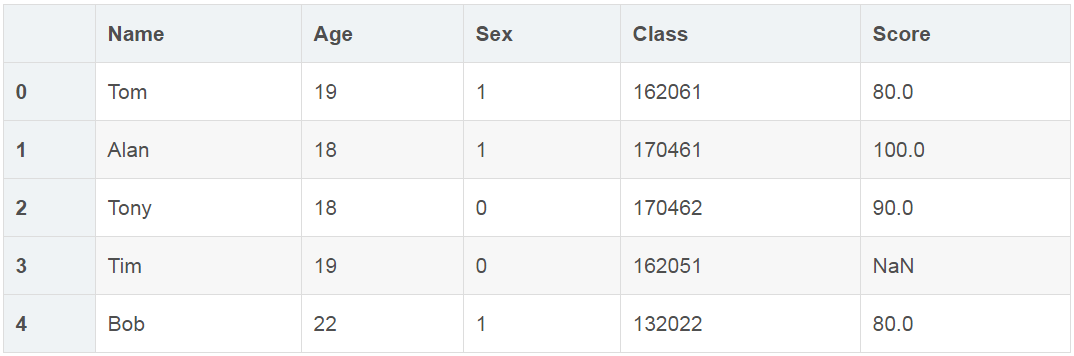
对第几行数据不读取
# 没有读取第2行
df1 = pd.read_excel('table1.csv',skiprows=[2] )
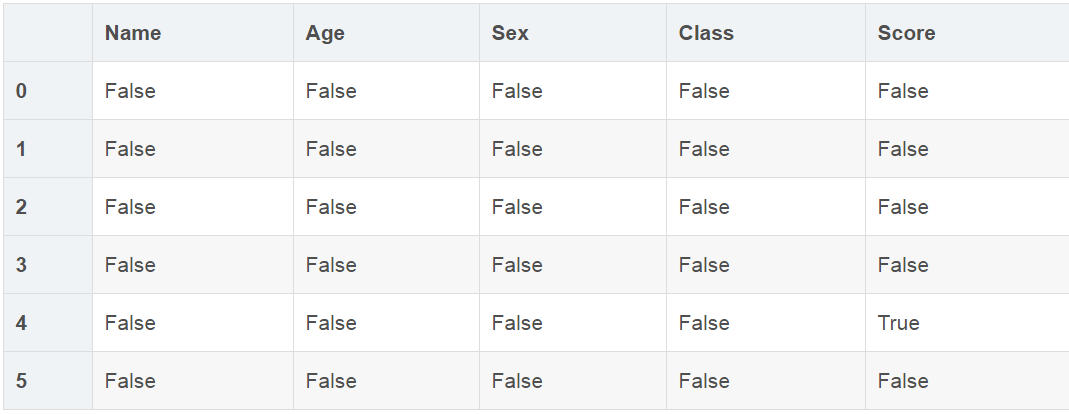
对缺失值进行识别
# 所有缺失值显示为True
df.isnull()
清洗数据
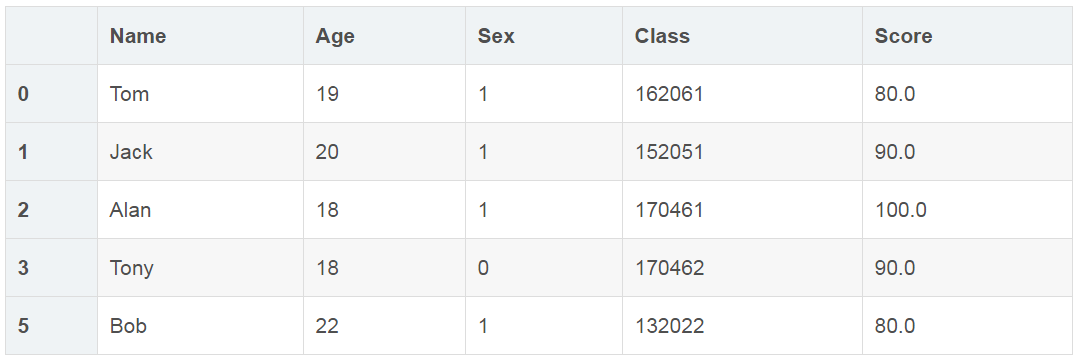
删除空值(dropna函数)
df2 = df.dropna(how='any')
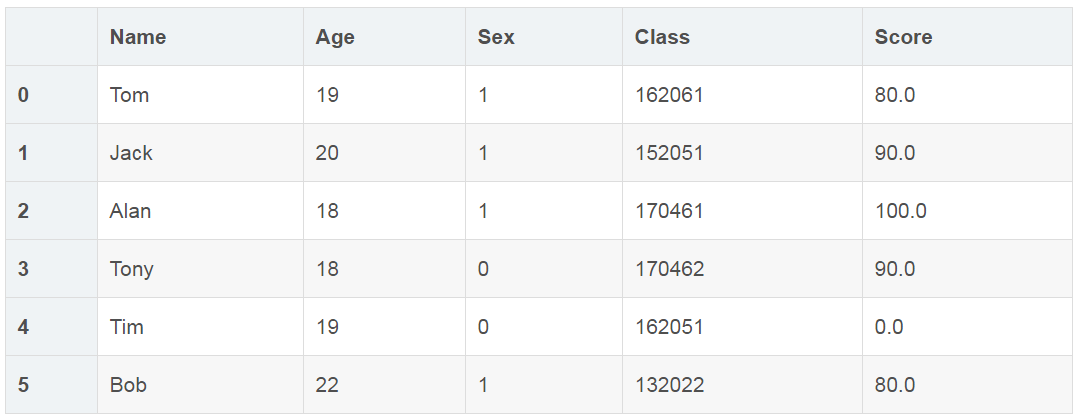
填充空值(fillna函数)
df3 = df.fillna(value=0)
用均值对空值进行填充
df4 = df['Score'].fillna(df['Score'].mean())
0 80.0
1 90.0
2 100.0
3 90.0
4 88.0
5 80.0
Name: Score, dtype: float64
更改数据格式
df1['Score'].astype('int64')
0 80
1 90
2 100
3 90
5 80
Name: Score, dtype: int64
(注:如果存在空值,更改数据格式会报错!)
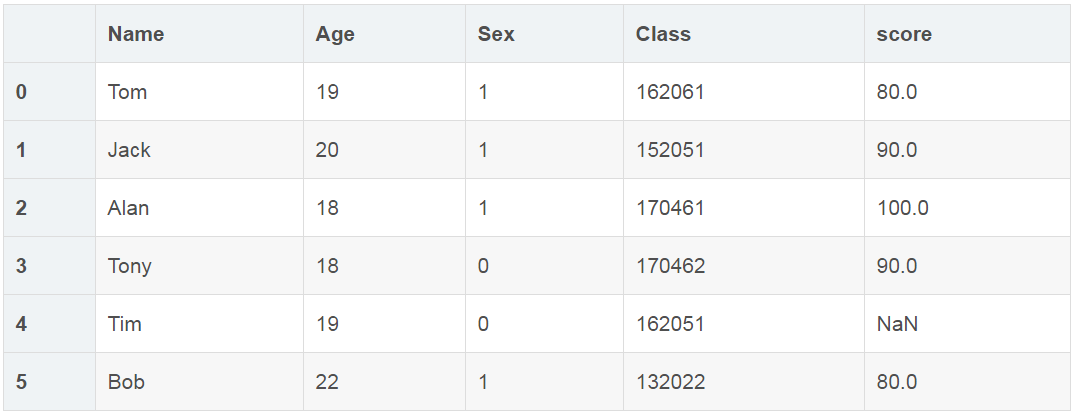
更改列名
df5 = df.rename(columns={'Score': 'score'})
对列表内的值进行替换(replace函数)
df6 = df['Name'].replace('Bob', 'bob')
0 Tom
1 Jack
2 Alan
3 Tony
4 Tim
5 bob
Name: Name, dtype: object
数据预处理
对数据进行排序
df.sort_values(by=['Score'])
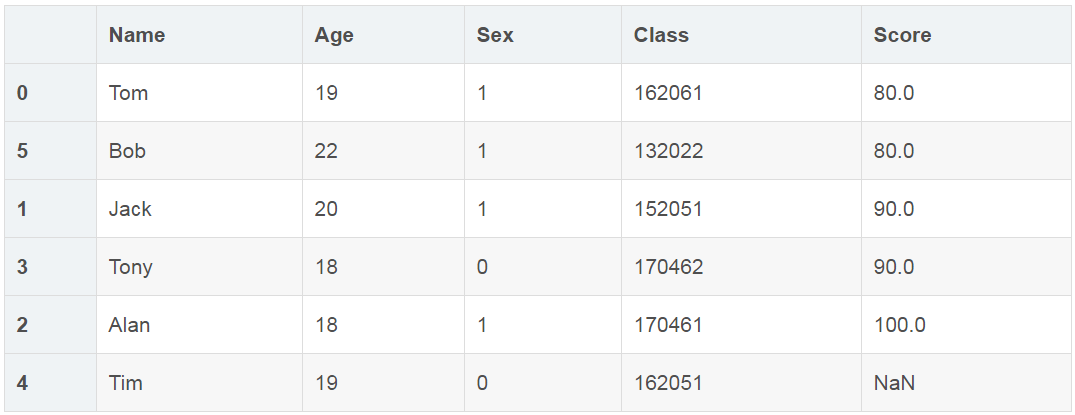
(注:默认升序,且空值在后面)
数据分组
①单一条件分组
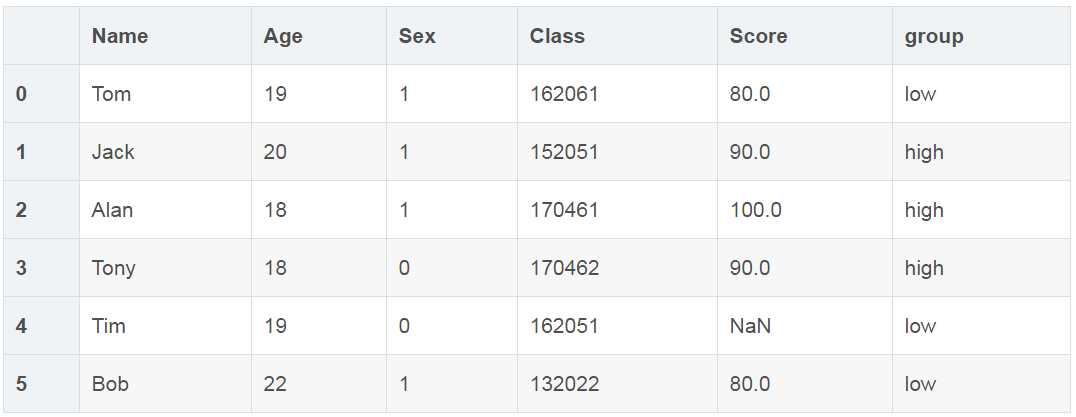
# 如果Score列的值>=85,Score列显示high,否则显示low
# group列为增加列
df['group'] = np.where(df['Score'] > 85,'high','low')
②多个条件分组
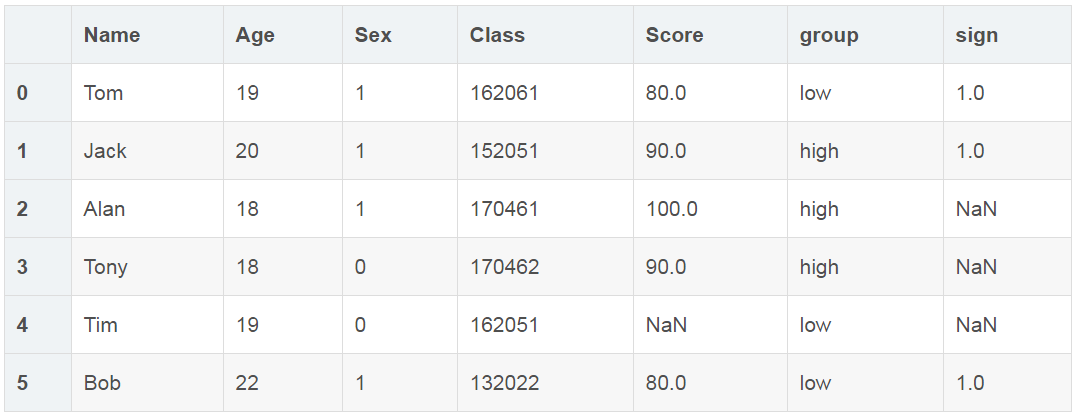
# 利用loc函数,进行多列查询
# sign为增加列
df.loc[(df['Sex'] == 1) & (df['Age']>= 19), 'sign']=1
数据提取
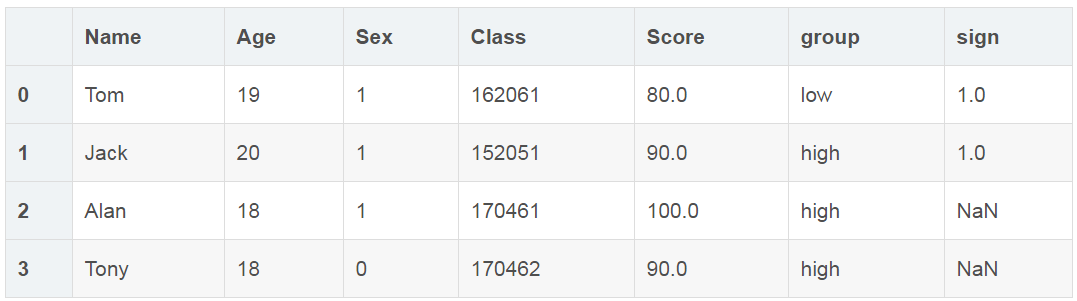
按标签提取(loc函数)
df.loc[0:3]
按位置进行提取(iloc函数)
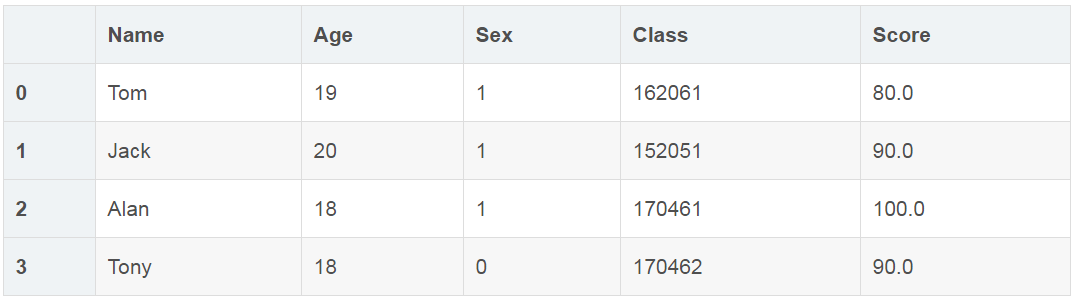
①按区域提取
df.iloc[:4, :5]
②按位置提取
#[0, 2, 5] 代表指定的行,[0, 1, 5] 代表指定的列
df.iloc[[0, 2, 5],[0, 1, 5]]
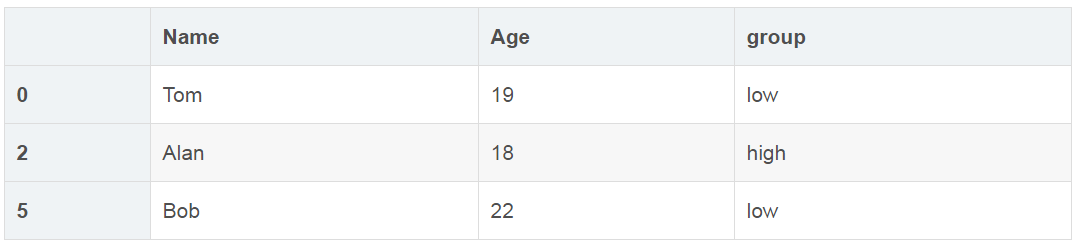
按条件提取(isin与loc函数)
①用isin函数进行判断
# 判断Sex是否为1
df['Sex'].isin([1])
0 True
1 True
2 True
3 False
4 False
5 True
Name: Sex, dtype: bool
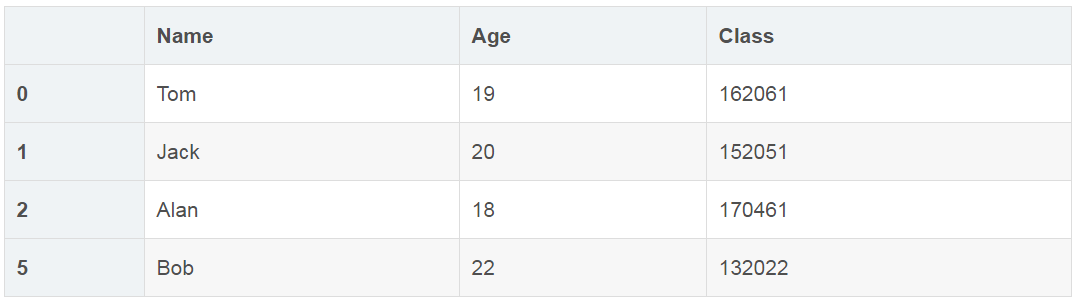
②用loc函数进行判断
# Sex为1,分数大于85
df1.loc[(df1['Sex'] == 1) & (df1['Score'] > '85'), ['Name','Age','Class']]
③先判断结果,将结果为True的提取
# 先判断Score列里是否包含80和90,然后将复合条件的数据提取出来。
df.loc[df['Score'].isin(['80','90'])]
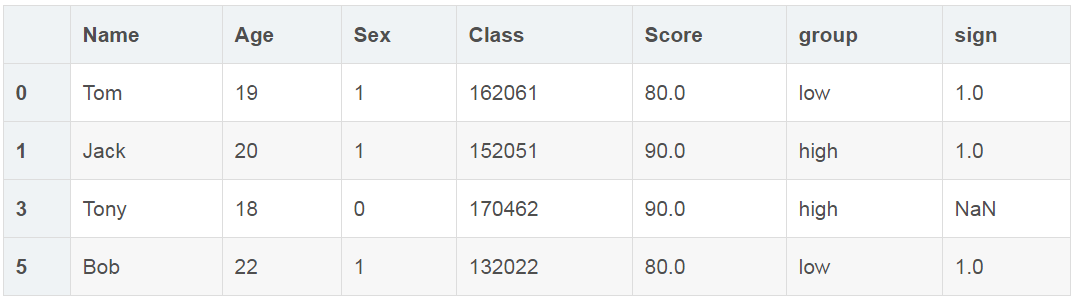
作者:AI阿聪
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/weixin_40431584/article/details/103993722
微信扫码关注,了解更多内容
评论