Pandas学习笔记之时间序列总结

早起导读:pandas是Python数据处理的利器,时间序列数据又是在很多场景中出现,本文来自GitHub,详细讲解了Python和Pandas中的时间及时间序列数据的处理方法与实战,建议收藏阅读。
关键词:pandas NumPy 时间序列
时间戳 代表着一个特定的时间点(例如 2015 年 7 月 4 日上午 7 点)。 时间间隔和周期 代表着从开始时间点到结束时间点之间的时间单位长度;例如 2015 一整年。周期通常代表一段特殊的时间间隔,每个时间间隔的长度都是统一的,彼此之间不重叠(例如一天由 24 个小时组成)。 时间差或持续时间代表这一段准确的时间长度(例如 22.56 秒持续时间)。
Python 中的日期和时间
Python 本身就带有很多有关日期、时间、时间差和间隔的表示方法。Pandas 提供的时间序列工具在数据科学领域会更加的强大,但是首先学习相关的 Python 的工具包会对我们理解它们更加有帮助。
原生 Python 日期和时间:datetime 和 dateutil
Python 最基础的日期和时间处理包就是datetime。如果加上第三方的dateutil模块,你就能迅速的对日期和时间进行许多有用的操作了。例如,你可以手动创建一个datetime对象:
from datetime import datetime
datetime(year=2015, month=7, day=4)
datetime.datetime(2015, 7, 4, 0, 0)
或者使用dateutil模块,你可以从许多不同的字符串格式中解析出datetime对象:
from dateutil import parser
date = parser.parse("4th of July, 2015")
date
datetime.datetime(2015, 7, 4, 0, 0)
获得datetime对象之后,你可以对它进行很多操作,包括输出这天是星期几:
date.strftime('%A')
'Saturday'
在上面的代码中,我们使用了标准的字符串格式化编码来打印日期("%A"),你可以在时间格式化在线文档中看到全部的说明。Python 的datetime在线文档可以参考datetime 文档。其他很有用的日期时间工具dateutil的文档可在dateutil 在线文档找到。还有一个值得注意的第三方包是pytz,用来处理最头痛的时间序列数据:时区。
datetime和dateutil的强大在于它们灵活而易懂的语法:你可以使用这些对象內建的方法就可以完成几乎所有你感兴趣的时间操作。但是当对付大量的日期时间组成的数组时,它们就无法胜任了:就像 Python 的列表和 NumPy 的类型数组对比一样,Python 的日期时间对象在这种情况下就无法与编码后的日期时间数组比较了。
时间的类型数组:NumPy 的 datetime64
Python 日期时间对象的弱点促使 NumPy 的开发团队在 NumPy 中加入了优化的时间序列数据类型。datetime64数据类型将日期时间编码成了一个 64 位的整数,因此 NumPy 存储日期时间的格式非常紧凑。datetime64规定了非常明确的输入格式:
import numpy as np
date = np.array('2015-07-04', dtype=np.datetime64)
date
array('2015-07-04', dtype='datetime64[D]')
然后我们就能立刻在这个日期数组之上应用向量化操作:
date + np.arange(12)
array(['2015-07-04', '2015-07-05', '2015-07-06', '2015-07-07',
'2015-07-08', '2015-07-09', '2015-07-10', '2015-07-11',
'2015-07-12', '2015-07-13', '2015-07-14', '2015-07-15'],
dtype='datetime64[D]')
因为 NumPy 数组中所有元素都具有统一的datetime64类型,上面的向量化操作将会比我们使用 Python 的datetime对象高效许多,特别是当数组变得很大的情况下。
关于datetime64和timedelta64对象还有一个细节就是它们都是在基本时间单位之上构建的。因为datetime64被限制在 64 位精度上,因此它可被编码的时间范围就是 乘以相应的时间单位。换言之,datetime64需要在时间精度和最大时间间隔之间进行取舍。
例如,如果时间单位是纳秒,datetime64类型能够编码的时间范围就是 纳秒,不到 600 年。NumPy 可以自动从输入推断需要的时间精度(单位);如下面是天为单位:
np.datetime64('2015-07-04')
numpy.datetime64('2015-07-04')
下面是分钟为单位:
np.datetime64('2015-07-04 12:00')
numpy.datetime64('2015-07-04T12:00')
还需要注意的是,日期时间会自动按照本地计算机的时间来进行设置。你可以通过额外指定时间单位参数来设置你需要的精度;例如,下面使用的是纳秒单位:
np.datetime64('2015-07-04 12:59:59.50', 'ns')
numpy.datetime64('2015-07-04T12:59:59.500000000')
下面这张表,来自NumPy datetime64 类型在线文档,列出了可用的时间单位代码以及其相应的时间范围限制:
| 代码 | 含义 | 时间范围 (相对) | 时间范围 (绝对) |
|---|---|---|---|
Y | 年 | ± 9.2e18 年 | [公元前 9.2e18 至 公元后 9.2e18] |
M | 月 | ± 7.6e17 年 | [公元前 7.6e17 至 公元后 7.6e17] |
W | 星期 | ± 1.7e17 年 | [公元前 1.7e17 至 公元后 1.7e17] |
D | 日 | ± 2.5e16 年 | [公元前 2.5e16 至 公元后 2.5e16] |
h | 小时 | ± 1.0e15 年 | [公元前 1.0e15 至 公元后 1.0e15] |
m | 分钟 | ± 1.7e13 年 | [公元前 1.7e13 至 公元后 1.7e13] |
s | 秒 | ± 2.9e12 年 | [公元前 2.9e9 至 公元后 2.9e9] |
ms | 毫秒 | ± 2.9e9 年 | [公元前 2.9e6 至 公元后 2.9e6] |
us | 微秒 | ± 2.9e6 年 | [公元前 290301 至 公元后 294241] |
ns | 纳秒 | ± 292 年 | [公元后 1678 至 公元后 2262] |
ps | 皮秒 | ± 106 天 | [公元后 1969 至 公元后 1970] |
fs | 飞秒 | ± 2.6 小时 | [公元后 1969 至 公元后 1970] |
as | 阿秒 | ± 9.2 秒 | [公元后 1969 至 公元后 1970] |
对于我们目前真实世界的数据来说,一个合适的默认值可以是datetime64[ns],因为它既能包含现代的时间范围,也能提供相当高的时间精度。
最后,还要提醒的是,虽然datetime64数据类型解决了 Python 內建datetime类型的低效问题,但是它却缺少很多datetime特别是dateutil对象提供的很方便的方法。你可以在NumPy 的 datetime64 在线文档中查阅更多相关内容。
Pandas 中的日期和时间:兼得所长
Pandas 在刚才介绍的那些工具的基础上构建了Timestamp对象,既包含了datetime和dateutil的简单易用,又吸收了numpy.datetime64的高效和向量化操作优点。将这些Timestamp对象组合起来之后,Pandas 就能构建一个DatetimeIndex,能在Series或DataFrame当中对数据进行索引查找;我们下面会看到很多有关的例子。
例如,我们使用 Pandas 工具可以重复上面的例子。我们可以将一个灵活表示时间的字符串解析成日期时间对象,然后用时间格式化代码进行格式化输出星期几:
import pandas as pd
date = pd.to_datetime("4th of July, 2015")
date
Timestamp('2015-07-04 00:00:00')
date.strftime('%A')
'Saturday'
并且,我们可以将 NumPy 风格的向量化操作直接应用在同一个对象上:
date + pd.to_timedelta(np.arange(12), 'D')
DatetimeIndex(['2015-07-04', '2015-07-05', '2015-07-06', '2015-07-07',
'2015-07-08', '2015-07-09', '2015-07-10', '2015-07-11',
'2015-07-12', '2015-07-13', '2015-07-14', '2015-07-15'],
dtype='datetime64[ns]', freq=None)
下面,我们将详细介绍使用 Pandas 提供的工具对时间序列进行操作的方法。
Pandas 时间序列:使用时间索引
对于 Pandas 时间序列工具来说,使用时间戳来索引数据,才是真正吸引人的地方。例如,我们可以创建一个Series对象具有时间索引标签:
index = pd.DatetimeIndex(['2014-07-04', '2014-08-04',
'2015-07-04', '2015-08-04'])
data = pd.Series([0, 1, 2, 3], index=index)
data
2014-07-04 0
2014-08-04 1
2015-07-04 2
2015-08-04 3
dtype: int64
这样我们就有了一个Series数据,我们可以将任何Series索引的方法应用到这个对象上,我们可以传入参数值,Pandas 会自动转换为日期时间进行操作:
data['2014-07-04':'2015-07-04']
2014-07-04 0
2014-08-04 1
2015-07-04 2
dtype: int64
还有很多有关日期的索引方式,如下面将年作为参数传入,会得到一个全年数据的切片:
data['2015']
2015-07-04 2
2015-08-04 3
dtype: int64
后面我们会看到更多使用日期时间作为索引值的例子。首先来详细看看时间序列数据的结构。
Pandas 时间序列数据结构
这部分内容会介绍 Pandas 在处理时间序列数据时候使用的基本数据结构:
对于时间戳,Pandas 提供了 Timestamp类型。正如上面所述,它可以作为 Python 原生datetime类型的替代,但是它是构建在numpy.datetime64数据类型之上的。对应的索引结构是DatetimeIndex。对于时间周期,Pandas 提供了 Period类型。它是在numpy.datetime64的基础上编码了一个固定周期间隔的时间。对应的索引结构是PeriodIndex。对于时间差或持续时间,Pandas 提供了 Timedelta类型。构建于numpy.timedelta64之上,是 Python 原生datetime.timedelta类型的高性能替代。对应的索引结构是TimedeltaIndex。
上述这些日期时间对象中最基础的是Timestamp和DatetimeIndex对象。虽然这些对象可以直接被创建,但是更通用的做法是使用pd.to_datetime()函数,该函数可以将多种格式的字符串解析成日期时间。将一个日期时间传递给pd.to_datetime()会得到一个Timestamp对象;将一系列的日期时间传递过去会得到一个DatetimeIndex对象:
dates = pd.to_datetime([datetime(2015, 7, 3), '4th of July, 2015',
'2015-Jul-6', '07-07-2015', '20150708'])
dates
DatetimeIndex(['2015-07-03', '2015-07-04', '2015-07-06', '2015-07-07',
'2015-07-08'],
dtype='datetime64[ns]', freq=None)
任何DatetimeIndex对象都能使用to_period()函数转换成PeriodIndex对象,不过需要额外指定一个频率的参数码;下面我们使用'D'来指定频率为天:
dates.to_period('D')
PeriodIndex(['2015-07-03', '2015-07-04', '2015-07-06', '2015-07-07',
'2015-07-08'],
dtype='period[D]', freq='D')
TimedeltaIndex对象可以通过日期时间相减来创建,例如:
dates - dates[0]
TimedeltaIndex(['0 days', '1 days', '3 days', '4 days', '5 days'], dtype='timedelta64[ns]', freq=None)
规则序列:pd.date_range()
Pandas 提供了三个函数来创建规则的日期时间序列,pd.date_range()来创建时间戳的序列,pd.period_range()来创建周期的序列,pd.timedelta_range()来创建时间差的序列。我们都已经学习过 Python 的range()和 NumPy 的arange()了,它们接受开始点、结束点和可选的步长参数来创建序列。同样,pd.date_range()接受开始日期时间、结束日期时间和可选的周期码来创建日期时间的规则序列。默认周期为一天:
pd.date_range('2015-07-03', '2015-07-10')
DatetimeIndex(['2015-07-03', '2015-07-04', '2015-07-05', '2015-07-06',
'2015-07-07', '2015-07-08', '2015-07-09', '2015-07-10'],
dtype='datetime64[ns]', freq='D')
而且,日期时间的范围不仅能通过结束日期时间指定,还能通过开始日期时间和一个持续值来指定:
pd.date_range('2015-07-03', periods=8)
DatetimeIndex(['2015-07-03', '2015-07-04', '2015-07-05', '2015-07-06',
'2015-07-07', '2015-07-08', '2015-07-09', '2015-07-10'],
dtype='datetime64[ns]', freq='D')
日期时间的间隔可以通过指定freq频率参数来修改,否则默认为天D。例如,下面创建一段以小时为间隔单位的时间范围:
pd.date_range('2015-07-03', periods=8, freq='H')
DatetimeIndex(['2015-07-03 00:00:00', '2015-07-03 01:00:00',
'2015-07-03 02:00:00', '2015-07-03 03:00:00',
'2015-07-03 04:00:00', '2015-07-03 05:00:00',
'2015-07-03 06:00:00', '2015-07-03 07:00:00'],
dtype='datetime64[ns]', freq='H')
要创建Period或Timedelta对象,可以类似的调用pd.period_range()和pd.timedelta_range()函数。下面是以月为单位的时间周期序列:
pd.period_range('2015-07', periods=8, freq='M')
PeriodIndex(['2015-07', '2015-08', '2015-09', '2015-10', '2015-11', '2015-12',
'2016-01', '2016-02'],
dtype='period[M]', freq='M')
下面是以小时为单位的持续时间序列:
pd.timedelta_range(0, periods=10, freq='H')
TimedeltaIndex(['00:00:00', '01:00:00', '02:00:00', '03:00:00', '04:00:00',
'05:00:00', '06:00:00', '07:00:00', '08:00:00', '09:00:00'],
dtype='timedelta64[ns]', freq='H')
上述函数都需要我们理解 Pandas 的频率编码,我们马上会介绍它。
频率和偏移值
要使用 Pandas 时间序列工具,我们需要理解频率和时间偏移值的概念。就像前面我们看到的D代表天和H代表小时一样,我们可以使用这类符号码指定需要的频率间隔。下表总结了主要的频率码:
| 码 | 说明 | 码 | 说明 |
|---|---|---|---|
D | 自然日 | B | 工作日 |
W | 周 | ||
M | 自然日月末 | BM | 工作日月末 |
Q | 自然日季末 | BQ | 工作日季末 |
A | 自然日年末 | BA | 工作日年末 |
H | 自然小时 | BH | 工作小时 |
T | 分钟 | ||
S | 秒 | ||
L | 毫秒 | ||
U | 微秒 | ||
N | 纳秒 |
上面的月、季度和年都代表着该时间周期的结束时间。如果在这些码后面加上S后缀,则代表这些时间周期的起始时间:
| 码 | 说明 | 码 | 说明 | |
|---|---|---|---|---|
MS | 自然日月初 | BMS | 工作日月初 | |
QS | 自然日季初 | BQS | 工作日季初 | |
AS | 自然日年初 | BAS | 工作日年初 |
并且你可以通过在季度或者年的符号码后面添加三个字母的月份缩写来指定周期进行分隔的月份:
Q-JAN、BQ-FEB、QS-MAR、BQS-APR等A-JAN、BA-FEB、AS-MAR、BAS-APR等
同样,每周的分隔日也可以通过在周符号码后面添加三个字母的星期几缩写来指定:
W-SUN、W-MON、W-TUE、W-WED等
在此之上,符号码还可以进行组合用来代表其他的频率。例如要表示 2 小时 30 分钟的频率,我们可以通过将小时(H)和分钟(T)的符号码进行组合得到:
pd.timedelta_range(0, periods=9, freq="2H30T")
TimedeltaIndex(['00:00:00', '02:30:00', '05:00:00', '07:30:00', '10:00:00',
'12:30:00', '15:00:00', '17:30:00', '20:00:00'],
dtype='timedelta64[ns]', freq='150T')
上述的这些短的符号码实际上是 Pandas 时间序列偏移值的对象实例的别名,你可以在pd.tseries.offsets模块中找到这些偏移值实例。例如,我们也可以通过一个偏移值对象实例来创建时间序列:
from pandas.tseries.offsets import BDay
pd.date_range('2015-07-01', periods=5, freq=BDay())
DatetimeIndex(['2015-07-01', '2015-07-02', '2015-07-03', '2015-07-06',
'2015-07-07'],
dtype='datetime64[ns]', freq='B')
更多有关频率和偏移值的讨论,请参阅 Pandas 在线文档日期时间偏移值章节。
重新取样、移动和窗口
使用日期和时间作为索引来直观的组织和访问数据的能力,是 Pandas 时间序列工具的重要功能。前面介绍过的索引的那些通用优点(自动对齐,直观的数据切片和访问等)依然有效,而且 Pandas 提供了许多额外的时间序列相关操作。
我们会在这里介绍其中的一些,使用股票价格数据作为例子。因为 Pandas 是在金融背景基础上发展而来的,因此它具有一些特别的金融数据相关工具。例如,pandas-datareader包(可以通过conda install pandas-datareader进行安装)可以被用来从许多可用的数据源导入金融数据,包括 Yahoo 金融,Google 金融和其他。下面我们将载入 Yahoo 的收市价历史数据:
from pandas_datareader import data
goog = data.DataReader('GOOG', start='2004', end='2021',
data_source='yahoo')
goog.tail()
| High | Low | Open | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2020-07-09 | 1522.719971 | 1488.084961 | 1506.449951 | 1510.989990 | 1423300.0 | 1510.989990 |
| 2020-07-10 | 1543.829956 | 1496.540039 | 1506.150024 | 1541.739990 | 1856300.0 | 1541.739990 |
| 2020-07-13 | 1577.131958 | 1505.243042 | 1550.000000 | 1511.339966 | 1846400.0 | 1511.339966 |
| 2020-07-14 | 1522.949951 | 1483.500000 | 1490.310059 | 1520.579956 | 1585000.0 | 1520.579956 |
| 2020-07-15 | 1535.329956 | 1498.000000 | 1523.130005 | 1513.640015 | 1609800.0 | 1513.640015 |
为简单起见,我们仅使用收市价:
goog = goog['Close']
我们可以使用plot()方法来做出图表,当然之前要先完成 Matplotlib 的相关初始化工作:
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn; seaborn.set()
goog.plot();
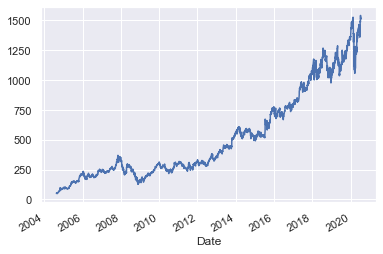
重新采样和改变频率
对于时间序列数据来说有一个很普遍的需求是对数据根据更高或更低的频率进行重新取样。这可以通过resample()方法或更简单的asfreq()方法来实现。两者的主要区别在于resample()主要进行数据聚合操作,而asfreq()方法主要进行数据选择操作。
观察一下谷歌的收市价,让我们来比较一下使用两者对数据进行更低频率来采样的情况。下面我们对数据进行每个工作日年度进行重新取样:
goog.plot(alpha=0.5, style='-')
goog.resample('BA').mean().plot(style=':')
goog.asfreq('BA').plot(style='--');
plt.legend(['input', 'resample', 'asfreq'],
loc='upper left');
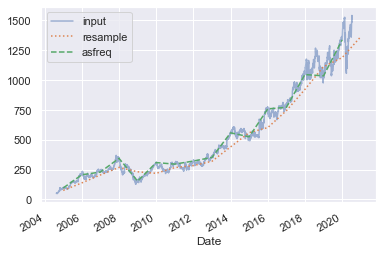
注意这里的区别:在每个点,resample返回了这一个年度的平均值,而asfreq返回了年末的收市值。
对于采用更高频率的取样来说,resample()和asfreq()方法大体上是相同的,虽然 resample 有着更多的参数。在这个例子中,默认的方式是将更高频率的采样点填充为空值,即 NA 值。就像之前介绍过的pd.fillna()函数那样,asfreq()方法接受一个method参数来指定值以那种方式插入。下面,我们将原本数据的工作日频率扩张为自然日频率(即包括周末):
fig, ax = plt.subplots(2, sharex=True)
data = goog.tail(10)
data.asfreq('D').plot(ax=ax[0], marker='o')
data.asfreq('D', method='bfill').plot(ax=ax[1], style='-o')
data.asfreq('D', method='ffill').plot(ax=ax[1], style='--o')
ax[1].legend(["back-fill", "forward-fill"]);
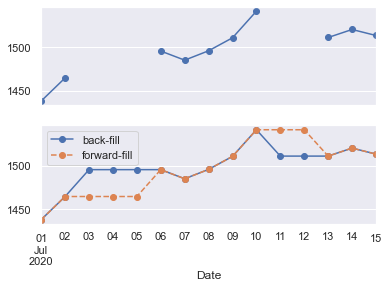
上面的子图表是默认的:非工作日的数据点被填充为 NA 值,因此在图中没有显示。下面的子图表展示了两种不同填充方法的差别:前向填充和后向填充。
时间移动
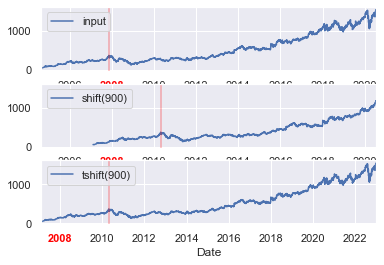
另一个普遍的时间序列相关操作是移动时间。Pandas 有两个很接近的方法来实现时间的移动:shift()和tshift。简单来说,shift()移动的是数据,而tshift()移动的是时间索引。两个方法使用的移动参数都是当前频率的倍数。
下面我们使用shift()和tshift()方法将数据和时间索引移动 900 天:
fig, ax = plt.subplots(3, sharey=True)
# 在数据上应用一个频率
goog = goog.asfreq('D', method='pad')
goog.plot(ax=ax[0]) # 画出原图
goog.shift(900).plot(ax=ax[1]) # 数据移动900天
goog.tshift(900).plot(ax=ax[2]) # 时间移动900天
# 图例和标签
local_max = pd.to_datetime('2007-11-05')
offset = pd.Timedelta(900, 'D')
ax[0].legend(['input'], loc=2)
ax[0].get_xticklabels()[2].set(weight='heavy', color='red')
ax[0].axvline(local_max, alpha=0.3, color='red')
ax[1].legend(['shift(900)'], loc=2)
ax[1].get_xticklabels()[2].set(weight='heavy', color='red')
ax[1].axvline(local_max + offset, alpha=0.3, color='red')
ax[2].legend(['tshift(900)'], loc=2)
ax[2].get_xticklabels()[1].set(weight='heavy', color='red')
ax[2].axvline(local_max + offset, alpha=0.3, color='red');
fig, ax = plt.subplots(3, sharey=True)
# 在数据上应用一个频率
goog = goog.asfreq('D', method='pad')
goog.plot(ax=ax[0]) # 画出原图
goog.shift(900).plot(ax=ax[1]) # 数据移动900天
goog.tshift(900).plot(ax=ax[2]) # 时间移动900天
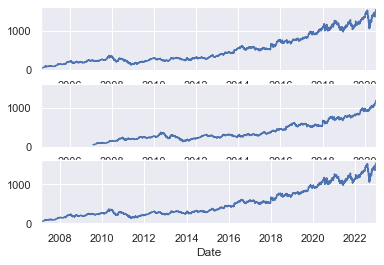
上例中,我们看到shift(900)将数据向前移动了 900 天,导致部分数据都超过了图表的右侧范围(左侧新出现的值被填充为 NA 值),而tshift(900)将时间向后移动了 900 天。
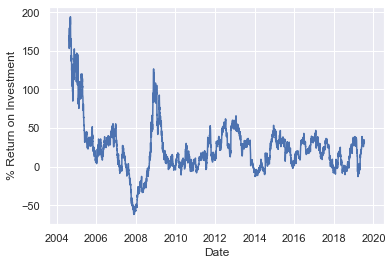
这种时间移动的常见应用场景是计算同比时间段的差值。例如,我们可以将数据时间向前移动 365 天来计算谷歌股票的年投资回报率:
ROI = 100 * (goog.tshift(-365) / goog - 1)
ROI.plot()
plt.ylabel('% Return on Investment');
goog.tshift(-365)
Date
2003-08-20 49.982655
2003-08-21 53.952770
2003-08-22 53.952770
2003-08-23 53.952770
2003-08-24 54.495735
...
2019-07-12 1541.739990
2019-07-13 1541.739990
2019-07-14 1511.339966
2019-07-15 1520.579956
2019-07-16 1513.640015
Freq: D, Name: Close, Length: 5810, dtype: float64
这帮助我们看到谷歌股票的整体趋势:直到目前为止,投资谷歌股票回报最高的时期(完全不令人惊讶)是 IPO 之后的短暂时期以及 2009 中期经济衰退的时期。
滚动窗口
滚动窗口统计是第三种 Pandas 时间序列相关的普遍操作。这个统计任务可以通过Series和DataFrame对象的rolling()方法来实现,这个方法的返回值类似与我们之前看到的groupby操作(参见聚合与分组)。在该滚动窗口视图上可以进行一系列的聚合操作。
例如,下面是对谷歌股票价格在 365 个记录中居中求平均值和标准差的结果:
rolling = goog.rolling(365, center=True) # 对365个交易日的收市价进行滚动窗口居中
data = pd.DataFrame({'input': goog,
'one-year rolling_mean': rolling.mean(), # 平均值Series
'one-year rolling_std': rolling.std()}) # 标准差Series
ax = data.plot(style=['-', '--', ':'])
ax.lines[0].set_alpha(0.3)
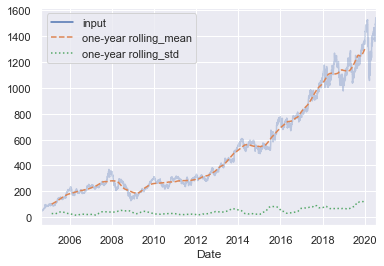
和 groupby 操作一样,aggregate()和apply()方法可以在滚动窗口上实现自定义的统计计算。
更多学习资源
本节只是简要的介绍了 Pandas 提供的时间序列工具中最关键的特性;需要完整的内容介绍,你可以访问 Pandas 在线文档的"时间序列/日期"章节。
还有一个很棒的资源是Python for Data Analysis教科书,作者 Wes McKinney (OReilly, 2012)。虽然已经出版了好几年,这本书仍然是 Pandas 使用的非常有价值的资源。特别是书中着重介绍在商业和金融领域中使用时间序列相关工具的内容,还有许多对商业日历,时区等相关主题的讨论。
当然别忘了,你可以使用 IPython 的帮助和文档功能来学习和尝试这些工具方法的不同参数。这通常是学习 Python 工具最佳实践。
例子:西雅图自行车统计可视化
最后作为一个更深入的处理时间序列数据例子,我们来看一下西雅图费利蒙桥的自行车数量统计。该数据集来源自一个自动自行车的计数器,在 2012 年末安装上线,它们能够感应到桥上东西双向通过的自行车并进行计数。按照小时频率采样的自行车数量计数数据集可以在这个链接处直接下载。
2016 年夏天的数据可以使用下面的命令下载:
# !curl -o FremontBridge.csv https://data.seattle.gov/api/views/65db-xm6k/rows.csv?accessType=DOWNLOAD
下载了数据集后,我们就可以用 Pandas 将 CSV 文件的内容导入成DataFrame对象。我们指定使用日期作为行索引,还可以通过parse_dates参数要求 Pandas 自动帮我们转换日期时间格式:
data = pd.read_csv(r'D:\python\Github学习材料\Python数据科学手册\notebooks\data\FremontBridge.csv', index_col='Date', parse_dates=True)
data.head()
| Fremont Bridge Total | Fremont Bridge East Sidewalk | Fremont Bridge West Sidewalk | |
|---|---|---|---|
| Date | |||
| 2012-10-03 00:00:00 | 13.0 | 4.0 | 9.0 |
| 2012-10-03 01:00:00 | 10.0 | 4.0 | 6.0 |
| 2012-10-03 02:00:00 | 2.0 | 1.0 | 1.0 |
| 2012-10-03 03:00:00 | 5.0 | 2.0 | 3.0 |
| 2012-10-03 04:00:00 | 7.0 | 6.0 | 1.0 |
为了简单,我们将这个数据集的列名改的简短些,并增加总计“Total”列:
# data.columns = ['West', 'East']
# data['Total'] = data.eval('West + East')
data.columns = ['Total', 'East', 'West']
现在我们来看看这个数据集的总体情况:
data.dropna().describe()
| Total | East | West | |
|---|---|---|---|
| count | 10771.000000 | 10771.000000 | 10771.000000 |
| mean | 99.713861 | 51.416489 | 48.297373 |
| std | 120.397155 | 63.867062 | 67.568734 |
| min | 0.000000 | 0.000000 | 0.000000 |
| 25% | 15.000000 | 7.000000 | 7.000000 |
| 50% | 57.000000 | 29.000000 | 26.000000 |
| 75% | 134.000000 | 69.000000 | 60.000000 |
| max | 831.000000 | 626.000000 | 593.000000 |
可视化数据
我们可以通过将数据可视化成图表来更好的观察分析数据集。首先我们来展示原始数据图表:
%matplotlib inline
import seaborn; seaborn.set()
data.plot()
plt.ylabel('Hourly Bicycle Count');
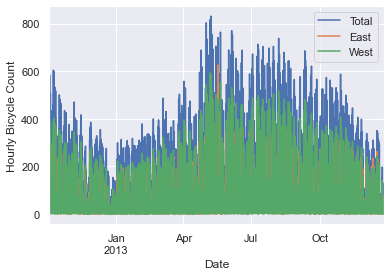
约 25000 小时的样本数据画在图中非常拥挤,我们很观察到什么有意义的结果。我们可以通过重新取样,降低频率来获得更粗颗粒度的图像。如下面按照每周来重新取样:
weekly = data.resample('W').sum()
weekly.plot(style=[':', '--', '-'])
plt.ylabel('Weekly bicycle count');
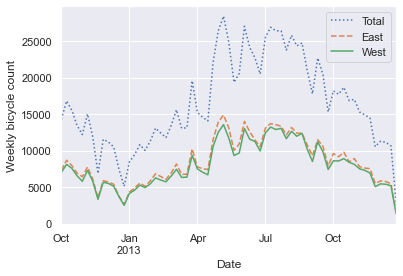
上图向我们展示非常有趣的季节性趋势:你应该已经预料到,人们在夏季会比冬季更多的骑自行车,即使在一个季节中,每周自行车的数量也有很大起伏(这主要是由于天气造成的;我们会在深入:线性回归中会更加深入的讨论)。
还有一个很方便的聚合操作就是滚动平均值,使用pd.rolling_mean()函数。下面我们进行 30 天的滚动平均,窗口居中进行统计:
daily = data.resample('D').sum()
daily.rolling(30, center=True).sum().plot(style=[':', '--', '-'])
plt.ylabel('mean hourly count');
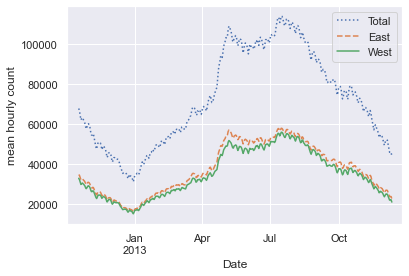
上图结果中的锯齿图案产生的原因是窗口边缘的硬切割造成的。我们可以使用不同的窗口类型来获得更加平滑的结果,例如高斯窗口。下面的代码制定了窗口的宽度(50 天)和窗口内的高斯宽度(10 天):
daily.rolling(50, center=True,
win_type='gaussian').sum(std=10).plot(style=[':', '--', '-']);
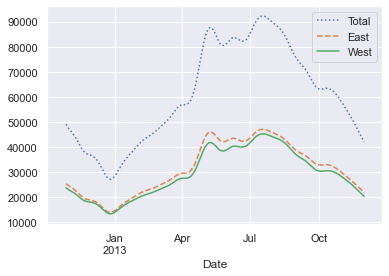
挖掘数据
虽然上面的光滑折线图展示了大体的数据趋势情况,但是很多有趣的结构依然没有展现出来。例如,我们希望对每天不同时段的平均交通情况进行统计,我们可以使用聚合与分组中介绍过的 GroupBy 功能:
by_time = data.groupby(data.index.time).mean()
hourly_ticks = 4 * 60 * 60 * np.arange(6) # 将24小时分为每4个小时一段展示
by_time.plot(xticks=hourly_ticks, style=[':', '--', '-']);
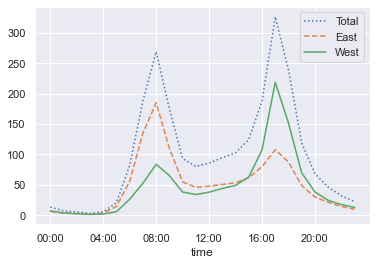
小时交通数据图展现了明显的双峰构造,峰值大约出现在早上 8:00 和下午 5:00。这显然就是大桥在通勤时间交通繁忙的最好证据。再注意到东西双向峰值不同,证明了早上通勤时间多数的交通流量是从东至西(往西雅图城中心方向),而下午通勤时间多数的交通流量是从西至东(离开西雅图城中心方向)。
我们可能也会很好奇一周中每天的平均交通情况。当然,还是通过简单的 GroupBy 就能实现:
by_weekday = data.groupby(data.index.dayofweek).mean()
by_weekday.index = ['Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat', 'Sun']
by_weekday.plot(style=[':', '--', '-']);
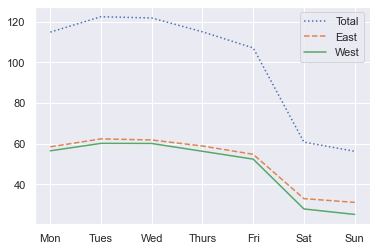
上图清晰的展示了工作日和休息日的区别,周一到周五的流量基本上达到周六日的两倍。
有了上面两个分析的基础,让我们来进行一个更加复杂的分组查看工作日和休息日按照小时交通流量的情况。我们首先使用np.where将工作日和休息日分开:
weekend = np.where(data.index.weekday < 5, 'Weekday', 'Weekend')
by_time = data.groupby([weekend, data.index.time]).mean()
然后我们使用将在多个子图表中介绍的方法将两个子图表并排展示:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 2, figsize=(14, 5))
by_time.loc['Weekday'].plot(ax=ax[0], title='Weekdays',
xticks=hourly_ticks, style=[':', '--', '-'])
by_time.loc['Weekend'].plot(ax=ax[1], title='Weekends',
xticks=hourly_ticks, style=[':', '--', '-']);
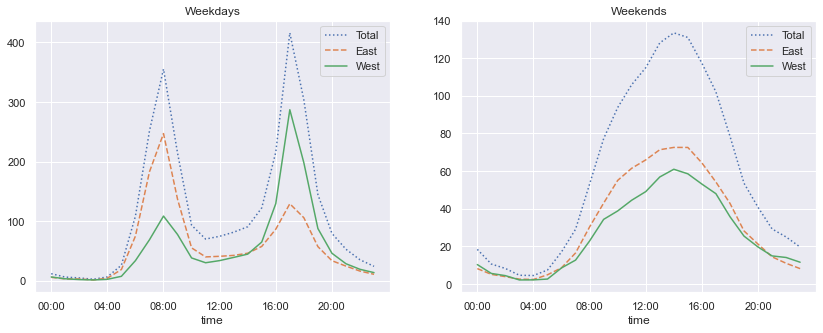
这个结果非常有趣:我们可以在工作日看到明显的双峰构造,但是在休息日就只能看到一个峰。如果我们继续挖掘下去,这个数据集还有更多有趣的结构可以被发现,可以分析天气、气温、每年的不同时间以及其他因素是如何影响居民的通勤方式的;要深入讨论,可以参见作者的博客文章"Is Seattle Really Seeing an Uptick In Cycling?",里面使用了这个数据集的子集。
[1]https://github.com/jakevdp/PythonDataScienceHandbook
-END-