
卷积神经网络如何处理一维时间序列数据?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自 | 人工智能与算法学习
概述
许多文章都关注于二维卷积神经网络(2D CNN)的使用,特别是图像识别。而一维卷积神经网络(1D CNNs)只在一定程度上有所涉及,比如在自然语言处理(NLP)中的应用。目前很少有文章能够提供关于如何构造一维卷积神经网络来一些机器学习问题。
何时应用 1D CNN?
CNN 可以很好地识别出数据中的简单模式,然后使用这些简单模式在更高级的层中生成更复杂的模式。当你希望从整体数据集中较短的(固定长度,即kernal size)片段中获得感兴趣特征,并且该特性在该数据片段中的位置不具有高度相关性时,1D CNN 是非常有效的。
1D CNN 可以很好地应用于传感器数据的时间序列分析(比如陀螺仪或加速度计数据);同样也可以很好地用于分析具有固定长度周期的信号数据(比如音频信号)。此外,它还能应用于自然语言处理的任务(由于单词的接近性可能并不总是一个可训练模式的好指标,因此 LSTM 网络在 NLP 中的应用更有前途)。
1D CNN 和 2D CNN 之间有什么区别?
无论是一维、二维还是三维,卷积神经网络(CNNs)都具有相同的特点和相同的处理方法。关键区别在于输入数据的维数以及特征检测器(或滤波器)如何在数据之间滑动:
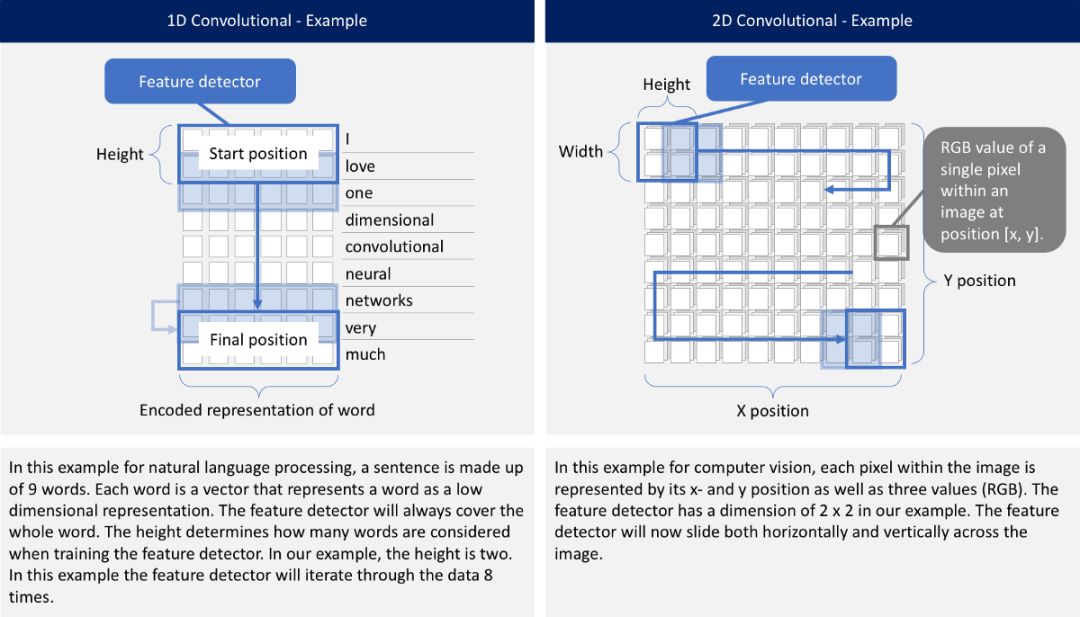
问题描述
在本文中,我们将专注于基于时间片的加速度传感器数据的处理,这些数据来自于用户的腰带式智能手机设备。基于 x、y 和 z 轴的加速度计数据,1D CNN 用来预测用户正在进行的活动类型(比如“步行”、“慢跑”或“站立”)。

来自加速度计数据的时间序列样例
如何在 Python 中构造一个 1D CNN?
目前已经有许多得标准 CNN 模型可用。我选择了 Keras 网站 上描述的一个模型,并对它进行了微调,以适应前面描述的问题。下面的图片对构建的模型进行一个高级概述。其中每一层都将会进一步加以解释。


让我们深入到每一层中,看看到底发生了什么:
输入数据: 数据经过预处理后,每条数据记录中包含有 80 个时间片(数据是以 20Hz 的采样频率进行记录的,因此每个时间间隔中就包含有 4 秒的加速度计数据)。在每个时间间隔内,存储加速度计的 x 轴、 y 轴和 z 轴的三个数据。这样就得到了一个 80 x 3 的矩阵。由于我通常是在 iOS 系统中使用神经网络的,所以数据必须平展成长度为 240 的向量后传入神经网络中。网络的第一层必须再将其变形为原始的 80 x 3 的形状。
第一个 1D CNN 层: 第一层定义了高度为 10(也称为卷积核大小)的滤波器(也称为特征检测器)。只有定义了一个滤波器,神经网络才能够在第一层中学习到一个单一的特征。这可能还不够,因此我们会定义 100 个滤波器。这样我们就在网络的第一层中训练得到 100 个不同的特性。第一个神经网络层的输出是一个 71 x 100 的矩阵。输出矩阵的每一列都包含一个滤波器的权值。在定义内核大小并考虑输入矩阵长度的情况下,每个过滤器将包含 71 个权重值。
第二个 1D CNN 层: 第一个 CNN 的输出结果将被输入到第二个 CNN 层中。我们将在这个网络层上再次定义 100 个不同的滤波器进行训练。按照与第一层相同的逻辑,输出矩阵的大小为 62 x 100。
最大值池化层: 为了减少输出的复杂度和防止数据的过拟合,在 CNN 层之后经常会使用池化层。在我们的示例中,我们选择了大小为 3 的池化层。这意味着这个层的输出矩阵的大小只有输入矩阵的三分之一。
第三和第四个 1D CNN 层: 为了学习更高层次的特征,这里又使用了另外两个 1D CNN 层。这两层之后的输出矩阵是一个 2 x 160 的矩阵。
平均值池化层: 多添加一个池化层,以进一步避免过拟合的发生。这次的池化不是取最大值,而是取神经网络中两个权重的平均值。输出矩阵的大小为 1 x 160 。每个特征检测器在神经网络的这一层中只剩下一个权重。
Dropout 层: Dropout 层会随机地为网络中的神经元赋值零权重。由于我们选择了 0.5 的比率,则 50% 的神经元将会是零权重的。通过这种操作,网络对数据的微小变化的响应就不那么敏感了。因此,它能够进一步提高对不可见数据处理的准确性。这个层的输出仍然是一个 1 x 160 的矩阵。
使用 Softmax 激活的全连接层: 最后一层将会把长度为 160 的向量降为长度为 6 的向量,因为我们有 6 个类别要进行预测(即 “慢跑”、“坐下”、“走路”、“站立”、“上楼”、“下楼”)。这里的维度下降是通过另一个矩阵乘法来完成的。Softmax 被用作激活函数。它强制神经网络的所有六个输出值的加和为一。因此,输出值将表示这六个类别中的每个类别出现的概率。
训练和测试该神经网络
下面是一段用以训练模型的 Python 代码,批大小为 400,其中训练集和验证集的分割比例是 80 :20。

该模型在训练数据上的准确率可达 97%。
根据测试集数据进行测试,其准确率为 92%。
展望
上面是以分类问题来举例的,对于回归预测问题,只需要把最后一层的全连接层使用linear激活即可~
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~