
用逻辑回归来进行分类

逻辑回归是机器学习中经常用到的一种方法,其属于有监督机器学习,逻辑回归的名字虽然带有“回归”二字,但实际上它却属于一种分类方法,本文就介绍一下如何用逻辑回归进行分类。
首先还是介绍一下逻辑回归的基本原理。
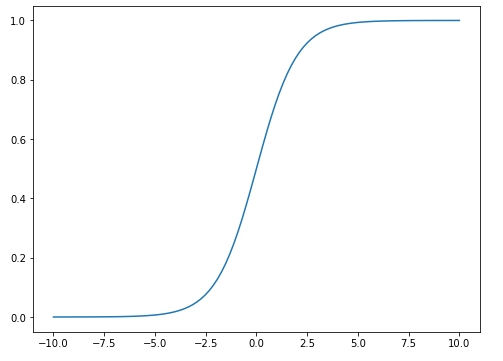
图1. 逻辑函数图形
逻辑回归之所以叫“逻辑”,是因为其使用了Logistic函数(也称Sigmoid函数),该函数形式如图2中式(1)所示,图形如图1所示。既然逻辑回归是分类方法,那么我们这里就以最简单的二分类来说明一下,二分类的输出标记为 y=0或1,而线性回归产生的预测值z = ω^Tx+b,我们让t=z,把z的表达式带入到式(1)中得到式(2),再做变换就得到式(3)。y是我们要求的正例,1-y则是反例,二者比值则可称为几率,所以式(3)可以称作“对数几率”。接下来我们要求解ω和b,用的是极大似然估计法。我们将y视为后验概率估计p(y=1|x),那么就可以得到图3中的式(4)和(5)。接下来令β=(ω;b)和x=(x;1),可得到式(6),由式(6)的得到图4中(7)、(8)和(9),(9)就是目标函数,对目标函数求解得到最优参数即可。这些推导比较复杂,笔者在这里仅列出了主要部分,大家如果有兴趣,可自行查阅相关资料。
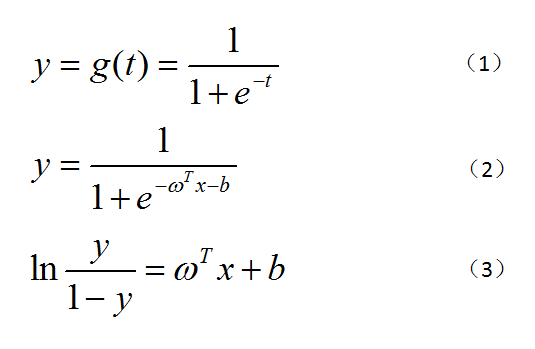
图2. 逻辑回归推导公式(1)—(3)
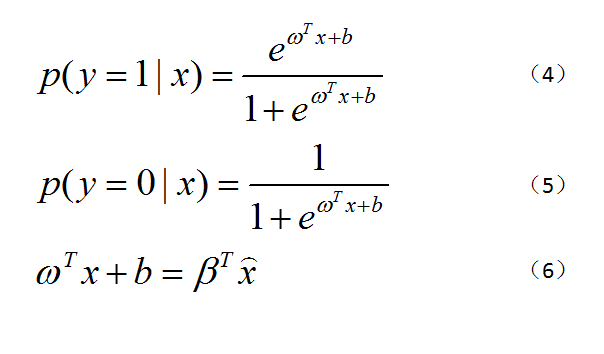
图3. 逻辑回归推导公式(4)—(6)
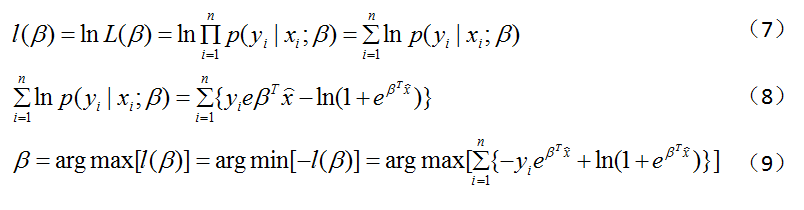
图4. 逻辑回归推导公式(7)—(9)
在了解逻辑回归的基本原理之后,我们再用一个例子来介绍一下逻辑回归的用法。
本文中我们使用的逻辑回归模型来自scikit-learn,用到的数据集也同样来自于scikit-learn,代码如下。
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
X, y = make_classification(n_samples=100, n_features=2,
n_informative=2, n_redundant=0, n_clusters_per_class=1,
class_sep = 2.0, random_state=15)
fig, ax = plt.subplots(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
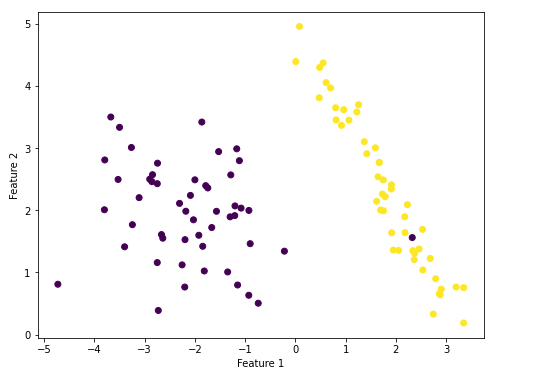
图5. 本例中所用数据点
其结果如图5所示。这个数据集是我们用make_classification方法生成的,共100个点,一共两个特征(维度),所有数据共分为两个类。从图中可以看出紫色的点分为一类,黄色的点分为另一类。然后对数据集进行一下划分,分为训练集和测试集,代码如下。X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=30)
在这里,我们设置测试集的数据个数为30个,随机状态random_state为30,这个数字可以随意设置。接下来我们用逻辑回归来进行一下训练和预测,结果用classification_report方法输出。
model = LogisticRegression() #生成模型
model.fit(X_train, y_train) #输入训练数据
y_predict = model.predict(X_test) #输出预测数据
print(classification_report(y_test, y_predict)) #生成预测结果报告预测
结果如图6所示。从图6中我们可以看出该模型的accuracy为0.97,因为我们的测试数据共有30个,所以这意味着我们只有1个点预测错了,说明该模型的分类效果还是非常不错的。
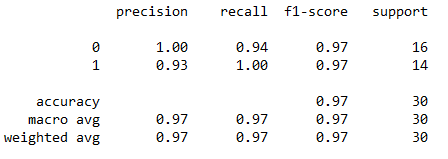
图6. 模型结果报告
然后为了让大家对该模型的分类效果有一个进一步的了解,笔者在这里再深入研究一下,我们再来看看逻辑回归模型的分类边界,即该模型是从哪里开始进行划分的,代码如下。
step = 0.01 # 相当步长,越小点越密集
x_min = X[:, 0].min() -1 #设置mesh的边界
x_max = X[:, 0].max() + 1
y_min = X[:, 1].min() - 1
y_max = X[:, 1].max() + 1
x_mesh, y_mesh = np.meshgrid(np.arange(x_min, x_max, step), np.arange(y_min, y_max, step))
data_mesh = np.stack([x_mesh.ravel(), y_mesh.ravel()], axis=-1) #把mesh转换为2列的数据
Z = model.predict(data_mesh)
Z = Z.reshape(x_mesh.shape)
fig, ax = plt.subplots(figsize=(8,6))
plt.pcolormesh(x_mesh, y_mesh, Z, cmap=plt.cm.cool) #画出mesh的颜色
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.ocean)
plt.show()
这里代码有些复杂,解释一下。我们的设计思路是这样的,因为本次使用的逻辑回归模型是一个二分类模型,也就是将结果分为了两个类,那么我们把模型中每个类的区域用一种颜色标出,这样就有两种颜色。落入每个区域的点就属于这个区域,也就是这个类。x_mesh, y_mesh = np.meshgrid(np.arange(x_min, x_max, step), np.arange(y_min, y_max, step)) 这行代码就是得到整个区域(也就是两个类的区域之和)的点,这个区域比我们用到的数据集的范围大一些,x_min、x_max、y_min、y_max就是整个区域的边界。data_mesh = np.stack([x_mesh.ravel(), y_mesh.ravel()], axis=-1) 这行代码就是把上面整个区域中的点转换为2列的数据,便于后面预测,Z = model.predict(data_mesh)就是区域每个点的预测值,我们再用plt.pcolormesh和plt.scatter分别画出区域颜色和数据点的颜色,就能清楚看到那些点在哪个区域中。其结果如图7所示。
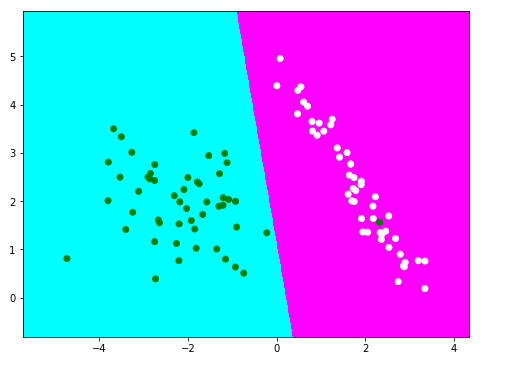
图7. 用不同颜色来表示不同的划分区域
从结果中可以看出,有一个绿色的点落入到了错误的区域中,说明这个点预测错了,这和我们前面classification_report得到的结果一致。
逻辑回归在机器学习中的使用非常广泛而且效果也不错,但其也有一些缺点,比如不能解决非线性问题、对多重共线性数据较为敏感、很难处理数据不平衡的问题等。其原理也要比笔者介绍的复杂不少,想要深入了解的读者可以自行查找相关资料来学习。
作者简介:Mort,数据分析爱好者,擅长数据可视化,比较关注机器学习领域,希望能和业内朋友多学习交流。
赞赏作者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
长按扫码添加“Python小助手”
▼点击成为社区会员 喜欢就点个在看吧