
利用神经网络对常见水果进行分类
点击下面卡片关注“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
一个易于阅读的神经网络指南,以实现高准确率
目的:为 Fruits360 寻找一个能够达到最高分类准确率的神经网络模型。
深度前馈网络
卷积神经网络
残差神经网络(ResNet9)
准备工作
首先,让我们来理解我们的数据集!
Kaggle Fruits360 数据集包含131种不同类型的水果和蔬菜的90483张图像。首先,我们导入数据和所需的库。
import torchimport osimport jovianimport torchvisionimport numpy as npimport matplotlib.pyplot as pltimport torch.nn as nnimport torchvision.models as modelsimport torch.nn.functional as Ffrom torchvision.datasets import ImageFolderfrom torchvision.transforms import ToTensorfrom torchvision.utils import make_gridfrom torch.utils.data.dataloader import DataLoaderfrom torch.utils.data import random_splitimport torchvision.models as models%matplotlib inline
使用matplotlib库显示彩色图像:
import matplotlib.pyplot as pltdef show_example(img, label):print('Label: ', dataset.classes[label], "("+str(label)+")")plt.imshow(img.permute(1, 2, 0))

当我们使用PyTorch时,我们必须使用ToTensor将上述像素图像转换为张量:
dataset = ImageFolder(data_dir + '/Training', transform=ToTensor())img, label = dataset[0]print(img.shape, label)img
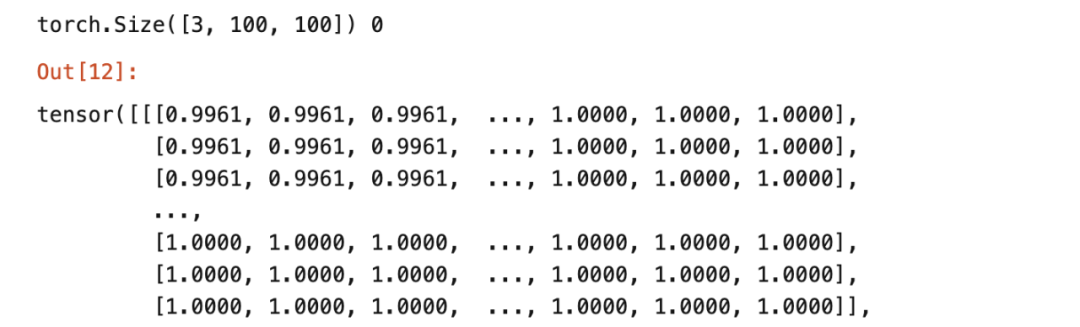
有3个通道(红,绿,蓝) ,100 * 100图像大小。每个值表示颜色强度相对于通道颜色。
训练和验证数据集
接下来,我们将随机分割数据,得到3组数据:
训练集:训练模型
验证集:评估模型
测试集:测试模型的最终准确性
训练数据集规模:57692
验证数据集大小: 10,000
测试数据集的大小: 22,688
分批训练
由于我们总共有57,692个训练图像,在使用 Dataloader 训练模型之前,我们应该将图像分成更小的批量。使用较小的数据集会减少内存空间,从而提高训练速度。
对于我们的数据集,我们将设置 batch 为 128。

现在,我们将开始构建我们的模型。
1. 深度前馈网络
超参数:
结构:“5层(2000,1000,500,250,131)”
学习率:[0.01,0.001]
epoch:[10,10]
优化器:随机梯度下降
使用5层架构来训练模型:
class FruitsModelFF(ImageClassificationBase):def __init__(self):super().__init__()self.linear1= nn.Linear(input_size, 2000)self.linear2= nn.Linear(2000, 1000)self.linear3= nn.Linear(1000,500)self.linear4= nn.Linear(500,250)self.linear5= nn.Linear(250, output_size)def forward(self, xb):out = xb.view(xb.size(0), -1)out= self.linear1(out)out=F.relu(out)out=self.linear2(out)out=F.relu(out)out=self.linear3(out)out=F.relu(out)out=self.linear4(out)out=F.relu(out)out=self.linear5(out)return out
在训练前,验证准确率为: 0.52734%
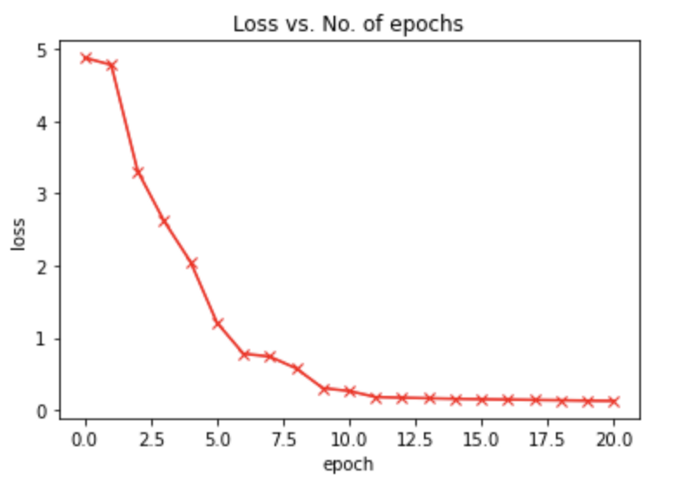
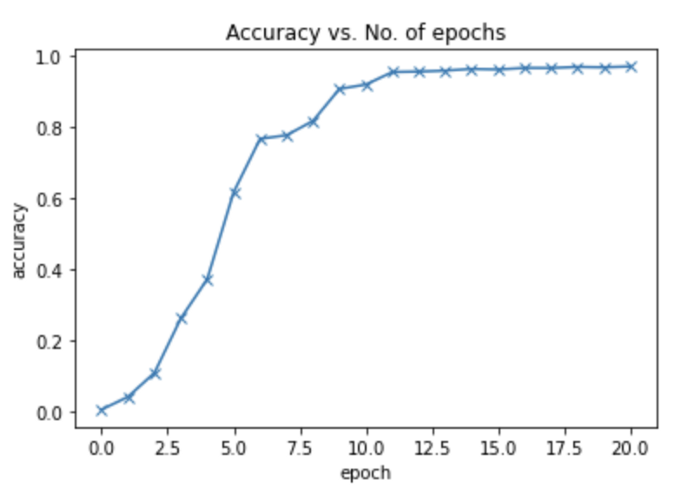
在以 [0.01,0.001] 学习率进行总共20个 epoch 的训练之后,验证准确率在96.84% 左右达到一个平稳期。这与最初的0.52734% 相比是一个巨大的跳跃。
最后,让我们用测试数据集来测试我们训练过的模型
img, label = test[8000]plt.imshow(img.permute(1, 2, 0))print('Label:', dataset.classes[label], ', Predicted:', predict_image(img, model))

img, label = test[1002]plt.imshow(img.permute(1, 2, 0))print('Label:', dataset.classes[label], ', Predicted:', predict_image(img, model))

img, label = test[0]plt.imshow(img.permute(1, 2, 0))print('Label:', dataset.classes[label], ', Predicted:', predict_image(img, model))

我们的训练模型正确地预测了上述所有水果。
Final test accuracy: 86.209%为了进一步提高我们的测试准确性,我们将使用一个通常比前馈神经网络性能更好的卷积神经网络神经网络。
ConvNet 能够通过相关的滤波器成功地捕获图像中的空间和时间依赖关系。由于减少了参数的数量和权值的可重用性,该体系结构能够更好地适应图像数据集。换句话说,网络可以通过训练来更好地理解图像的复杂性。
简而言之,CNN 非常适合计算密集型的大尺寸图像:
需要更少的参数
形成联系的稀疏性
有能力检测相似的模式,并应用在图像的不同部分学到的特征
2. 简单的卷积神经网络
简要介绍一下 CNN 的特点:
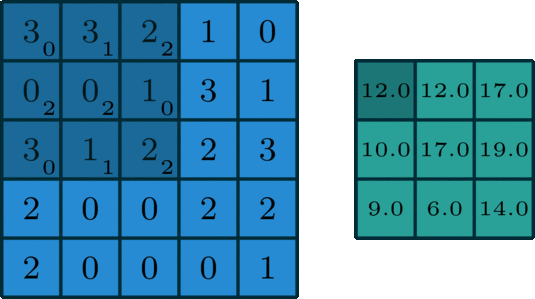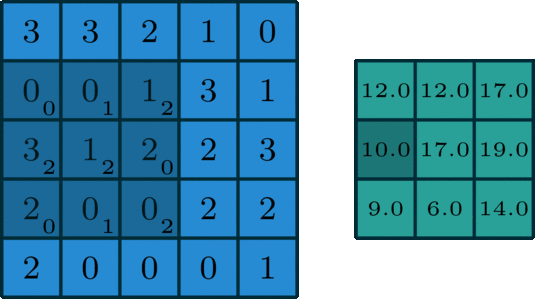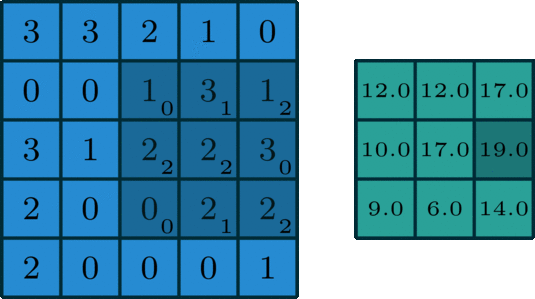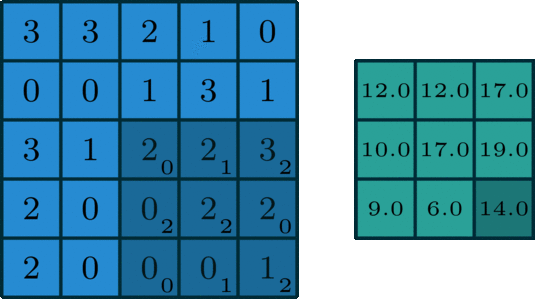
内核上的权重首先随机初始化为:
[0, 1, 2][2, 2, 0][0, 1, 2]
我们的示例图片如下所示:
[3, 3, 2, 1, 0][0, 0, 1, 3, 1][3, 1, 2, 2, 3][2, 0, 0, 2, 2][2, 0, 0, 0, 1]
当我们将内核应用于示例图像时,输出将是:
[12., 12., 17.][10., 17., 19.][ 9., 6., 14.]
应用:
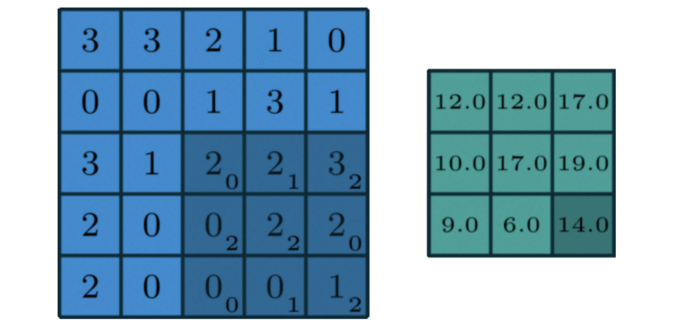
output= 2*0 + 2*1 + 3*2 + 0*2 + 2*2 + 2*0 + 0*0 + 0*1 + 1*2 = 14
对内核在样本图像上的每次移动重复输出的计算,以获取新的输出大小。
def apply_kernel(image, kernel):ri, ci = image.shape # image dimensionsrk, ck = kernel.shape # kernel dimensionsro, co = ri-rk+1, ci-ck+1 # output dimensionsoutput = torch.zeros([ro, co])for i in range(ro):for j in range(co):output[i,j] = torch.sum(image[i:i+rk,j:j+ck] * kernel)return output
此外,通过应用最大池化层,我们逐渐减小了每个卷积层输出张量的大小。
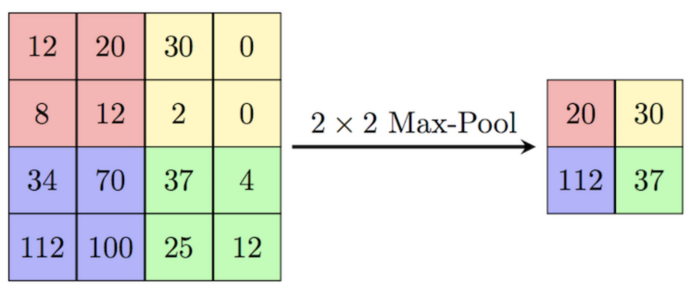
如前所述,卷积层增加了通道数,而最大池化层减少了图像大小。
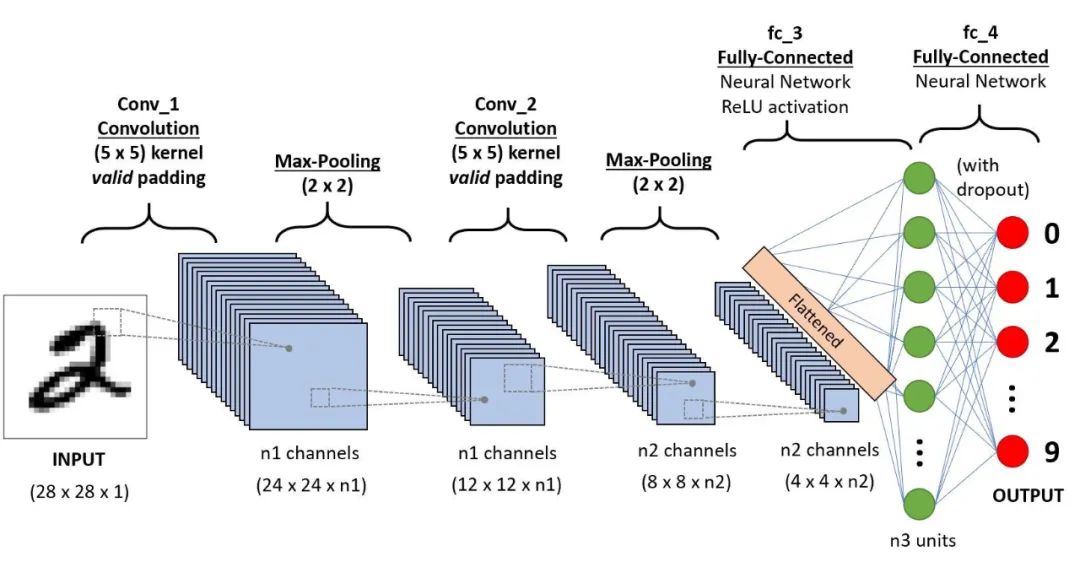
现在,让我们为相同的 Kaggle Fruit Dataset 建立 CNN 模型。
超参数:
epoch:10
学习率:0.001
优化器功能:Adam
class FruitsModel(ImageClassificationBase):def __init__(self):super().__init__()self.network = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, padding=1), #3 channels to 32 channelsnn.ReLU(),nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 64 channels x 50 x 50 image size - decreasenn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1), #can keep the same, increase power of model , go deeper as u add linearity to non-linearitynn.ReLU(),nn.MaxPool2d(2, 2), # output: 128 x 25 x 25nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(5, 5), # output: 256 x 5 x 5nn.Flatten(), #a single vector 256*5*5,nn.Linear(256*5*5, 1024),nn.ReLU(),nn.Linear(1024, 512),nn.ReLU(),nn.Linear(512, 131))def forward(self, xb):return self.network(xb)
除了我们的模型中的一个变化,我们使用 Adam optimiiser 函数,因为它是在分类问题中寻找最小成本函数的一个更有效的方法。
Final test accuracy rate: 92.571%我们实现了一个非常高的最终测试准确率,比前馈神经网络约高6% 。
3. 残差神经网络(ResNet9)
超参数:
最大学习率:0.01
epoch:10
优化器:Adam
def conv_block(in_channels, out_channels, pool=False):layers = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True)]if pool: layers.append(nn.MaxPool2d(2))return nn.Sequential(*layers)class ResNet9(ImageClassificationBase):def __init__(self, in_channels, num_classes):super().__init__()self.conv1 = conv_block(in_channels, 64)self.conv2 = conv_block(64, 128, pool=True)self.res1 = nn.Sequential(conv_block(128, 128), conv_block(128, 128))self.conv3 = conv_block(128, 256, pool=True)self.conv4 = conv_block(256, 512, pool=True)self.res2 = nn.Sequential(conv_block(512, 512), conv_block(512, 512))self.classifier = nn.Sequential(nn.MaxPool2d(4),nn.Flatten(),nn.Linear(4608, num_classes))def forward(self, xb):out = self.conv1(xb)out = self.conv2(out)out = self.res1(out) + outout = self.conv3(out)out = self.conv4(out)out = self.res2(out) + outout = self.classifier(out)return out
除此之外,我们也会推出「单周期学习率策略」,逐步提高学习率至使用者设定的最高值,然后逐步降至最低值。这种学习率的变化发生在每一个 epoch 之后。
相对较高的学习率会导致发散,而相对较低的学习率又会导致模型的过度拟合,因此很难找到合适的学习率。
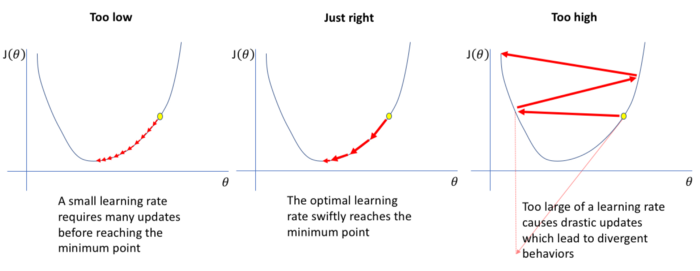
然而,“单周期学习率策略”通过为我们的模型找到一个最优学习率的范围,克服了这个问题。
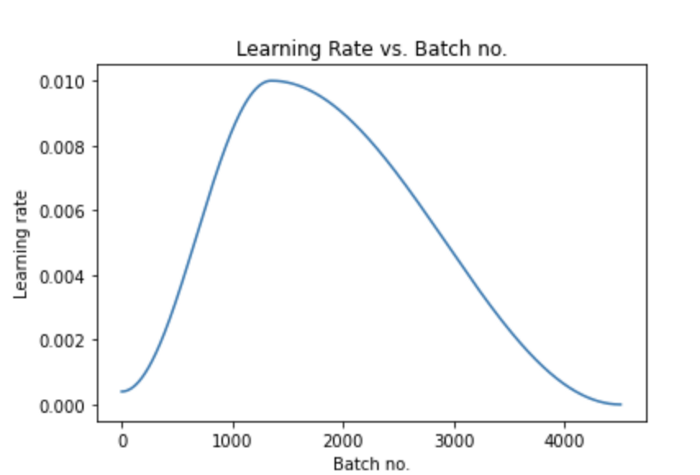
经过一些修改,我们的最终测试准确度进一步提高了6% 。
总结:




在这3种模型中,ResNet9的测试准确率最高,达到98.85% 。
未来工作:
数据转换(数据增强和归一化)
迁移学习
数据集:https://www.kaggle.com/moltean/fruits
代码链接:https://jovian.ml/limyingying2000/fruitsfinal
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看