
【深度学习】百度:YOLOX和NanoDet都没我优秀!轻量型实时目标检测模型PP-PicoDet开源
导读
百度提出新型移动端实时检测模型PP-PicoDet。本文对anchor-free策略在轻量型检测器中的应用进行了探索;对骨干结构进行了增强并设计了一种轻量Neck部件;同时对SimOTA策略与Loss进行了改进。通过上述改进,所提PP-PicoDet取得了超越其他实时检测模型的性能。

论文链接:https://arxiv.org/abs/2111.00902
代码链接:https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.3/configs/picodet
比YOLOX还要优秀,百度提出新型移动端实时检测模型PP-PicoDet。本文对anchor-free策略在轻量型检测器中的应用进行了探索;对骨干结构进行了增强并设计了一种轻量Neck部件;同时对SimOTA策略与Loss进行了改进。通过上述改进,所提PP-PicoDet取得了超越其他实时检测模型的性能。比如:PicoDet-S仅需0.99M参数即可取得30.6%mAP,比YOLOX-Nano高4.8%同时推理延迟降低55%,比NanoDet指标高7.1%,同时推理速度高达150fps(骁龙865)。
Abstract
更佳的精度-效率均衡已成为目标检测领域极具挑战性问题。本文致力于目标检测的关键技术优化与架构选择以提升其性能与效率。
我们对anchor-free策略在轻量型目标检测模型中的应用进行了探索;我们对骨干结构进行了增强并设计了一种轻量型Neck结构以提升模型的特征提取能力;我们对label assignment策略与损失函数进行了改进以促进更稳定、更高效的训练。通过上述优化,我们构建了一类实时目标检测器PP-PicoDet,它在移动端设备上取得了非常优异的性能。
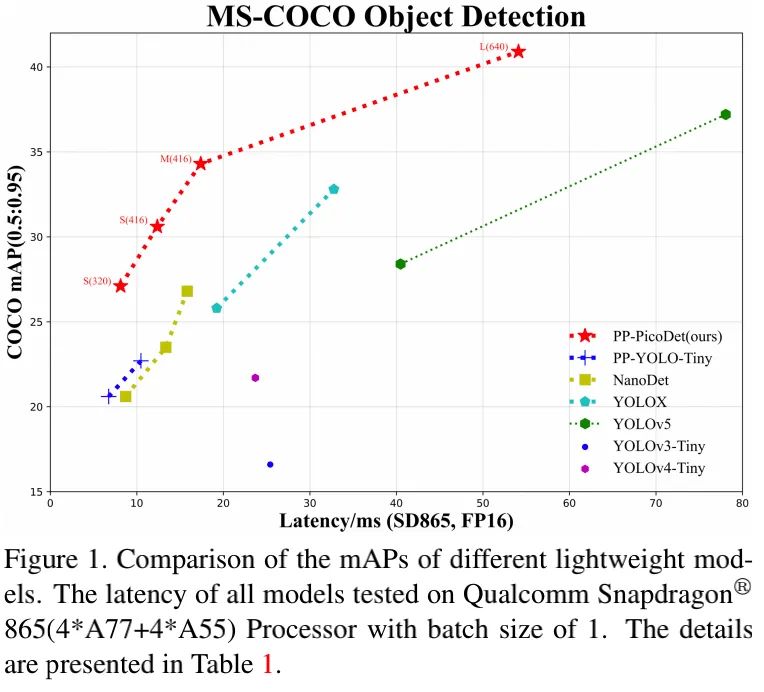
相比其他主流检测模型,所提方案取得了更好的精度-效率均衡。比如
PicoDet-S仅需0.99M参数即可取得30.6%mAP,比YOLOX-Nano高4.8%同时推理延迟降低55%,比NanoDet指标高7.1%;当输入尺寸为320时,在移动端ARM CPU上可以达到123FPS处理速度,推理框架为PaddleLite时,推理速度可达150FPS。
PicoDet-M仅需2.15M参数即可取得34.3%mAP指标;
PicoDet-L仅需3.3M参数即可取得40.9%mAP,比YOLOv5s高3.7%mAP,推理速度快44%。
如下图所示,所提方案具有最佳的精度-效率均衡。
Contribution
本文贡献主要包含以下几点:
采用CSP架构构建CSP-PAN,它通过卷积对所有分支输入通道进行统一,大幅提升特征提取能力,同时减少了参数量。与此同时,我们将深度卷积从扩展到提升感受野;
label assignment是目标检测非常重要的模块。我们在SimOTA的基础上对某些计算细节进行了优化,在不损失效率的同时增强了性能。具体来说,我们采用VarifocalLoss与GIoULoss的加权组合计算损失矩阵 。
ShuffleNetV2在移动端非常高效,我们对其进行了增强并提出一种新的骨干ESNet(Enhanced ShuffleNet, ESNet);
提出一种用于检测的改进版One-Shot NAS方案以寻找最佳的架构。
Method
接下来,我们将首先呈现设计思路与NAS搜索方案,这有助于提升精度、降低推理延迟;然后我们再介绍关于Neck与Head模块的增强策略;最后我们对Label Assignment以及其他提升性能的策略进行介绍。
Better Backbone
实验发现:相比其他模型,ShuffleNetV2在移动端具有更好的鲁棒性 。为提升ShuffleNetV2的性能,我们参考PP-LCNet对其进行了增强并构建一种新的骨干ESNet。
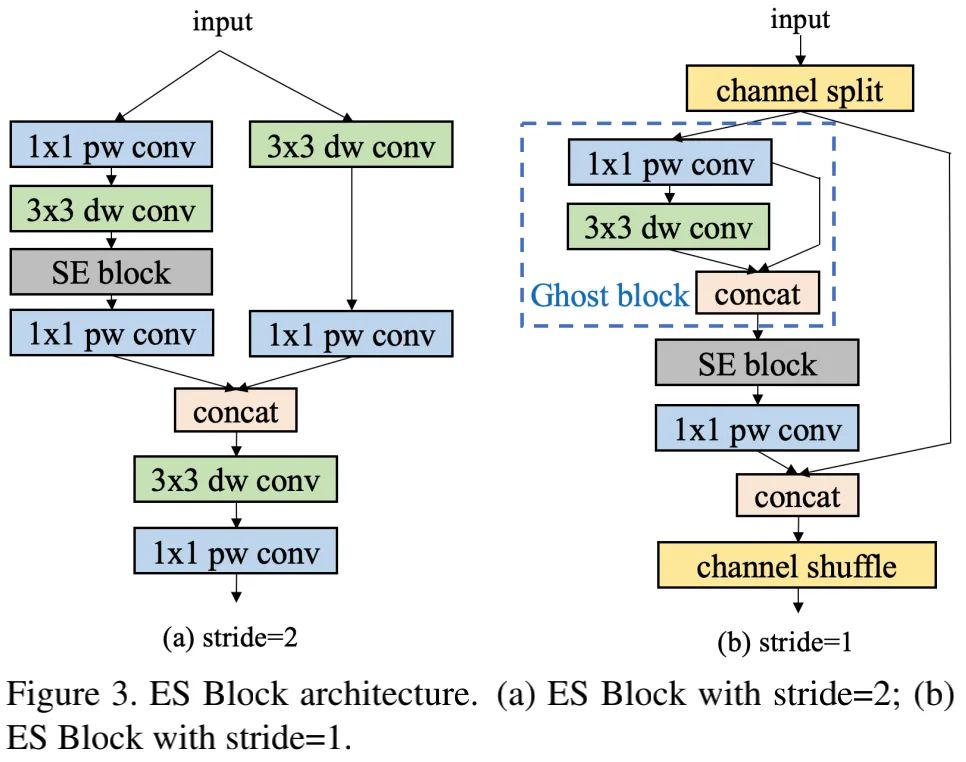
上图给出了ESNet中的ESBlock结构示意图。SE是一种非常棒的提升特征表达能力的操作,故ESBlock中包含了SE模块。SE模块的设计参考了MobileNetV3,即两个激活函数分别为Sigmoid、H-Sigmoid。
通道置换为ShuffleNetV2中的通道提供了信息交换,但它会导致融合特征损失。为解决该问题,当stride=2时,我们添加了depth与point卷积对不同通道信息进行融合(见上图3-a)。
GhostNet中的Ghost模块能够用更少的参数生成更多特征并提升模型的学习能力。因此,当stride=1时,我们在ESBlock中引入Ghost模块以提升其性能(见上图3-b)。
上述部分内容是手工方式的模块设计,文中还用到了NAS技术对ESNet进行搜索以更好的适配检测模型。对该部分内容感兴趣的同学建议查看原文,笔者对此暂时略过。
CSP-PAN and Detector Head
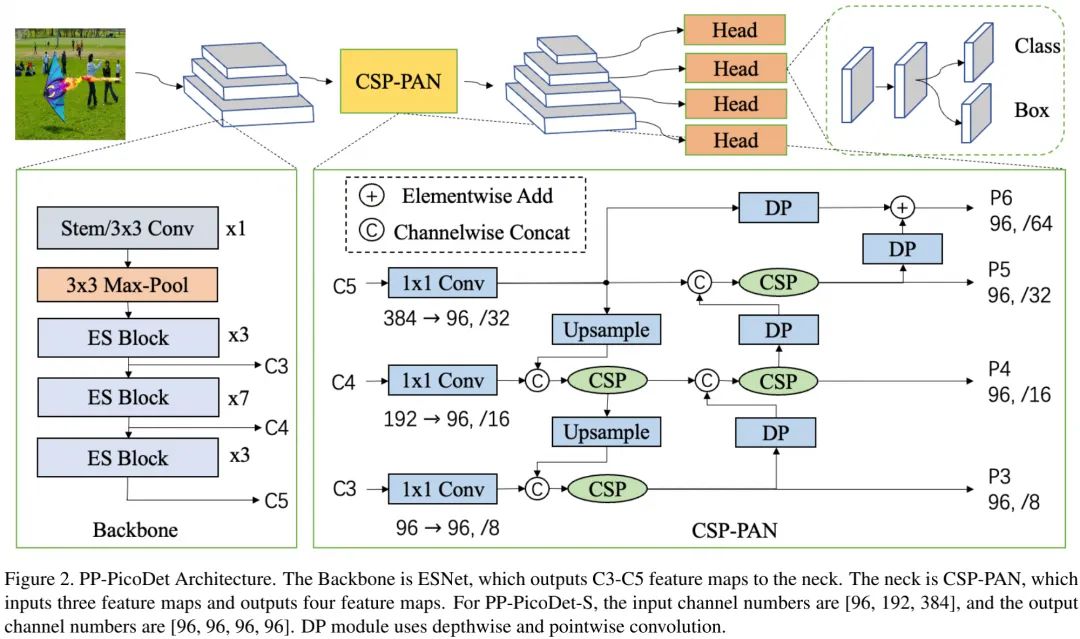
上图给出了PP-PicoDet整体架构示意图。接下来,我们重点关注CSP-PAN与Head部分。CSP结构已被广泛应用于YOLOv4与YOLOX的Neck部分。
在原始CSP-PAN中,每个输出特征的通道数与源自骨干的输入通道数保持相同。大通道数的结构在移动端存在昂贵的计算消耗。我们通过 卷积将输出特征的通道数调整到最小通道数 以解决上述问题。
Top-down与bottom-up两路特征融合通过CSP结构执行。此外,我们还在CSP-PAN的基础上添加了一个特征尺度以检测更多目标(见上图P6分支)。与此同时,除了卷积外,其他卷积均为深度卷积。这种结构设计可以带来可观的性能提升,同时参数量更少。
在检测头部分,我们采用深度分离卷基于卷积提升感受野。深度分离卷积的数量可以设置为2、4或者更多。Neck与Head均具有四个尺度分支,我们保持两者的通道数一致。YOLOX采用更少通道数的“解耦头”提升性能;而PP-PicoDet的“耦合头”具有更好的性能,且无需减少通道数 。该方案的Head与YOLOX的Head具有几乎相同的参数量和推理速度。
Label Assignment Strategy and Loss
正负样本的标签分类对于目标检测器有着非常重要的影响。RetinaNet通过IoU进行正负样本划分;FCOS则将中心点位于GT的anchor视作正样本;YOLOv4与YOLOv5则选择中心点与近邻anchor作为正样本;ATSS则通过统计信息进行正负样本划分;SimOTA则是一种随训练过程而动态变换的标签分配策略,具有更好的性能。因此,我们选择SimOTA作为标签分配方案。
在SimOTA的基础上,我们对其cost矩阵进行优化,采用VarifocalLoss与GIoULoss的加权组合计算。定义如下:
对于分类头,我们采用VarifocalLoss耦合分类预测与质量预测;对于回归头,我们采用GIoU与DistributionFocalLoss。整体损失定义如下:
Other Strategies
近年来,越来越多的激活函数取得了比ReLU更优的性能。其中,H-Swish是一种移动端友好的算子,故我们将检测器中的ReLU替换为H-Swish,性能大幅提升同时推理速度不变 。
相比线性学习率机制,cosine 学习率机制更为平滑且有益于训练稳定性。
过多的数据增强可以提升增强效应,但会影响轻量型模型的训练难度。因此,我们仅使用RandomFlip, RandomCrop, Multi-scale Resize等数据增广。
Experiments
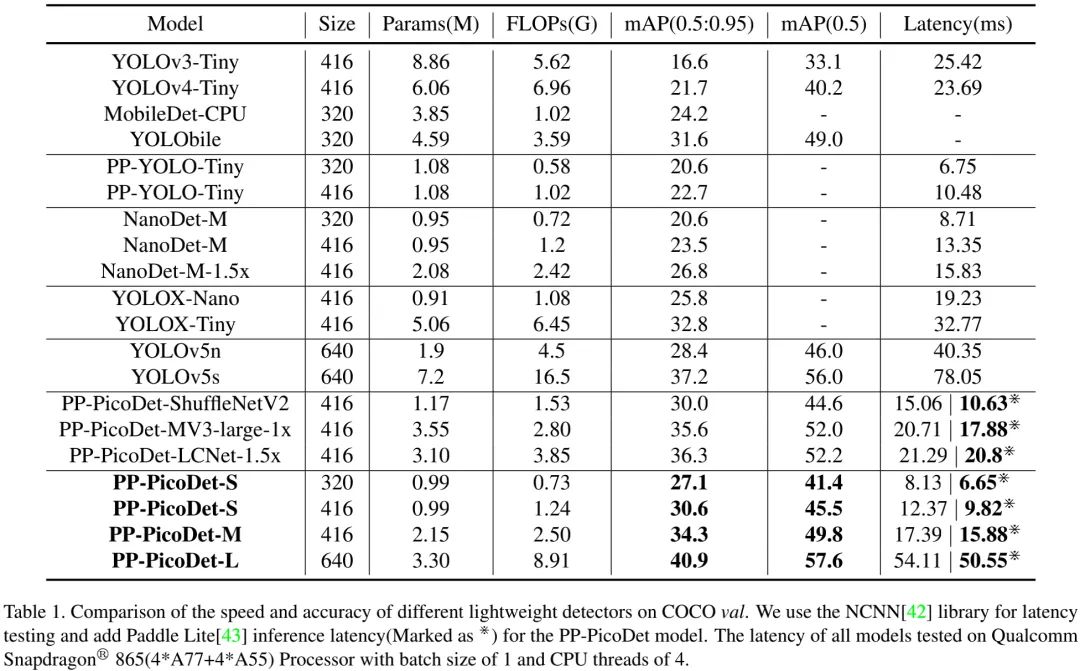
上表给出了所提方案与其他轻量型检测器的性能对比,从中可以看到:无论是精度还是速度,所提方案均大幅超越了所有YOLO模型 。性能的提升主要源于以下几点改进:
Neck部分比其他YOLO模型更轻量,故骨干与Head可以赋予更多计算量;
VarifocalLoss的组合可以处理类别不平衡、动态学习样本分类与FOCS的回归方案在轻量模型中表现更佳;
在相同参数量下,PP-PicoDet-S超越了YOLOX-Nano与NanoDet;PP-PicoDet-L的精度与速度均超越了YOLOv5s。此外,由于更高效的卷积优化,PaddleLite的推理速度要比NCNN更快。总而言之,PP-PicoDet在极大程度上领先其他SOTA模型。
Ablation Study
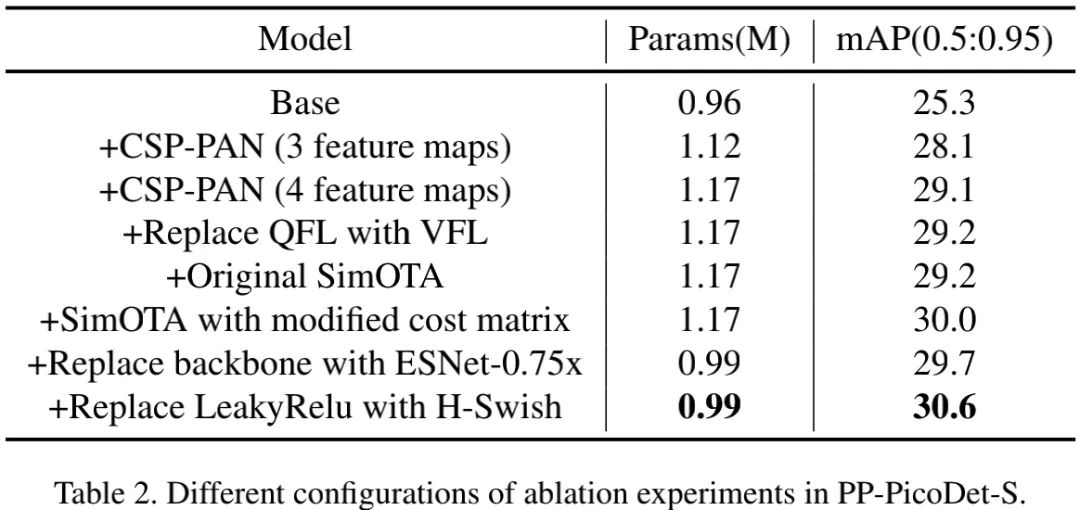
上表给出了PP-PicoDet从基线模型逐步优化而来的性能对比。基线模型类似NanoDet,骨干为ShuffleNetV2-1x,Neck采用了无卷积PAN,损失采用了GFL,标签分配采用ATSS,激活函数为LeakyReLU。从中可以看到:
采用本文所提CSP-PAN可以带来3.8%mAP指标提升,而参数量提升少于50K;
相比QFL,VFL可以带来0.1%mAP指标提升;
ATSS与SimOTA具有相同的性能,而改进版SimOTA可以将性能提升到30.0%mAP;
相比LeakyReLU,H-Swish可以带来0.9%mAP指标提升。

上表对比了ShuffleNetV2-1.5x与ESNet-1x的性能,可以看到:ESNet具有更高的性能、更快的推理速度、更少的计算量。
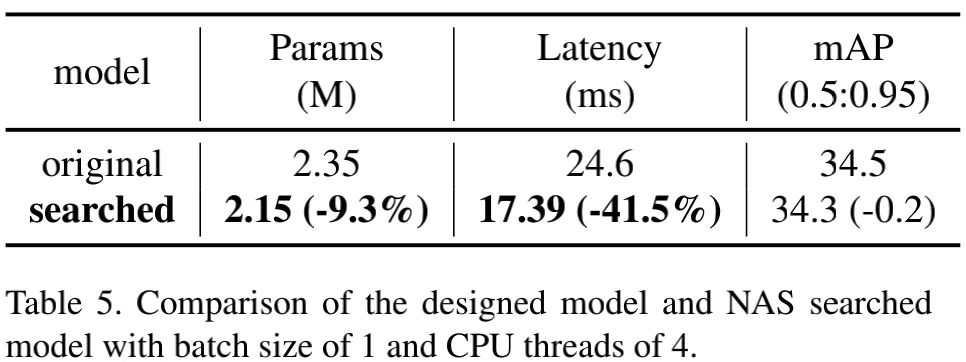
上表对比了人工设计模型与NAS搜索模型的性能,可以看到:搜索到的模型的指标仅下降0.2%mAP,而推理延迟减少41.5% 。因此,我们将基线模型的骨干替换为ESNet-0.75x,参数量减少约200K,而性能仅下降0.3%mAP。
如果觉得有用,就请分享到朋友圈吧!
往期精彩回顾 本站qq群554839127,加入微信群请扫码: