
重磅开源!新一代最强目标检测模型YOLOX!
导读
YOLO系列终于又回到了Anchor-free的怀抱,不用费劲心思去设计anchor了!旷视开源新的高性能检测器YOLOX,本文将近两年来目标检测领域的各个角度的优秀进展与YOLO进行了巧妙地集成组合,性能大幅提升。

paper: https://arxiv.org/abs/2107.08430
code: https://github.com/Megvii-BaseDetection/YOLOX
本文是旷视科技在目标检测方面的最新技术总结,同时也是CVPR2021自动驾驶竞赛冠军方案的技术总结。本文将近两年来目标检测领域的各个角度的优秀进展与YOLO进行了巧妙地集成组合(比如解耦头、数据增广、标签分配、Anchor-free机制等)得到了YOLOX,性能取得了大幅地提升,同时仍保持了YOLO系列一贯地高效推理。此外值得一提的是,YOLO系列终于又回到了Anchor-free的怀抱,不用费劲心思去设计anchor了。
Abstract
本文针对YOLO系列进行了一些经验性改进,构建了一种新的高性能检测器YOLOX。本文将YOLO检测器调整为了Anchor-Free形式并集成了其他先进检测技术(比如decoupled head、label assignment SimOTA)取得了SOTA性能,比如:
对于YOLO-Nano,所提方法仅需0.91M参数+1.08G FLOPs取得了25.3%AP指标,以1.8%超越了NanoDet; 对于YOLOv3,所提方法将指标提升到了47.3%,以3%超越了当前最佳; 具有与YOLOv4-CSP、YOLOv5-L相当的参数量,YOLOX-L取得了50.0%AP指标同事具有68.9fps推理速度(Tesla V100),指标超过YOLOv5-L 1.8%; 值得一提的是,YOLOX-L凭借单模型取得了Streaming Perception(Workshop on Autonomous Driving at CVPR 2021)竞赛冠军。
此外,值得一提的,该方法的ONNX、TensorRT、NCNN、OpenVino推理模型均已开源,为什么还不去体验一把呢???

YOLOX
YOLOX-DarkNet53
我们选择YOLOv3+DarkNet53作为基线,接下来,我们将逐步介绍YOLOX的整个系统设计。
Implementation Details 我们的训练配置从基线模型到最终模型基本一致。在COCO train2017上训练300epoch并进行5epoch的warm-up。优化器为SGD,学习率为,初始学习率为0.01,cosine学习机制。weight decay设置为0.0005,momentum设置为0.9, batch为128(8GPU)。输入尺寸从448以步长32均匀过渡到832. FPS与耗时采用FP-16精度、bs=1在Tesla V100测试所得。
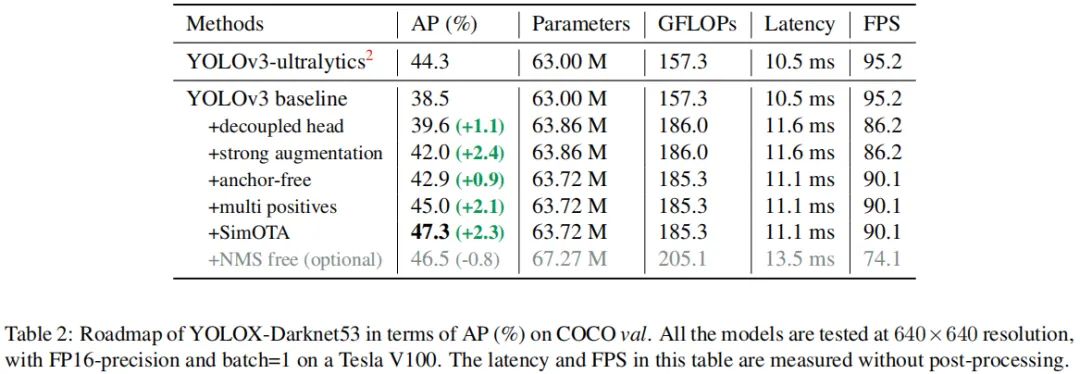
YOLOv3 baseline 基线模型采用了DarkNet53骨干+SPP层(即所谓的YOLOv3-SPP)。我们对原始训练策略进行轻微调整:添加了EMA权值更新、cosine学习率机制、IoU损失、IoU感知分支。我们采用BCE损失训练cls与obj分支,IoU损失训练reg分支。这些广义的训练技巧与YOLOX的关键改进是正交的,因此,我们将其添加到baseline中。此外,我们添加了RandomHorizontalFlip、ColorJitter以及多尺度数据增广,移除了RandomResizedCrop。基于上述训练技巧,基线模型在COCO val上取得了38.5%AP指标,见Figure2.
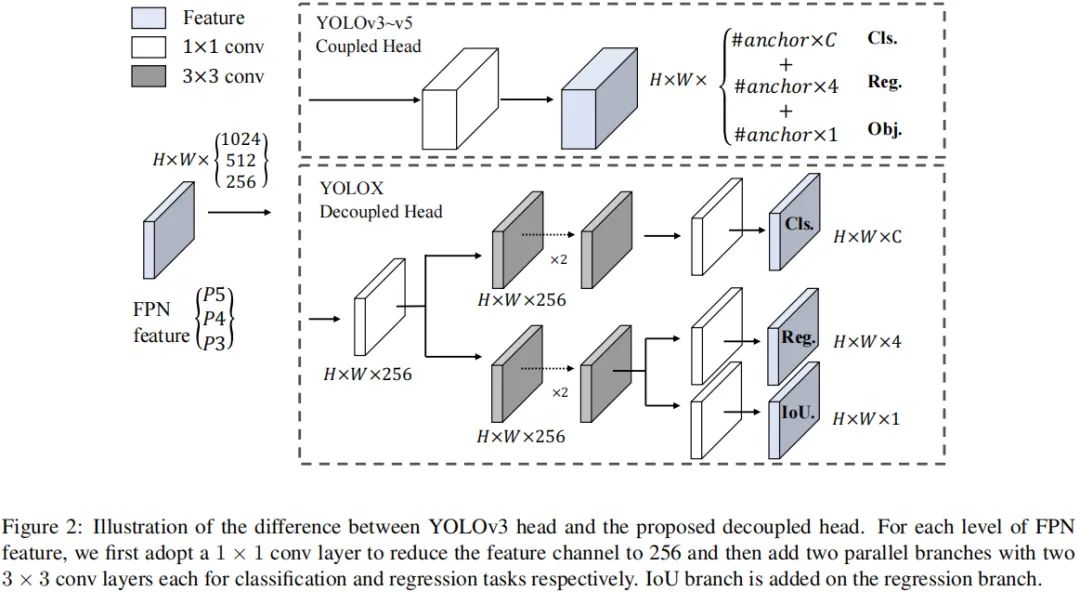
Decoupled Head 在目标检测中,分类与回归任务的冲突是一种常见问题。因此,分类与定位头的解耦已被广泛应用到单阶段、两阶段检测中。然而,随着YOLO系列的骨干、特征金字塔的进化,单其检测头仍处于耦合状态,见上图。
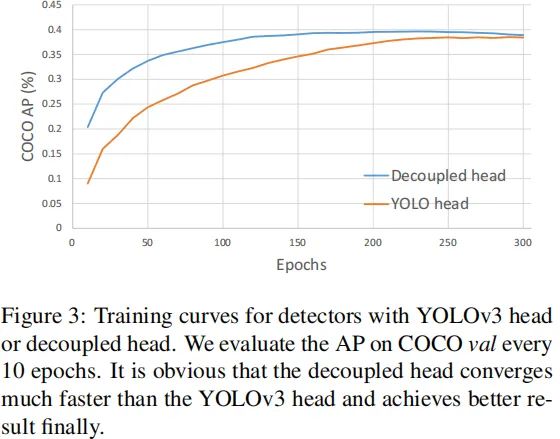
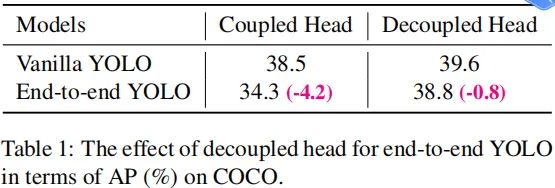
我们分析发现:检测头耦合会影响模型性能。采用解耦头替换YOLO的检测头可以显著改善模型收敛速度,见上图。解耦头对于端到端版本YOLO非常重要,可参考下表。因此,我们将YOLO的检测头替换为轻量解耦头,见上面的Figure2:它包含一个卷积进行通道降维,后接两个并行分支(均为卷积)。注:轻量头可以带来1.1ms的推理耗时。
Strong data augmentation 我们添加了Mosaic与Mixup两种数据增广以提升YOLOX的性能。Mosaic是U版YOLOv3中引入的一种有效增广策略,后来被广泛应用于YOLOv4、YOLOv5等检测器中。MixUp早期是为图像分类设计后在BoF中进行修改用于目标检测训练。通过这种额外的数据增广,基线模型取得了42.0%AP指标。注:由于采用了更强的数据增广,我们发现ImageNet预训练将毫无意义,因此,所有模型我们均从头开始训练。
Anchor-free YOLOv4、YOLOv5均采用了YOLOv3原始的anchor设置。然而anchor机制存在诸多问题:(1) 为获得最优检测性能,需要在训练之前进行聚类分析以确定最佳anchor集合,这些anchor集合存在数据相关性,泛化性能较差;(2) anchor机制提升了检测头的复杂度。
Anchor-free检测器在过去两年得到了长足发展并取得了与anchor检测器相当的性能。将YOLO转换为anchor-free形式非常简单,我们将每个位置的预测从3下降为1并直接预测四个值:即两个offset以及高宽。参考FCOS,我们将每个目标的中心定位正样本并预定义一个尺度范围以便于对每个目标指派FPN水平。这种改进可以降低检测器的参数量于GFLOPs进而取得更快更优的性能:42.9%AP。
Multi positives 为确保与YOLOv3的一致性,前述anchor-free版本仅仅对每个目标赋予一个正样本,而忽视了其他高质量预测。参考FCOS,我们简单的赋予中心区域为正样本。此时模型性能提升到45.0%,超过了当前最佳U版YOLOv3的44.3%。
SimOTA 先进的标签分配是近年来目标检测领域的另一个重要进展。基于我们的OTA研究,我们总结了标签分配的四个关键因素:(1) loss/quality aware; (2) center prior; (3) dynamic number of positive anchors; (4) global view。OTA满足上述四条准则,因此我们选择OTA作为候选标签分配策略。具体来说,OTA从全局角度分析了标签分配并将其转化为最优运输问题取得了SOTA性能。
然而,我们发现:最优运输问题优化会带来25%的额外训练耗时。因此,我们将其简化为动态top-k策略以得到一个近似解(SimOTA)。SimOTA不仅可以降低训练时间,同时可以避免额外的超参问题。SimOTA的引入可以将模型的性能从45.0%提升到47.3%,大幅超越U版YOLOv的44.3%。
End-to-End YOLO 我们参考PSS添加了两个额外的卷积层,one-to-one标签分配以及stop gradient。这些改进使得目标检测器进化成了端到端形式,但会轻微降低性能与推理速度。因此,我们将该改进作为可选模块,并未包含在最终模型中。
Other Backbones
除了DarkNet53外,我们还测试其他不同尺寸的骨干,YOLOX均取得了一致的性能提升。
Modified CSPNet in YOLOv5 为公平对比,我们采用了YOLOv5的骨干,包含CSPNet、SiLU激活以及PAN头。我们同样还延续了其缩放规则得到了YOLOX-S、YOLOX-M、YOLOX-L以及YOLOX-X等模型。对比结果见下表,可以看到:仅需非常少的额外的推理耗时,所提方法取得了3.0%~1.0%的性能提升。

Tiny and Nano detectors 我们进一步收缩模型得到YOLOX-Tiny以便于与YOLOv4-Tiny对比。考虑到端侧设备,我们采用深度卷积构建YOLOX-nano模型,它仅有0.91M参数量+1.08GFLOPs计算量。性能对比见下表,可以看到:YOLOX在非常小的模型尺寸方面表现仍然非常优异。
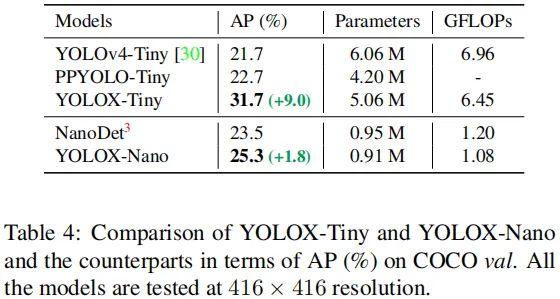
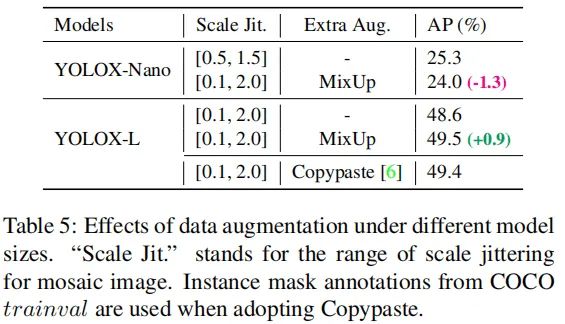
Model size and data augmentation 在所有实验中,我们让所有模型保持几乎相同的学习率机制和优化参数。然而,我们发现:合适的增广策略会随模型大小而变化。从下表可以看到:MixUp可以帮助YOLOX-L取得0.9%AP指标提升,但会弱化YOLOX-Nano的性能。基于上述对比,当训练小模型时,我们移除MixUp,并弱化Mosaic增广,模型性能可以从24.0%提升到25.3%。而对于大模型则采用默认配置。
Comparison with the SOTA

上表对比了所提YOLOX与其他SOTA检测器的性能对比,从中可以看到:相比YOLOv3、YOLOv4、YOLOv5系列,所提YOLOX取得了最佳性能,同时具有极具竞争力的推理速度。考虑到上表中推理速度的不可控因素,我们在同一平台上进行了统一对比,见下图。所以,YOLOX就是目标检测领域高性能+高速度的新一代担当。
1st Place on Streaming Perception Challenge

上图截取自CVPR自动驾驶竞赛官网,本文所提YOLOX(BaseDet)取得了冠军。所提交的模型为YOLOX-L,推理采用了TensorRT,推理速度小于33ms。
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
往期精彩:
Swin Transformer:基于Shifted Windows的层次化视觉Transformer设计
TransUNet:基于 Transformer 和 CNN 的混合编码网络
ViT:视觉Transformer backbone网络ViT论文与代码详解
求个在看