
基于机器视觉的典型多目标追踪算法应用实践
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转自:Deepexi滴普科技
视频目标追踪算法是机器视觉中一项很实用重要的算法,视频目标追踪算法应用场景很广,比如智能监控、机器人视觉系统、虚拟现实(人体跟踪)、医学诊断(细胞状态跟踪)等。本文由滴普科技2048团队AI产品部算法工程师朱晓丽介绍基于机器视觉的典型多目标追踪算法应用实践。
一、概 述
MOT的分类
MOT常用评价标准
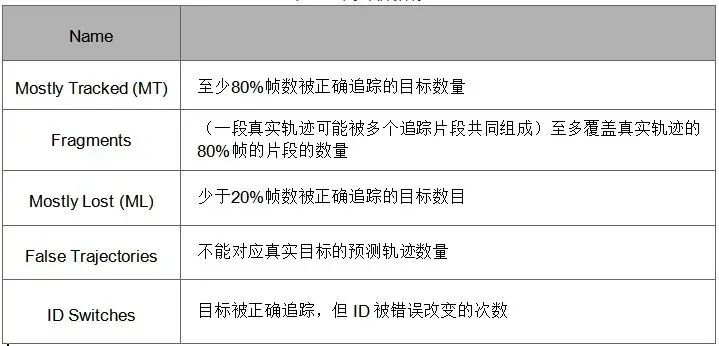
表1. 常用评价指标
MOT的难点

图1 MOT算法处理步骤
Sort(Simple nline and real time tracking)
Deep Sort(Deep simple online and realtime tracking)
FairMot(A simple baseline for multi-object tracking)
Graphnn Multi-object Trachking。(后面简写为Graphnn-mot)
二、典型的追踪算法介绍
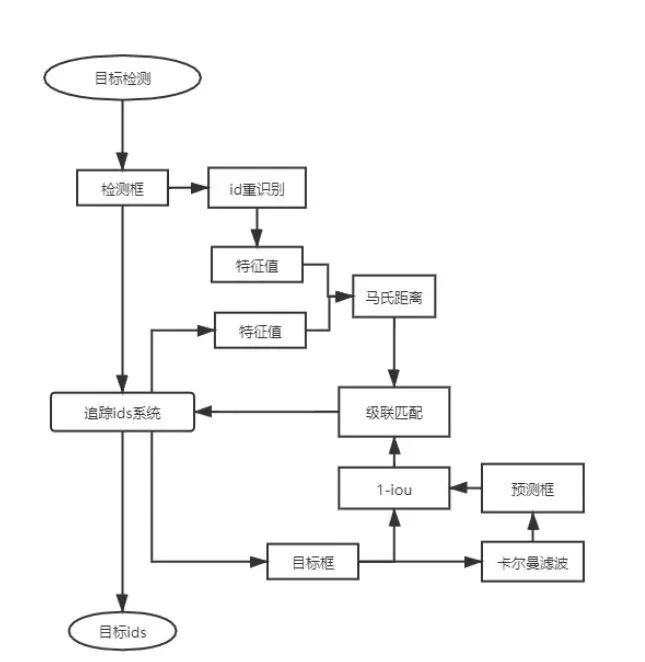
图2. Deep Sort算法的简单流程图
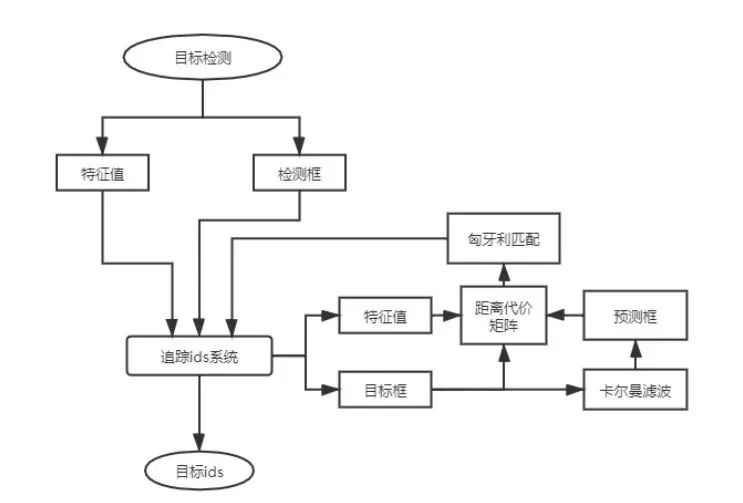
图3. FairMot算法的简单流程图
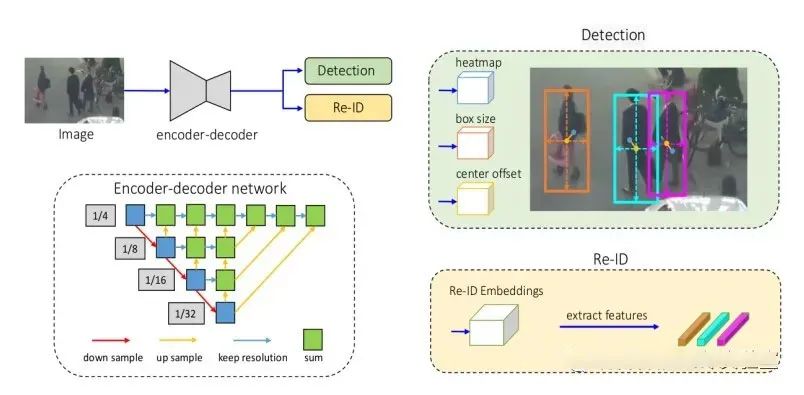
图4. FairMot网络结构及检测示意图
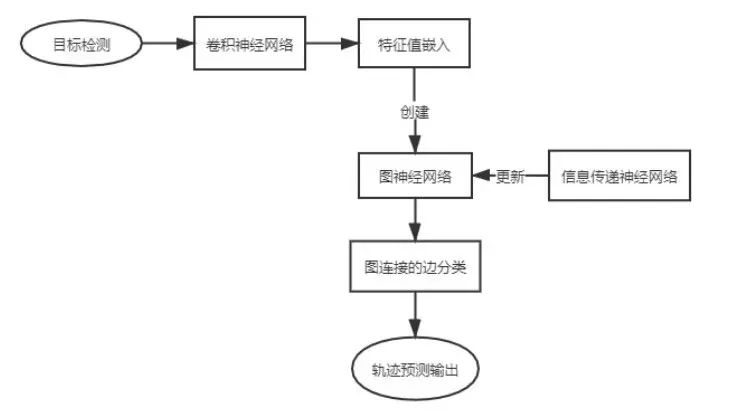
图5. Graphnn-mot算法的处理流程
三、实际算法测试分析
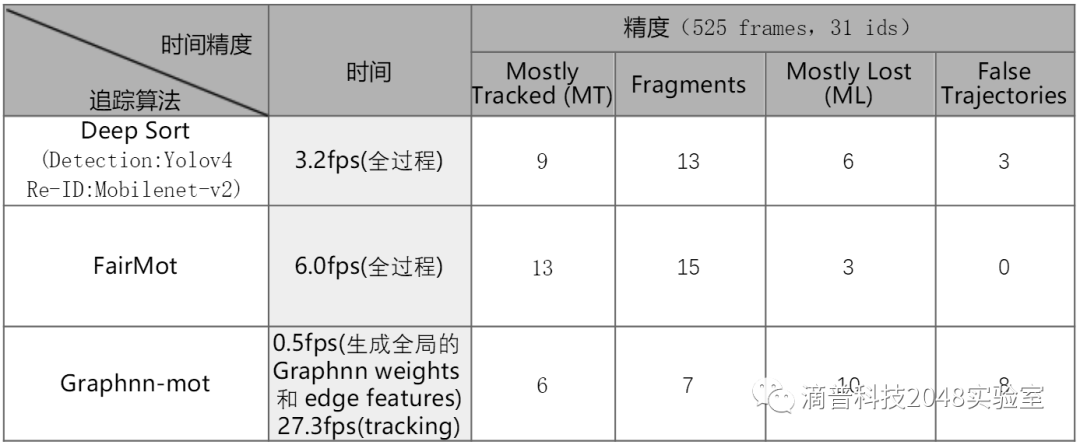
表2. 追踪算法实际测试的时间和精度(精度含义见表1)

组图1:拥挤场景中的graphnn mot追踪算法

组图2:拥挤场景中的deep sort追踪算法

组图3:拥挤场景中的farimot追踪算法

组图4:graphnn追踪算法目标检测漏检示例图
四、总结
参考文献
[1] Multiple Object Tracking: A Literature Review. https://arxiv.org/abs/1409.7618
[2] Deep Learning in Video Multi-Object Tracking: a Survey. https://arxiv.org/pdf/1907.12740.pdf
[3] YOLOv4: Optimal Speed and Accuracy of Object Detection. https://arxiv.org/pdf/2004.10934v1.pdf
[4] MobileNetV2: Inverted Residuals and Linear Bottlenecks. https://arxiv.org/abs/1704.04861
[5] Deep Residual Learning for Image Recognition. https://arxiv.org/abs/1512.03385
[6] Deep Layer Aggregate. https://arxiv.org/pdf/1707.06484.pdf
[7] Feature Pyramid Networks for Object Detection. https://arxiv.org/pdf/1612.03144.pdf
[8] A Comprehensive Survey on Graph Neural Networks. https://arxiv.org/abs/1901.00596
[9] Simple Online and Realtime Tracking with a Deep Association Metric. https://arxiv.org/pdf/1703.07402.pdf
[10] FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking.https://arxiv.org/pdf/2004.01888.pdf
[11] Learning a Neural Solver for Multiple Object Tracking. https://arxiv.org/pdf/1912.07515.pdf
[12] Towards Real-Time Multi-object tracking. https://arxiv.org/pdf/1909.12605v1.pdf
[13] Real-Time Multi People Tracking with Deeply Learned Candidate Selection and Person Re-Identification. https://arxiv.org/abs/1809.04427
[14] http://www.deepexi.com/
附录
1. 测试条件与环境
环境配置:
ubuntu 20.04.4LTS 单卡GTX1060 CUDA Version 10.1.
python=3.8.3 opencv-python=4.3.0.36 pytorch=1.4 torchvision cudatoolkit=10.1.243
数据集:
public dataset: MOT2017-MOT2020 crowdhuman 用于detection模型训练和测试
CUHK03 Market1501 DukeMTMC-reID MSMT17用于reID模型训练