
谈谈嵌入式视觉的几个典型应用
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
引言
如何做AI视觉应用的嵌入式部署分为硬件选型,软件框架和优化的选择,模型算法的设计三大板块。
AI视觉应用云端部署VS嵌入式端部署

大家其实对于AI深度学习已经很熟悉了,我们在服务器上就可以用GPU或者Tensorflow来做训练,训练完之后要做推理计算。推理最简单的一个方法就是放在云端,用云端推理的板卡比如NVIDIA的T4或者国产NPU做推理计算。在云端,推理计算是广泛使用的。百度的API或者Face++等云端API是在前端探测数据,把视频图像传回云端,云端做完处理返回结果,这就是云端的部署。
嵌入式部署其实和云端部署很相似,只不过是在最后把模型发送到了嵌入式设备上(手机和无人机),那它是在手机和无人机上来做推理计算,这就是我们认为嵌入式部署的AI使用模型情况。
嵌入式视觉典型应用

列举几个典型的嵌入式视觉应用。
第一个是辅助驾驶或者自动驾驶,在驾驶的车上会有AI处理加速的模块,应用了AI算法。在这种场景下做AI的嵌入式部署主要是为了环境的感知、目标的检测追踪或者在无人机上可能会做视觉或激光的SLAM,为了在嵌入式端实现高实时性。
第二个是手机的美颜和AR。预览和编辑操作都是在手机本地完成的,它其实是完成了更好的交互性,给用户的体验性更好。从另一方面对于手机APP公司来说,是更加节省成本的,比如你编辑一段视频,这里的AR操作返回给服务器来做,成本是很高的。
第三个是边缘智能化盒子,优势是兼容了已有的摄像头。在安防场景和智能社区里已有很多传统的摄像头,但使用边缘智能化盒子,能够处理多路且兼容已有摄像头,从节省成本上来说也是一个好的选择。
嵌入式AI硬件选型
Intel CPU或NVIDIA GPU

嵌入式AI的硬件是怎么选型的?
第一个常见的类型是工控机,用X86的CPU加上NVIDIA的GPU,这种好处就是生态分层成熟。如果是纯CPU的应用,深度学习一类的应用算力可能会偏弱。
第二个是NVIDIA的TX2和Nano系列,NVIDIA对于嵌入式的AI有专门的这种SoC的芯片,也出了很多板卡,相对成本低,算力也比服务器低。GPU支持了FP16和FP32的精度,对于嵌入式部署是很有帮助的,意味着模型精度和服务器上训练的精度几乎能保持一致。服务器都是用32位做训练,如果说其他的NPU转换成Int8的话,必然会造成精度的损失。唯一的弱点就是主CPU偏弱,就只是ARM Cortex-A57的四核或多核。如果放在无人机上使用,无人机应用很多是很复杂的,不是深度学习或GPU就能加速的,这里用ARM Cortex-A57可能就会存在问题。这实际上是NVIDIA的嵌入式系列面临的一些挑战,主要是要评估组合性能是不是好。
AMD APU

目前AMD的处理器用的偏少。它的CPU比较好,能够对标到i7主屏比较高的CPU ,GPU也不错,比TX2的性能要提高2倍,整体性能还可以,也可以利用X86上面的生态,存在的问题是它的编程需要OpenCL,这比CUDA要弱,就是它存在深度学习的部署门槛。另外就是它这款盒子的功耗偏高,比NVIADA的TX2或Nano高一倍,但性能加强了。利用AMD的APU盒子放在驾校车上是比较好用的。
主流嵌入式AI开发板

大家也知道具备NPU的SoC芯片其实是越来越多的,之前是以加速卡的形式来存在,比如一个USB的NPU加速棒插在已有设备上。如果你是做嵌入式的部署,不要选择这种分离式的USB加速设备,因为它稳定性较差,另外数据传输比较麻烦。尽量选择集成在一起的带NPU的SoC,这是第一选择。目前带NPU的SoC也是越来越多的,厂商也越来越多。在华为芯片被禁之前,市面上主要的选择都是华为系列,大概有四款带NPU的,从低端的0.5T-1T算力,2T-4T算力都有覆盖。它的好处是成本相比较低,比NVIDIA的同样算力成本要低很多;第二个是它的ISP挑的比较好。下面的都是可以替换华为系列的,可以选择瑞芯微的RK3399、RK1808、RK3588或者全志等。
目前的NPU基本都是8bit量化,在8bit量化下模型精度是如何保证的,工具链的成熟度是一个问题,除此之外就是算力的选择。如果说想替换华为芯片,要求其他选型是性能超过2T算力,ISP不错,性价比不错的SoC选择目前是比较少的,至少在去年底来看还没有。
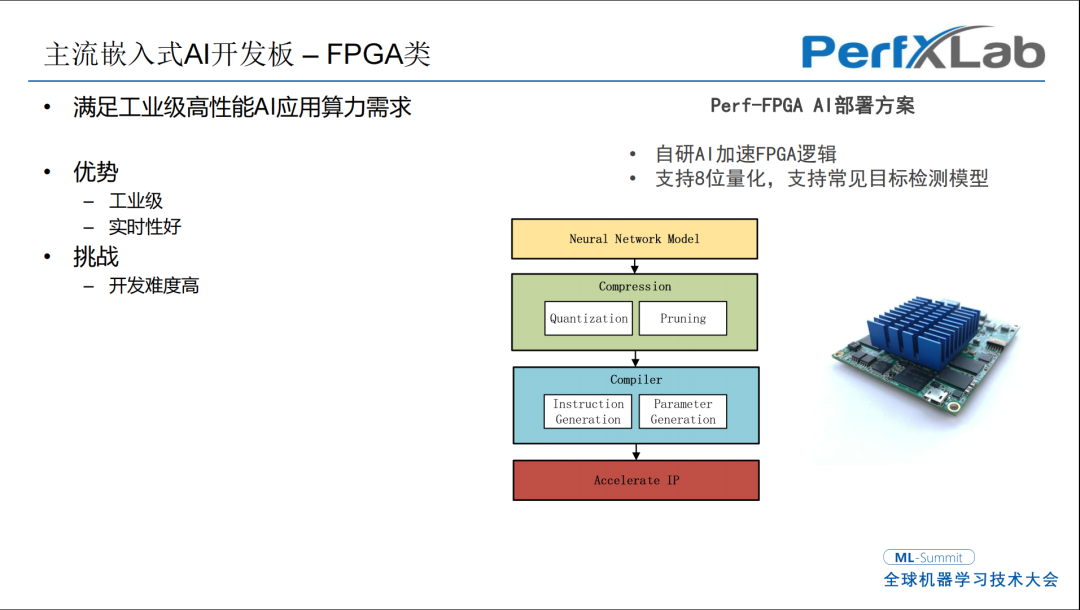
第三块常见的开发板工作是用FPGA来做AI计算,主要用在工业场景下,实时性更好。比如在野外、工业级的无人机或者研究所机构会要求国产FPGA达到毫秒级左右的实时性。这部分的FPGA基本上是要自研AI的加速软核。图中是我们自研的一个AI加速软核,它已经支持了很多常见的FPGA,AI加速软盒基本上结构都是这样。
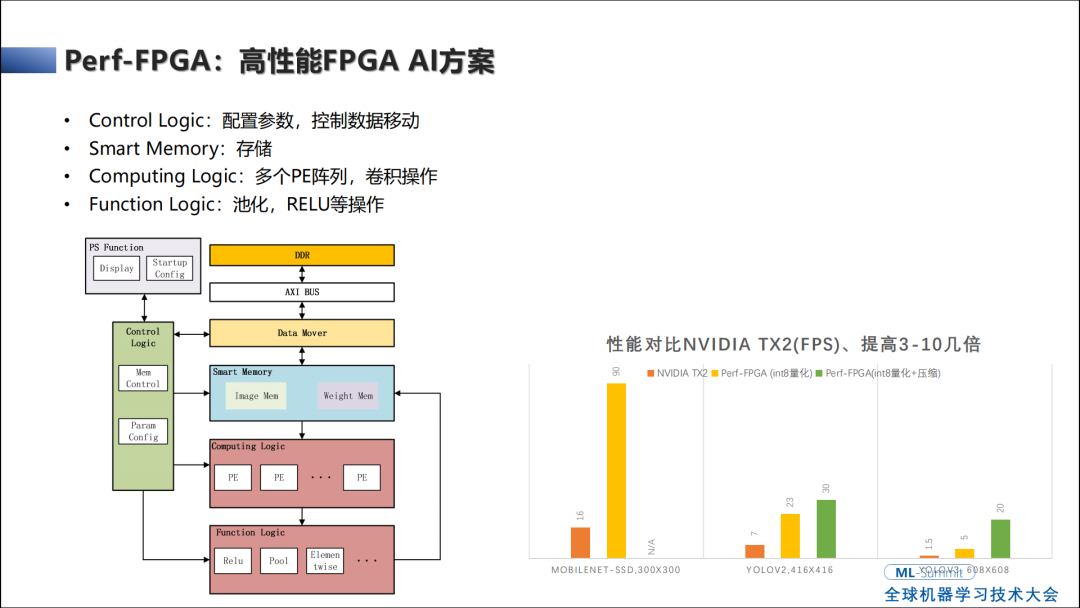
这部分IP是一个软核的IP,部署在FPGA资源上,核心部分有一个计算阵列,完成卷积操作。
如果NPU公司卷积只做一个3x3,就意味着这NPU是用不了的,虽然核心部分加速的很快,但是其他部分必须也是搬到NPU上才能整体的做嵌入式的部署和加速,所以就会需要有相应的部署模块缓冲数据。数据搬运需要把它从内存搬运到芯片的缓存上,控制逻辑相当于发指令的,控制调度、计算部件是怎么执行的,基本上NPU都是这几个部件组成的,具体的差别是在于并行度的方式不同,可能加了不同的加速部件来得到更好的性能。对于NPU来说第一个要考查是卷积性能到底怎么样,第二个算子是不是能支持的更多,支持的算子更多意味着在CPU端所跑的算子相对少一些而且支持的模型更多。

这个是我们实际用FPGA做了一些项目,做无人机,检测情况和可见光的处理,都是比较常用的。

在IoT级别的AI操作,我举的例子是法国的一家叫Greenwave公司,做的是无人机的一个自主的飞行控制。在性能方面差很多,基本上只能做到每秒18帧的处理速度,计算在100M Hz的功耗频率和6.5fps下整体的功耗是40mW,是非常低的功耗了。IoT级别还会使用在做智能门铃的场景下,以前的门铃只是用红外线检查是否有人过来,这个准确度不高。如果是加一个智能唤醒模块在门铃上,就可以提高判断的准确性,这是IoT级别的智能识别图像。
嵌入式AI软件性能优化
前向推理框架
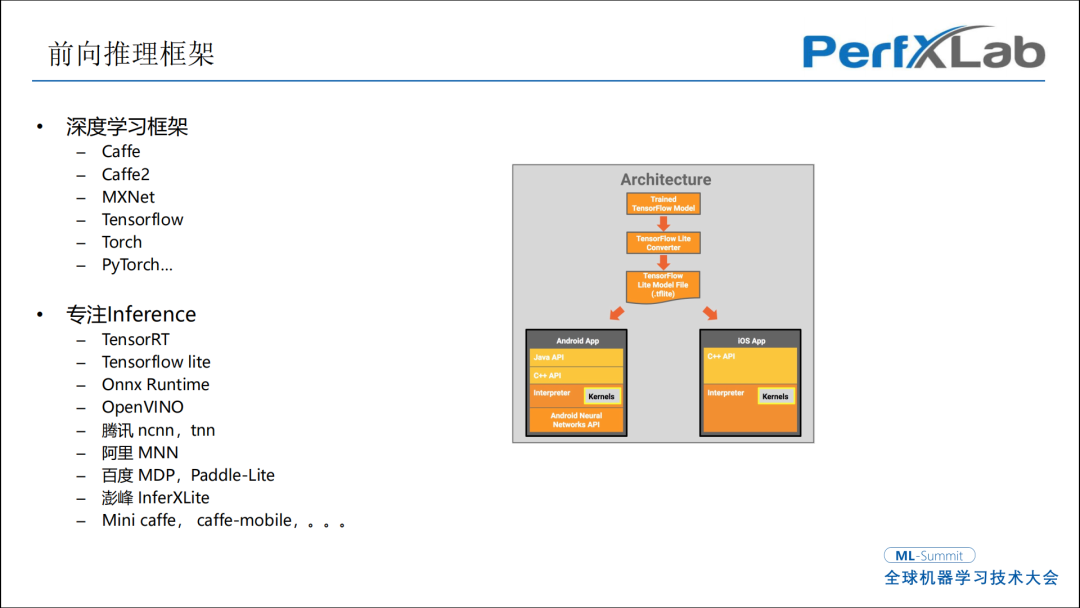
实际上在软件的推理框架上已经有非常多的选择了,有NVIDIA的TensorRT,Tensorflow lite,腾讯的NCNN,TNN,阿里MNN等等。图中是Tensorflow lite整体的图,从训练后的Tensorflow lite的网络模型中间会有一个转换步骤,转换到Tensorflow lite支持的网络结构,然后再嵌入到手机APP里。

前后推理框架的核心观点有五个。第一个是设备管理,比如现在的嵌入式SoC有GPU或者NPU,推理框架能支持这些设备。第二个是模型管理,单模型和多模型是不同的管理方式。第三个是内存管理和储存格式,要考虑是以优化内存占用优先还是以性能优先。第四个是层级融合,Barch Norm层可以和卷积层合并,当算子层中之间融合的越多,节省仿存的操作来发挥更多的效率。第五个是实现方法选择,这块需要框架要来处理,根据不同的输入特性来选择不同的实现算子优化的方法,来达到最高的效率。
性能评价
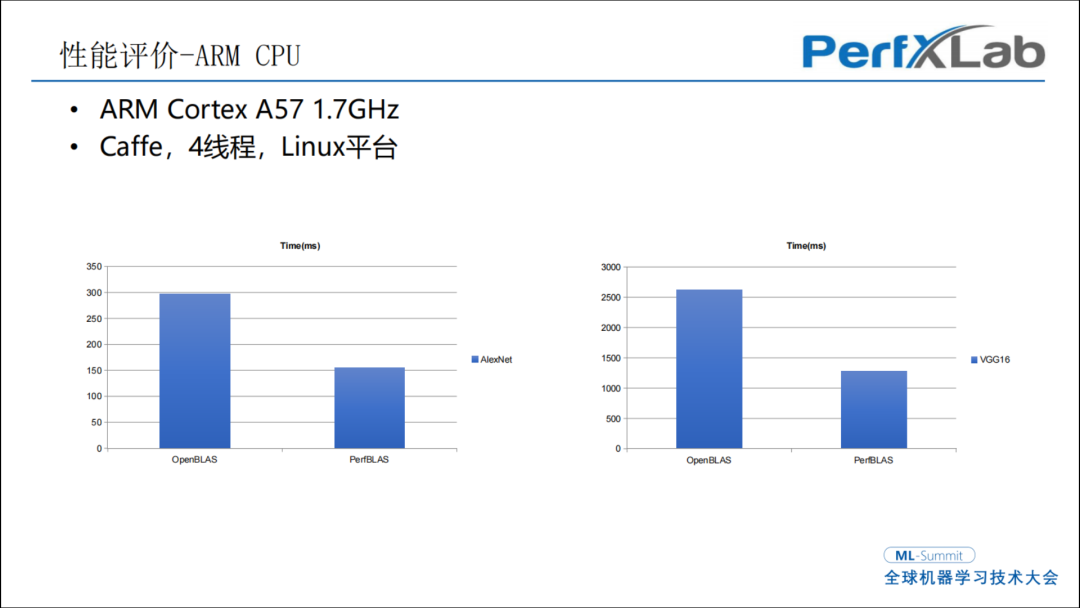
看一下这个性能对比的例子,从算子优化上其实就可以做到不少的性能提升,在算子上针对卷积算子做了优化,在同样的一个嵌入式的平台,获得了一倍的性能提升,硬件是完全相同的,就靠软件来做。
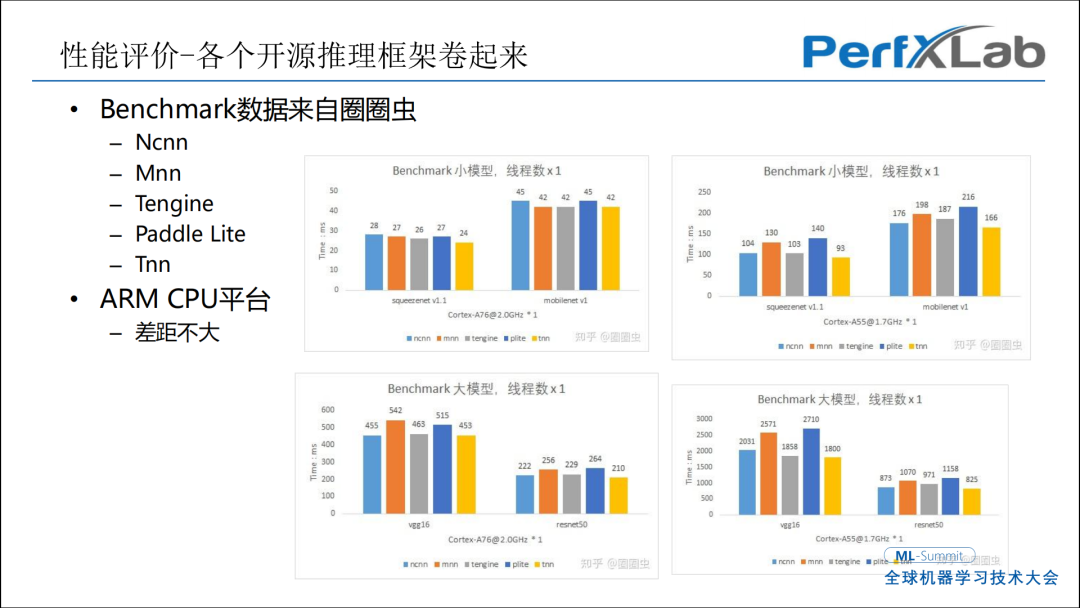
以目前来说,性能差距已经非常低了。图中数据柱状线代表的是时间,测了很多不同的模型。比如ARM Cortex-A76和ARM Cortex-A55,可以看到差距非常小。
我的结论是如果AI部署是用ARM的CPU,对于小模型哪个方便用哪个,对于大模型实际上是有NPU存在,可以直接用NPU来做,跟推理框架的成熟度关系不大。
NPU的性能优化
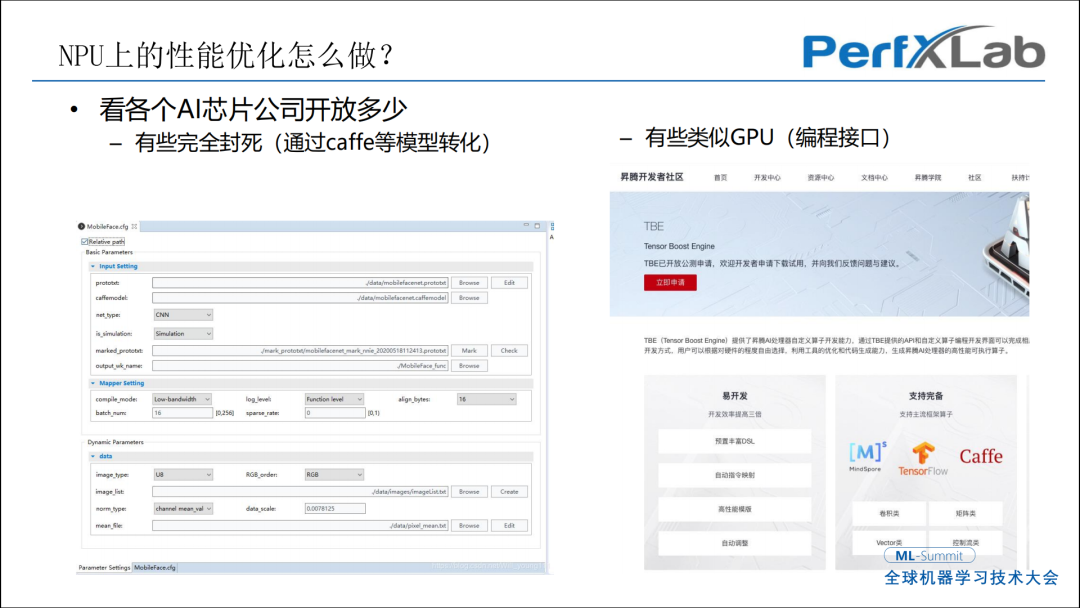
NPU的部署应该怎么做或者NPU的性能优化能做什么,现在的NPU公司存在两类情况,一类是完全封死的状态,通过Caffe做模型转化,很多算子不支持,要回到CPU来做。这种情况的转化模型成本很高,遇到一个新的模型需要算法工程师进行手动切分,很少有工具去划分哪些算子是NPU支持的,转化起来就比较麻烦。另一类是类似GPU编程接口,就是提供一个基础的加速部件,可以做算子的定制化,好处是网络进展较快。当出现特殊算子的时候,不用再放回CPU来做,可以在加速卡NPU上做,这是一个比较好的趋势。
嵌入式AI算法模型
深度学习模型
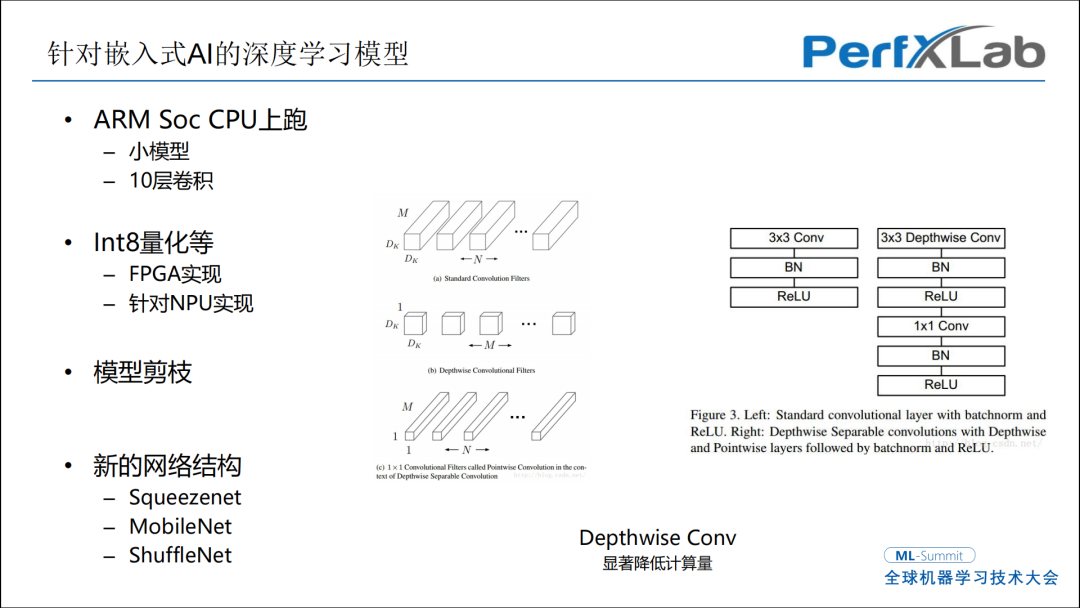
针对嵌入式AI的深度学习模型大概有四块,包含ARM Soc CPU、lnt8量化、模型剪枝和新的网络结构。ARM Soc CPU来跑深度学习模型,卷积在10层卷积或以下,就是小模型才能流畅的跑视觉应用。
Int8量化精度

不管是在CPU还是NPU都要跑量化的模型,发挥着很重要的速度作用。量化的基本原理是如何用定点数来表示浮点数,或者更高的效率表示浮点数。基本的公式是整数值减去零点值得出的值乘以刻度值,得出一个浮点数,简单的量化就是这样处理的。
在处理量化的时候需要注意,第一个转化成量化是Per layer量化还是Per Channel量化,Per layer量化代表着输出的全部用一个量化参数,Per Channel量化代表着每一个Channel都是不同的,量化的系数也是不同的。目前来说如果想达到Int8量化比较好的精度,要求模型的权重参数要做Per Channel量化。Feature map一般都是用Per layer量化,成本相对较低,硬件实现也更容易。
第二个需要注意的是刻度值怎么选择,一种是支持2的幂,转化的乘法通过定点数的移位操作当成浮点,硬件容易实现,但精度值差。另一种就是支持任意浮点数,精度值高。
第三个注意的是对称量化和非对称量化,是和零点值相关的。对称量化的零点是不能动的,好处是更容易实现,坏处是数据分布有问题。
第四个注意的是QAT,量化感知的训练。实际上就是把量化数据过程加入进去,让权重参数和Feature map的浮点数来更容易被量化。
最后一个就是有些模型的量化精度是很难做,需要看大家对于量化精度调点的要求。不同意调点的就需要做混合来保证精度。
模型压缩技术-剪枝法
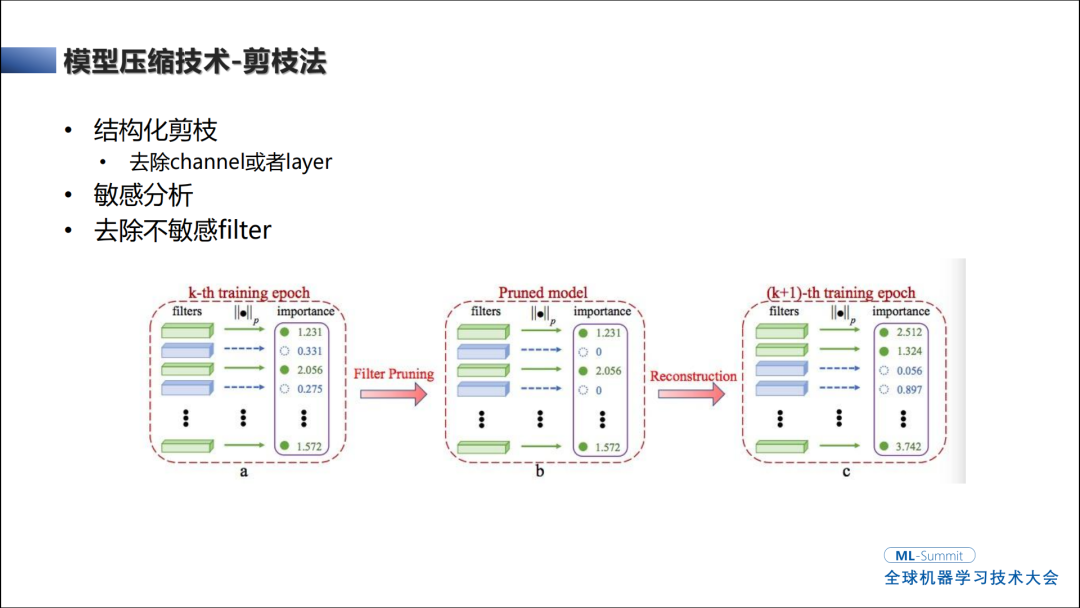
模型压缩有两种常用的,一种是非结构化的模型压缩,灵活程度和稀疏度更高,目前的NPU、FPGA或者加速卡没办法去识别权重的零值。结构化的剪枝就是去除Channel或layer,需要识别出哪些是重要的通道,哪些是不重要的。
当剪枝和量化综合在一起时可能会遇到新的问题。lnt8的量化是进一步的信息压缩,从浮点到定点再到信息损失;剪枝是去除Channel或layer,也是对信息进行压缩,当两部分结合时,有效信息被去除很多,导致精度大幅下降,有可能最后直接崩掉。在实际做的过程中,剪枝和量化需要迭代分开做,这样才能保证精度。
总结

整体上在AI的嵌入式应用里需要硬件的选型,软件框架和优化的选择,模型算法的设计,剪枝和量化的综合来处理完成,还需要考虑不同的AI部署应用有不同的模型需求。
以上,感谢澎峰科技创始人张先轶在2021全球机器学习技术大会上的主题分享。
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!