
43.6% mAP! 阿里巴巴提出:用于一阶段目标检测的半锚式检测器
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:AI深度学习视线
半锚式(semi-anchored,SA)目标检测器,其基于ResNet-101 可在COCO上可达43.6%
mAP!性能优于FreeAnchor、FCOS和FSAF等.作者:阿里巴巴
paper:
https://arxiv.org/abs/2009.04989
1
摘要

标准的一阶段检测器包括两个任务:分类和回归。为特征图中的每个位置引入了不同形状的锚(anchor),以减轻多尺度目标回归的挑战。但是,由于anchor中高度的类不平衡问题,分类的性能可能会降低。最近,提出了许多anchor-free算法来直接对位置进行分类。anchor-free策略有利于分类任务,但由于缺少先验的边界框,可能导致回归不到最优值。在这项工作中,我们提出了一个半锚式(semi-anchored)框架。具体而言,我们在分类中确定正位置,并将多个anchors与回归中的正位置关联。以ResNet-101为骨干,提出中的semi-anchored检测器在COCO数据集上达到了43.6%的mAP,这证明了一阶段检测器的最新性能。
2
本文思想
本文提出了一种用于单级目标检测的半锚定检测器。具体来说,我们在没有锚的情况下对feature map中的位置进行分类。在分类中,我们可以将锚点的正候选点与负候选点的比率从1:1400提高到位置的1:200。对于回归,我们为每个位置关联多个锚点,并从锚点学习前景位置的边界框。主要的挑战之一是计算以前景位置为中心的锚点的前景/背景概率,因为锚点没有用于分类。这些锚具具有相同的定位性能,但由于锚具的形状不同,性能可能不尽人意。因此,我们附加一个锚分类头来识别每个位置的前景锚。图1说明了所提出的半锚定检测器的过程。
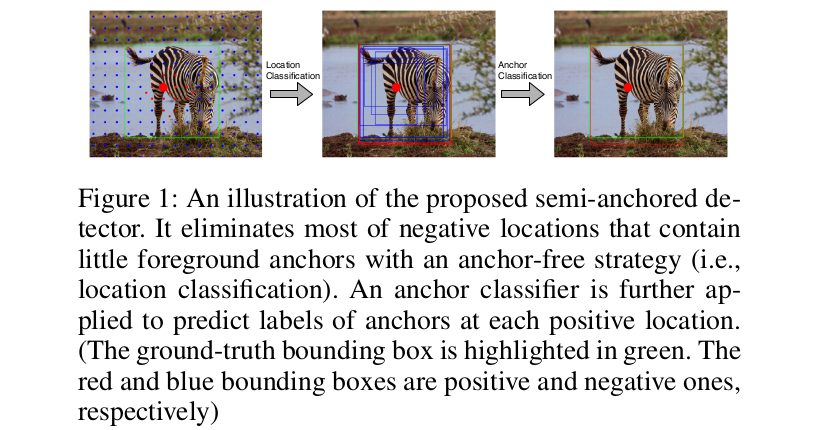
显然,所提出的检测器在没有锚的情况下处理了平衡分类问题,并且在有锚的情况下获得了更好的回归性能。此外,我们还根据回归后的并集相交(IoU)定义了正锚。与传统回归前用IoU标记锚点的算法相比,该策略更符合目标。简化了分类头,提高了分类效率。在COCO数据集上的大量实验(Lin et al. 2014)验证了所提框架的有效性和效率。我们的算法可以超过目前最先进的无锚检测器FCOS (Tian et al. 2019),以ResNet-101为骨干实现mAP 43.6%。此外,当我们为每个位置分配更多的锚时,该方法的推理时间甚至小于RetinaNet。
3
具体实现
3.1 Location Classification
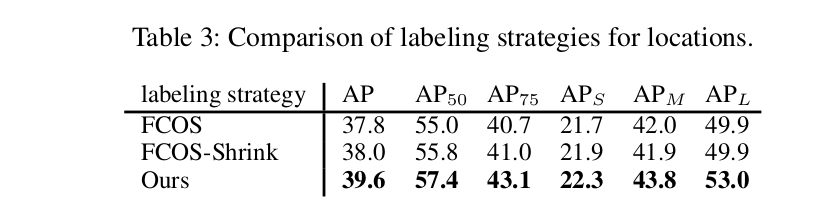
在分类任务中,我们在没有锚的情况下从特征图中识别前景位置。一个位置是指feature map中的一个像素。设{x i, y i}表示位置集,其中xi为特征,yi表示第i个位置的标号。对于C个前景对象的问题,我们让y i∈{0,…, C}其中y i = 0表示背景位置。注意,xi可以直接从feature map中提取,唯一的问题是为位置分配适当的标签。标记每个位置最直接的方法是使用ground truth边界盒,即一个ground truth边界盒内的每个位置都可以用相应的前景标签进行标记。但是,每个位置都可以与多个前景对象相关联。用较小对象的标签标记重叠位置的启发式方法可能与使用锚的回归任务不一致。因此,我们建议在半锚定检测器中为每个锚定位置定义标签。
对于每个位置,我们与基于锚的方法中一样,将K个锚与不同的比例和纵横比关联起来。在传统算法的基础上,利用GT边界盒计算loss,得到锚点的标号。设one-hot向量y i,k∈{0,1}C+1表示第i个位置上第k个锚点的标号。通过对一个位置锚的标签,我们可以得到该位置的置信分数为:
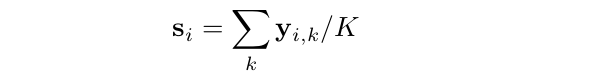
考虑到锚点中背景大量存在,我们将0≤γ≤1的分数重新标为背景(即c = 0,其中sci为si中第c个元素)
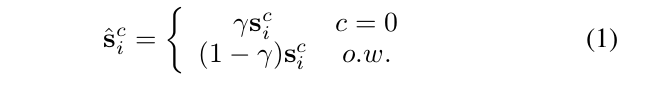
这相当于阈值移动来解决类不平衡问题。给定置信分数,第i个位置的标签可以定义为:
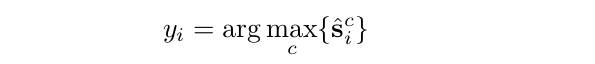
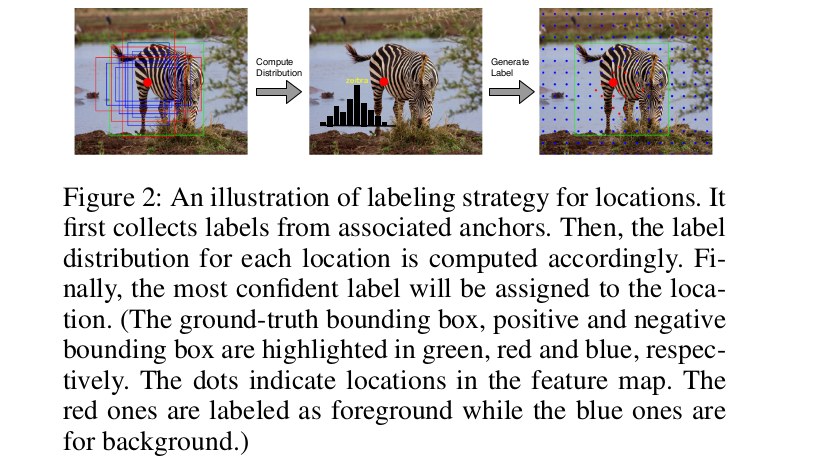
需要注意的是,锚只用于在分类任务中获取位置标签。所提出的标记策略如图2所示。可以看到,在真值边界盒中,许多非必要的位置被标记为背景。为了进一步演示我们的标记策略,我们在图3中展示了一些正位置的例子。

有了标记的位置,我们就可以像在其他工作中一样,用常见的focal损失来训练分类器:
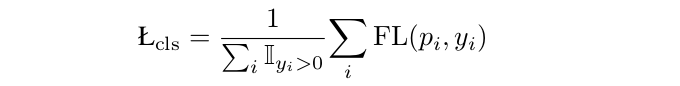
3.2 Anchor Classification
现在有了位置分类器和锚点回归器,在推理过程中,位置分类器可以告诉我们对象c的第i个位置的概率Pr{yi = c|xi},回归器提供锚点{zi, K} K =1,…,K,其中zi,K表示第K个锚点在第i个位置的特征。这里是主要的gap,也就是K个锚中的哪个应该是输出。因此,我们的目标是估计每个锚点的概率为Pr{yi,k = c|xi, zi,k},而只有对应位置Pr{yi = c|x i}的概率。
考虑到锚点的标签应该与其位置一致,我们计算条件概率为:
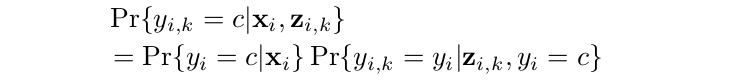
这个公式暗示了一个二元分类问题,识别锚与相同的标签作为位置。因此,我们可以将训练集收集为{zi,k, yi,k},其中:
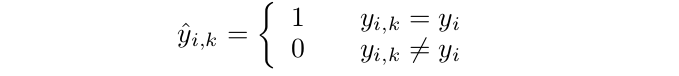
在传统的锚基方法中,锚的标签{yi,k}是根据锚的先验形状计算的。回归后,细化后的形状可能会与初始形状不一样,这实际上导致了很大的差异。我们的建议是通过计算回归后改进锚点的loss来消除这种差异。有了合适的标签,我们可以通过优化focal损失来学习锚分类器。
令μi,k表示锚点z i,k的IoU。首先,我们将每个位置的IoU分数归一化为:
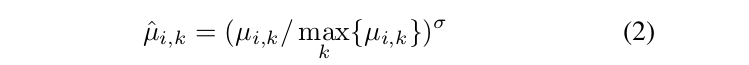
我们采用分数作为软标签,并引入平滑的focal损失:
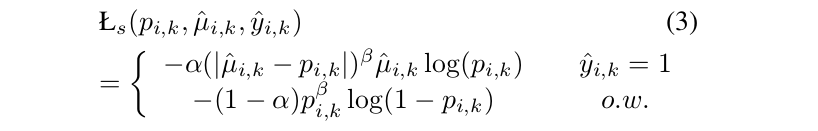
与标准focal损失相比,我们有μ̂,k的平滑标签正锚,而不是1,可以捕获不同的锚更好的分布和提高性能。在提出的平滑focal损失的情况下,锚分类器是通过最小化所有前景位置的损失来学习的:
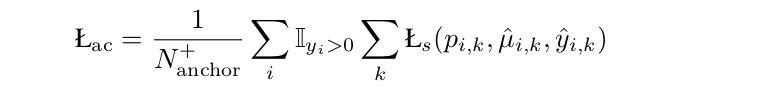
总之,半锚定探测器的目标是最小化:
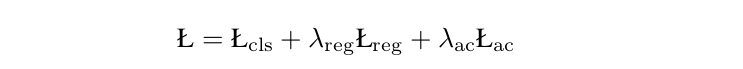
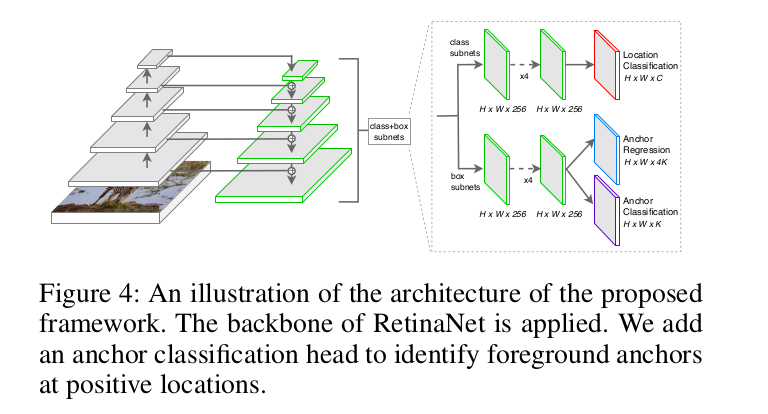
4
实验结果
4.1 Ablation Study
Number of Anchors
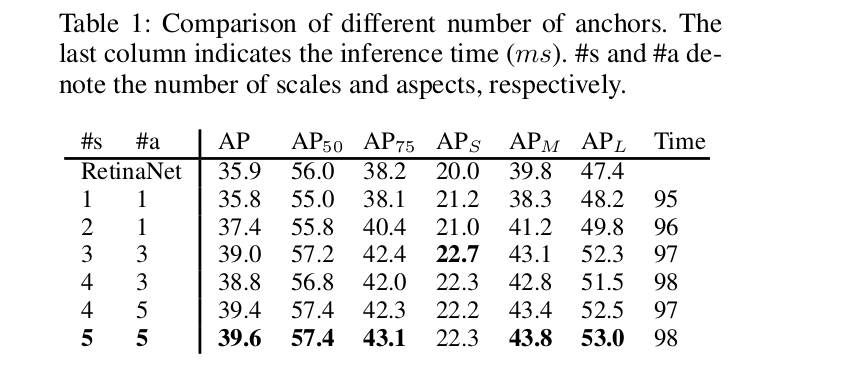

Location Classification
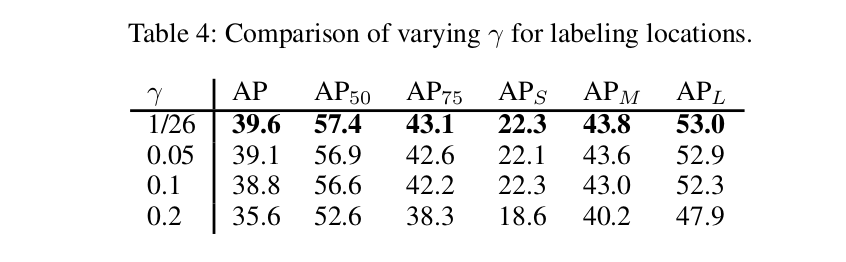
Anchor Classification
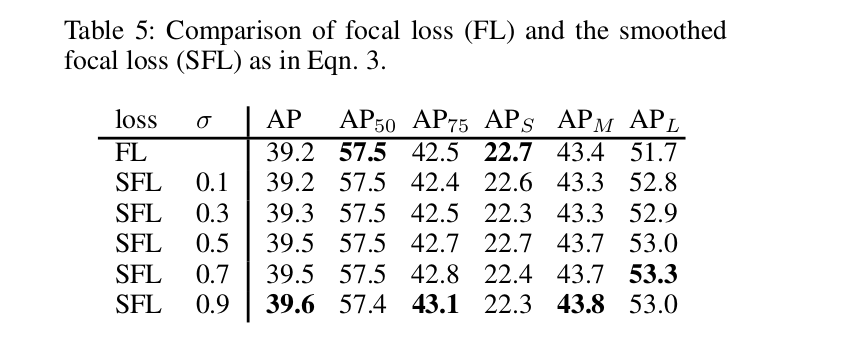
Inference Strategy
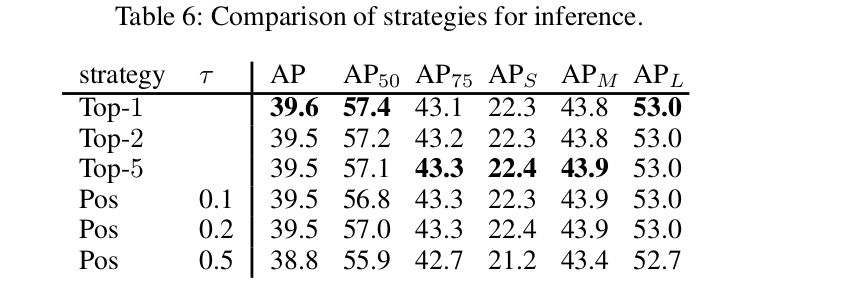
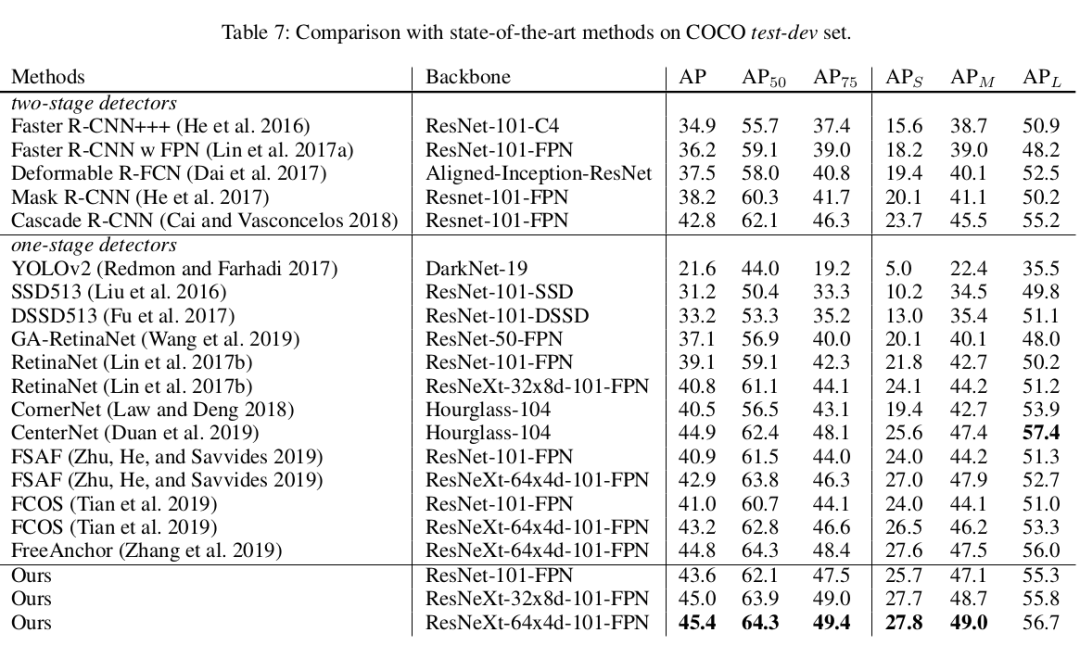
4.2 Comparison with State-of-the-Art
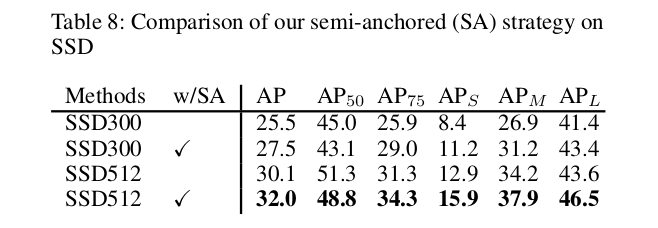
下载1:OpenCV黑魔法
在「AI算法与图像处理」公众号后台回复:OpenCV黑魔法,即可下载小编精心编写整理的计算机视觉趣味实战教程
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

