
python爬取个人博客园博客列表
前言
昨天和几个小伙伴小聚了一下,但是由于我的失误,导致诸事不顺 出门忘看老黄历了
出门忘看老黄历了 (逛公园,到门口闭园了;往回走,公交站不好找,走了好多冤枉路),然后手机没电了,地铁还停了,回到家也已经不早了,所以昨天就放鸽子了,但是今天呢,不能再继续鸽了,然后我就打算分享一些比较轻松的内容,于是就有了今天的内容。
(逛公园,到门口闭园了;往回走,公交站不好找,走了好多冤枉路),然后手机没电了,地铁还停了,回到家也已经不早了,所以昨天就放鸽子了,但是今天呢,不能再继续鸽了,然后我就打算分享一些比较轻松的内容,于是就有了今天的内容。
安装配置python
这里我们简单介绍下python的安装配置,原本是不打算讲的,但是我看了下,之前我好像也没有分享过,所以这里就简单说下,也是帮助那些没有python基础的小伙伴,能够尽快上手。
下载安装
安装版本这里推荐3.0及以上,我这里安装的是3.9,2.7虽然也可以,但是不推荐,官方推荐的也是3.0版本。这两种版本在很多函数和写法上并不通用,所以代码也不通用,有兴趣的小伙伴可以看下区别,这里我不打算展开分享。
安装方式有很多,用win10的小伙伴可以直接在应用商店搜索安装,但这里并不推荐这种方式,因为这种方式不好找python安装路径,特别是对windows平台不是特别熟悉的小伙伴:
另外一种安装方式就是官网下载,然后安装:
官方最新版本是3.10,如果觉得官方网站下载慢的话,可以去华为镜像站下载,选择对应的版本即可(华为好像没有3.10版本的):
https://repo.huaweicloud.com/python/
安装过程很简单,这里就不讲了,双击exe,然后一直下一步就好了。
配置
安装完成后,我们需要对python设置一些环境变量。首先,打开python安装路径,如果不知道可以搜下python,然后打开文件路径即可:
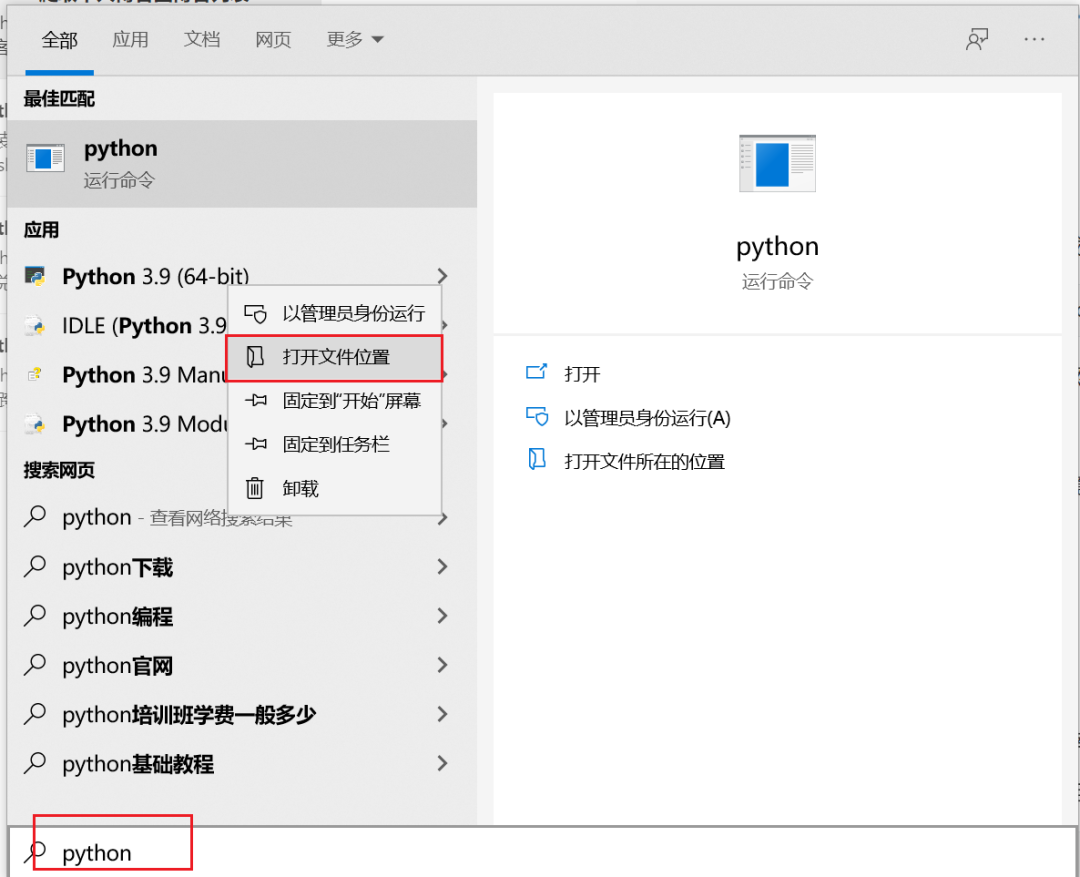
打开之后其实还不是安装位置,还需要再次右键打开安装路径:
然后才是真正的安装路径(我这里就是在应用市场下载的,看这路径是不是不好找):
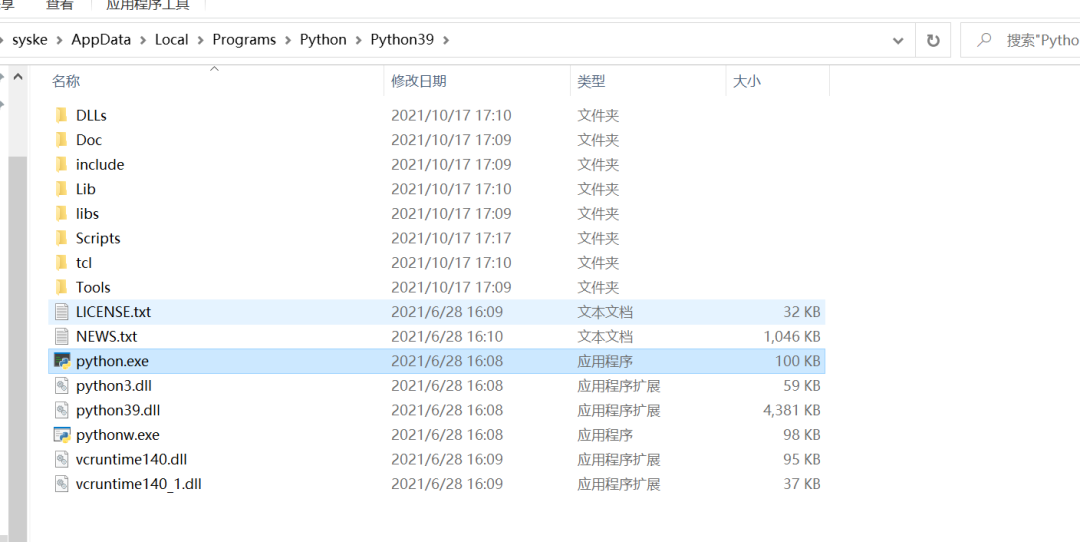
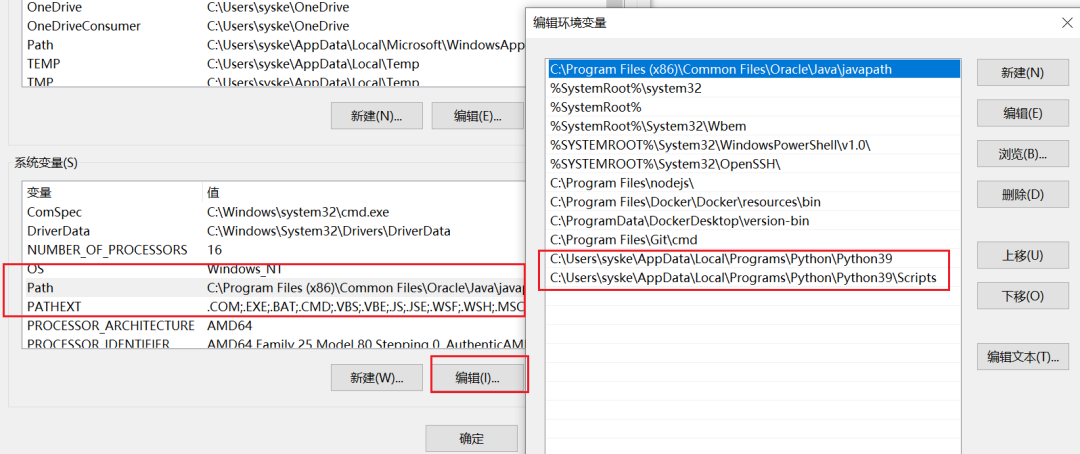
然后打开环境变量设置,添加两个环境变量设置:
# 安装目录,也就是python.exe所在路径
C:\Users\syske\AppData\Local\Programs\Python\Python39
# 安装目录下scripts路径,这个目录下存放了pip等管理工具
C:\Users\syske\AppData\Local\Programs\Python\Python39\Scripts
这里需要注意的是,环境变量要设置在系统变量的path下面,否则如果是用户变量则无法被识别(也可能是我操作方式不对,但是系统变量肯定是可以的):
验证
安装完成后,重新打开一个新的cmd窗口,输入python命令,如果显示如下在,则表明已经安装配置完成,否则配置有问题:

然后再执行了经典的hello world试下:

当然,还需要测试下pip是否配置ok,这个工具是用了管理python的依赖库的:

至此,python环境搭建完成。
爬取博客列表
准备工作
这里主要是安装我们爬虫要依赖的第三方依赖库。
安装requests库,这个库的作用是向我们的目标地址发送请求,并拿到响应内容,比如html内容
pip install requests
安装beautifulsoup4库,这个库的作用就是解析响应的html内容。目前我也仅用它来解析html内容,所以其他内容暂时未知
pip install beautifulsoup4
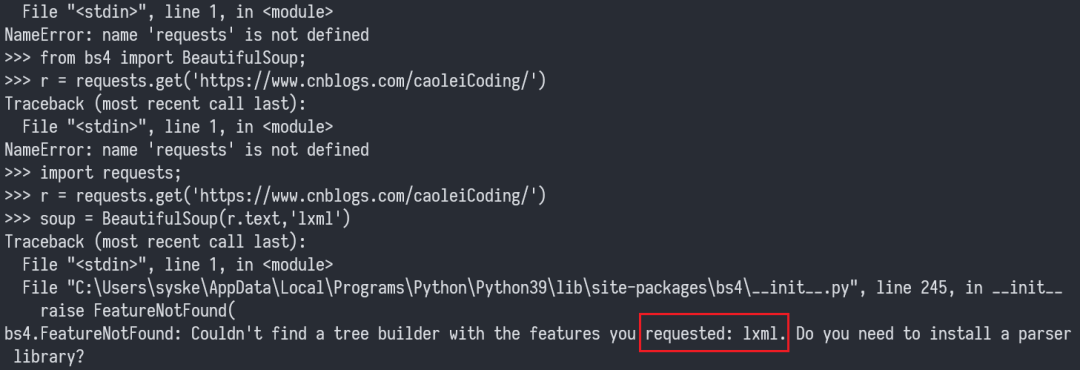
安装lxml库,这个库是bs4库(也就是我们的soup库要依赖的)
pip install lxml
如果没有这个库,在解析html的时候会报如下错误
最终完成效果
简单来说,就是我们想通过这个爬虫,拿到我的个人博客的所有列表,包括标题和链接地址,这里我是直接生成了一个markdown文档,所以链接的效果就是markdown的可点击链接,最终的效果
如下:

页面源码
首先我们要先分析要抓取的页面html,确定具体解析方案:
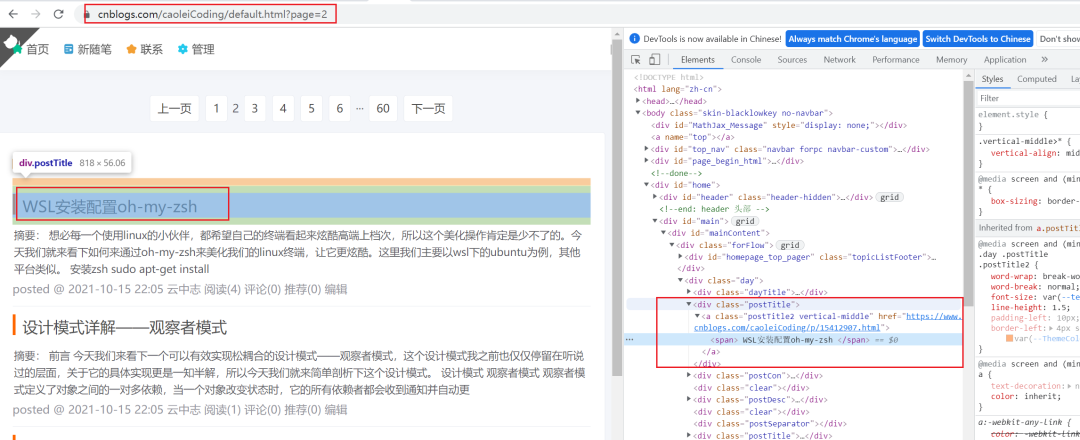
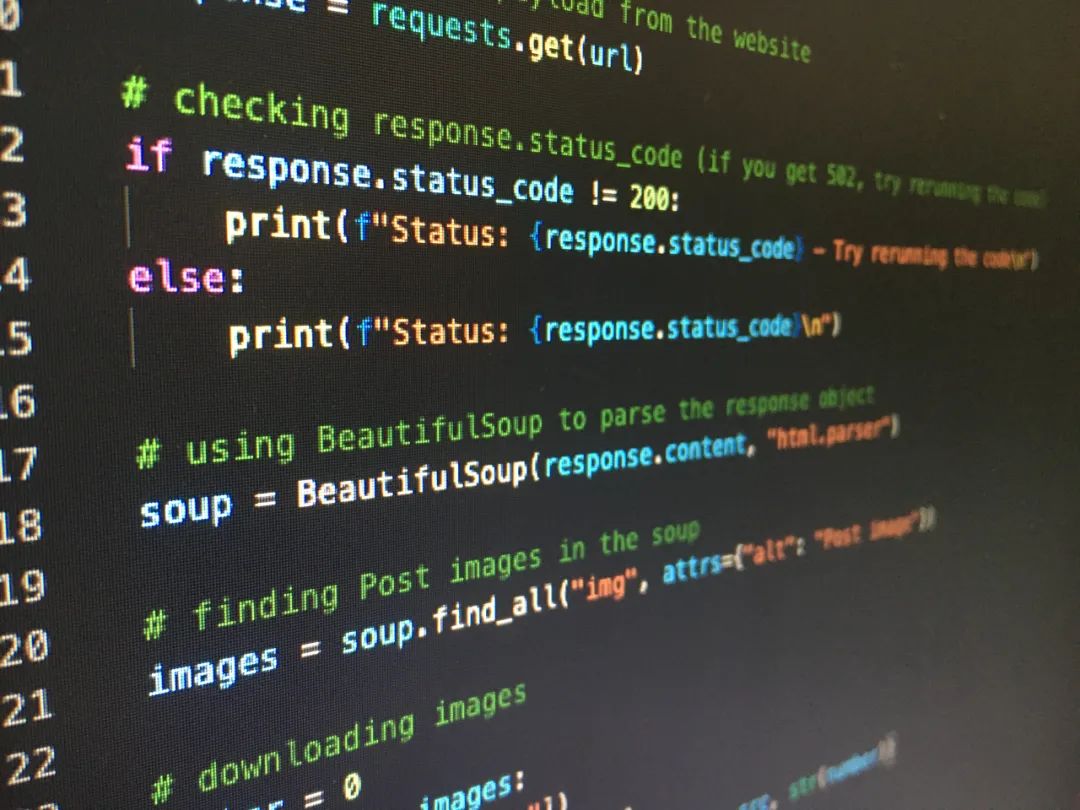
从页面源码可以看出来,我们其实只需要拿到class为postTitle的div,然后解析其中的文字内容及a标签的url即可,所以下面的实现就是基于这个思路展开的。
实现过程
下面我们看下具体的爬取代码。其实整个代码确实很简单,当然这也是很多人喜欢用python写脚本的原因,简简单单几行代码,就可以实现其他语言整个项目的功能(比如java,当然性能上python没有任何优势),真的是生产力提升利器。
这里最核心的一句代码是:
for tag in soup.find_all('div', class_='postTitle'):
再精简一下是:
soup.find_all('div', class_='postTitle')
也就是soup的find_all,从soup的文档中,我们可以得知,通过这个方法我们可以拿到soup下的相关tag对象。这个方法有四个参数:
name参数可以查找所有名字为name的tag,字符串对象会被自动忽略掉。例如:soup.find_all('div'attrs:可以通过属性搜索,例如:soup.find_all('div', class_='postTitle')recursive:这个暂时没用到,还没研究string:没研究keywords:包括关键字的内容,也没研究
关于soup可以小伙伴可以去详细看下文档,我也没有搞得特别清楚,所以暂时就先不说了。
然后下面就是完整的实现过程了:
# 引入 requests库
import requests;
# 从bs4库中引入BeautifulSoup
from bs4 import BeautifulSoup;
# 引入正则表达式依赖
import re;
# 引入文件相关依赖
import os;
# 全局变量,主要是为了生成序号,方法内部最后一个赋值很重要,没有这个赋值,会导致序号不连续
global index;
# 定义了一个方法,这个方法就是为了循环遍历我的博客,文件就是我们要保存的文件
def get_blog_list(page, index, file):
# 通过requests发送请求,这里用到了字符串的格式化
r = requests.get('https://www.cnblogs.com/caoleiCoding/default.html?page={}'.format(page));
# 打印返回结果
print(r.text);
# 用soup库解析html,如果没有安装lxml库,会报错
soup = BeautifulSoup(r.text,'lxml');
# 搜索class属性为postTitle的div
for tag in soup.find_all('div', class_='postTitle'):
print(tag);
# tag的span标签的内容
content = tag.span.contents;
# 过滤掉置顶内容,这块的结构和其他内容不一样,匹配需要写正则,太复杂,所以先忽略掉
if index == 0 and page == 1:
index += 1;
continue;
print(content)
# 获取span的内容,也就是文本内容
title = next(tag.span.children)
print(str(title));
# 替换其中的换行符和空格
title = title.replace('\n', '').strip();
print(title);
# 获取tag下的a标签的href,也就是我们的博客地址
url = tag.a['href']
print(tag.a['href']);
# 通过字符串格式化写入解析的内容
file.write('{}. [{}]({})\n'.format(index, title, url));
# 序号自增
index += 1;
# 给全局变量赋值
inedx = index;
if __name__ == "__main__":
# 初始化全局变量
index = 0;
# 定义我们的markdwon文件,模式为写,如果没有的话,会新增
file = open('syske-blog-list.md', 'w')
# 我现在的包括是60页,这里是循环获取
for page in range(59):
get_blog_list(page + 1, index, file);
总结
今天我们就是对python脚本爬虫的一次简单应用演示,当然也希望能通过这个示例激发各位小伙伴学习python的兴趣,毕竟它也算是一个比较高效的生产力工具,如果学的好了,你可以用它来处理日常工作中的各类问题,包括数据统计、数据处理、批量业务处理,还有像今天这样简单抓取数据,当然,你如果学的好了,你可以用它做任何事,抢票呀、下载短视频,甚至是爬取小电影、小姐姐图片等。
好了,今天的内容就到这里吧,再晚点今天就发不出去了,各位小伙伴,晚安吧!
- END -