
ShakeDrop:深度残差学习中的 ShakeDrop 正则化
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者 | Sik-Ho Tsang
编译 | ronghuaiyang
转自 | AI公园
在ResNeXt,ResNet,Wide Resnet(WRN)和RyramidNet上超过Shake-Shake和RandomDrop。
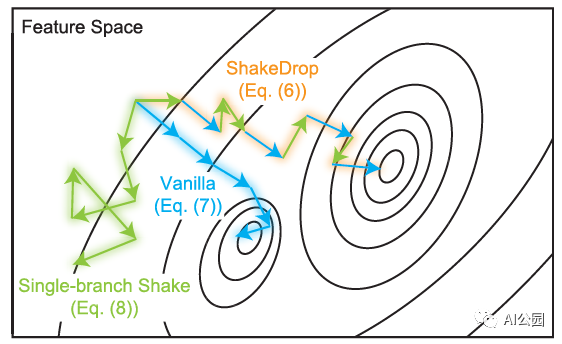
ShakeDrop: converge to a better minimum
ShakeDrop Regularization for Deep Residual Learning (ShakeDrop),来自大阪市立大学和Preferred Networks, Inc.。ShakeDrop 要比 Shake-Shake更加有效,不仅可以用到ResNeXt上,还能用到ResNet,Wide ResNet和PyramidNet上。
1. Shake-Shake回顾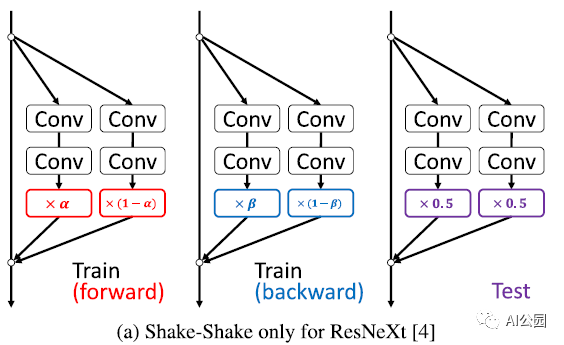
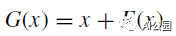
设α和β是由区间[0,1]上的均匀分布均匀抽取的独立随机系数。Shake-Shake可以写成:
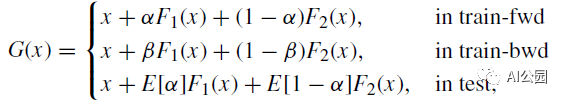
其中train-fwd和train-bwd分别表示训练的前向和后向。期望值E[α] = E[1-α] = 0.5。
为每个图像或批处理绘制α和β的值。
1.1. ShakeDrop的作者对Shake-Shake的解释
Shake-Shake的作者没有提供解释。
Shake-Shake使梯度在一个分支上是原来正确计算梯度的α/β倍,在其他分支上是(1 - β)/(1 - α)倍。这个干扰似乎阻止了网络参数在局部极小值被捕获。 Shake-Shake对两个残差分支的输出进行插值。 在特征空间中对两个数据进行插值,可以合成很多有意义的增广数据。因此,Shake-Shake前向传递的插值可以解释为合成合理的增强数据。
随机权重α的使用使我们能够生成许多不同的扩增数据。相反,在向后通过中,使用不同的随机权值β来干扰更新参数,期望通过增强SGD的效果,帮助避免参数陷入局部极小值。
2. RandomDrop的简单回顾
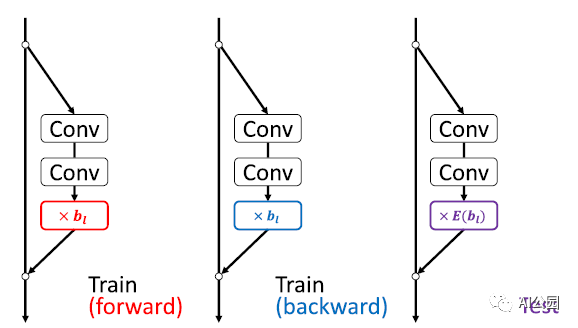
基本的ResNet构建块,它有一个两个分支架构,是:
RandomDrop通过丢弃一些随机选择的构建块,使得网络在学习中变得很浅。
输入层的第l个构建块如下所示:
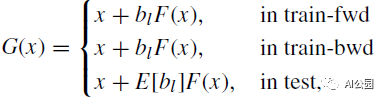
其中,bl∈{0,1}是一个概率为P*(bl* =1) =E[bl] = pl的伯努利随机变量。线性衰减法则用于确定pl:
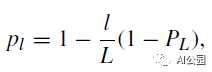
其中L为构建块的总数,PL=0.5。
RandomDrop可以被认为是Dropout的一个简化版本。主要的区别在于,RandomDrop丢掉的是层,Dropout丢掉的是元素。
3. ShakeDrop
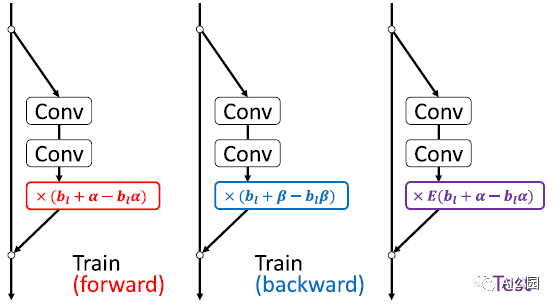
通过混合Shake-Shake和RandomDrop,就变成了ShakeDrop。
我们期望当选择原始网络时,学习被正确地促进,当选择强扰动网络时,学习被干扰,会变成上面图中的效果。
当α =β = 0时,ShakeDrop就变成了RandomDrop。
4. 实验结果
4.1. CIFAR
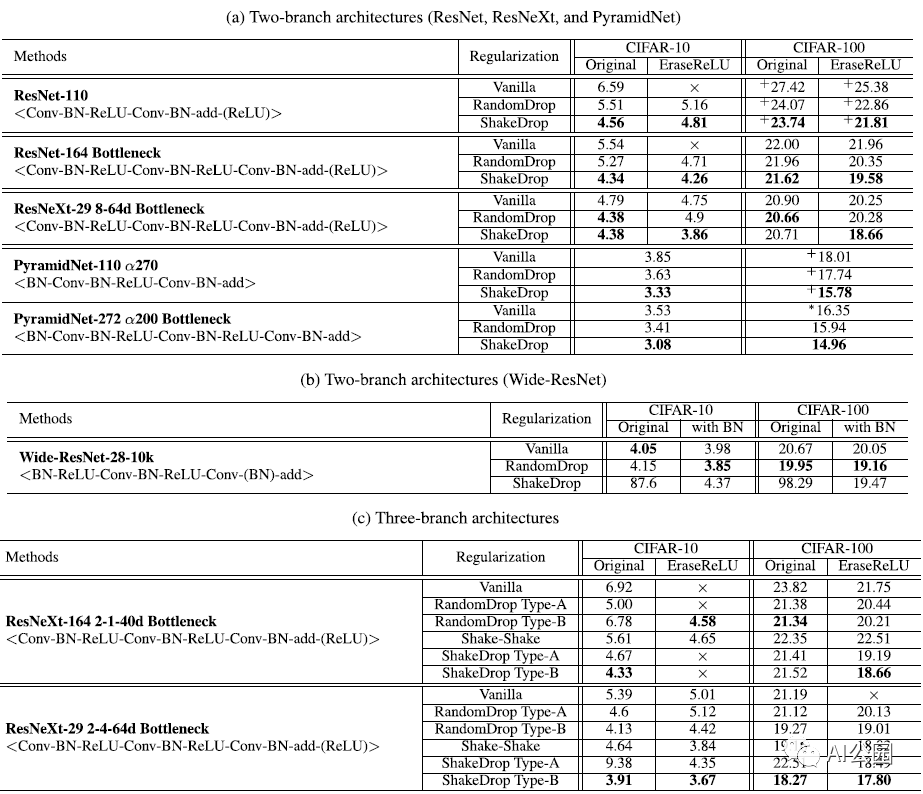
“A型”和“B型”分别表示对剩余分支在添加单元之后和之前插入正则化单元。
ShakeDrop不仅可以应用于三分支架构,还可以应用于两分支架构ResNet,WideResNet和PyramidNet,ShakeDrop的表现优于RandomDrop和Shake-Shake。
4.2. ImageNet

在 ResNet, ResNeXt, 和 PyramidNet上, ShakeDrop明显超过RandomDrop和原始网络。
4.3. COCO Detections and Segmentation
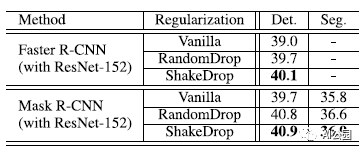
Faster R-CNN 和 Mask R-CNN 作为检测器,使用预训练的 ResNet-152。
在Faster R-CNN 和 Mask R-CNN上, RandomDrop明显优于RandomDrop和原始网络
4.4. ShakeDrop 和 mixup一起
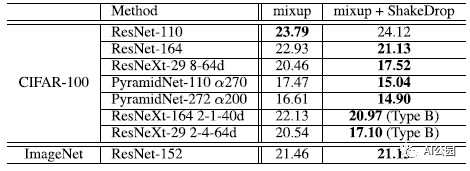
在大多数情况下,ShakeDrop会在使用mixup的情况下进一步降低错误率。
这表示ShakeDrop并不是其他正则化方法的对手,而是合作伙伴。
关于α、β和PL值的测定,已有大量的实验研究。如果有兴趣,请随意阅读这篇文章。
英文原文:https://medium.com/swlh/paper-shakedrop-shakedrop-regularization-for-deep-residual-learning-image-classification-d2b83d0ae3de

点个在看 paper不断!