
干货|深度学习之过拟合和正则化
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

一、过拟合,欠拟合
过拟合(overfitting):学习能力过强,以至于把训练样本所包含的不太一般的特性都学到了。
欠拟合(underfitting):学习能太差,训练样本的一般性质尚未学好。
下面是直观解释:

下面在那一个具体的例子:如果我们有6个数据,我们选择用怎么样的回归曲线对它拟合呢?看下图
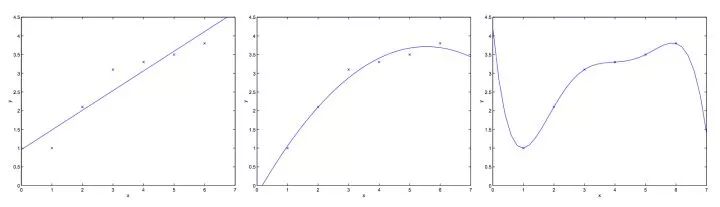
可以发现得到的直线
 并不能较为准确的描述训练数据的形态,我们说这不是一个良好的拟合,这也叫做欠拟合
并不能较为准确的描述训练数据的形态,我们说这不是一个良好的拟合,这也叫做欠拟合如果我们再加入一个特征值
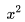 ,得到
,得到 于是我们得到二阶多项式,一个稍好的拟合。
于是我们得到二阶多项式,一个稍好的拟合。最后我们直接用五阶多项式去拟合,发现对于训练样本可以很好的拟合,但是这样的模型对预测往往效果不是非常好,这叫做过拟合(overfitting)。
在这里我们可以发现,原来过拟合和欠拟合和模型复杂度是相关的,具体描述如下图
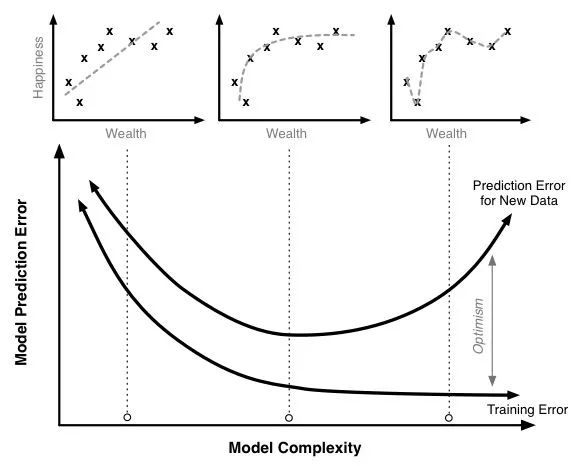
也就是说,在模型相对复杂时,更容易发生过拟合,当模型过于简单时,更容易发生欠拟合。
当然,为了防止过拟合,也会有cross validation,正则化等等方法,以后会一一介绍。
二、正则化
正则化的主要目的是为了防止过拟合,而它的本质是约束(限制)要优化的参数。通常我们通过在Cost function误差函数中添加惩罚项来实现正则化。当然,正则化有其缺点,那就是引入正则化可能会引起“too much regularization”而产生误差。
问:对于正则化,有使模型“简单”的优点,这其中”简单”怎么理解?
答:引用李航老师书中的那段话:正则化符合奥卡姆剃刀 (Occam’s razor)原理。奥卡姆剃刀原理应用于模型选择时变为以下想法:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型,也就是应 该选择的模型。从贝叶斯估计的角度来看,正则化项对应于模型的先验概率。可以假设复杂的模型有较大的先验概率,简单的模型有较小的先验概率。
需要注意的是,在正则化的时候,bais是不需要正则化的,不然可能会导致欠拟合!
下面介绍一些常见的正则化方式:

L1,L2的图像化:
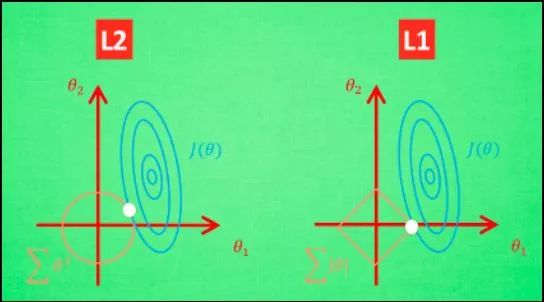

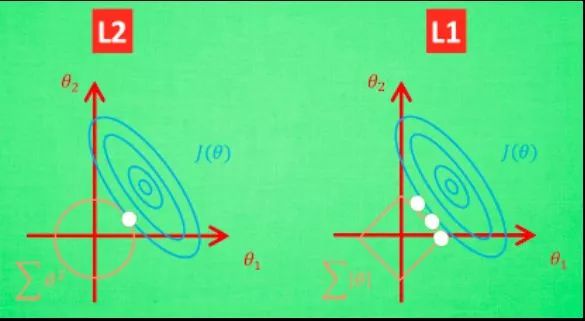
L2 针对于这种变动, 白点的移动不会太大, 而 L1的白点则可能跳到许多不同的地方 , 因为这些地方的总误差都是差不多的. 侧面说明了 L1 解的不稳定性。
注意记住:L1正则化会让权重向量在最优化的过程中变得稀疏(即非常接近0),使得L1很多时候也拿来做特征选择;L2正则化可以直观理解为它对于大数值的权重向量进行严厉惩罚,倾向于更加分散的权重向量。
最大范式约束(Max norm constraints):另一种形式的正则化是给每个神经元中权重向量的量级设定上限,并使用投影梯度下降来确保这一约束。在实践中,与之对应的是参数更新方式不变,然后要求神经元中的权重向量 必须满足
必须满足 这一条件,一般c值为3或者4。有研究者发文称在使用这种正则化方法时效果更好。这种正则化还有一个良好的性质,即使在学习率设置过高的时候,网络中也不会出现数值“爆炸”,这是因为它的参数更新始终是被限制着的。
这一条件,一般c值为3或者4。有研究者发文称在使用这种正则化方法时效果更好。这种正则化还有一个良好的性质,即使在学习率设置过高的时候,网络中也不会出现数值“爆炸”,这是因为它的参数更新始终是被限制着的。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~