
PDNet:利用预测解耦实现更好的单阶段目标检测


摘要
文章分析了对象类别和边界的合适推理位置,提出了一种预测-目标解耦检测器PDNet,建立了更灵活的检测范式。作者的PDNet具有预测解耦机制,在不同的位置分别编码不同的目标。利用动态边界点和语义点两组动态点,设计了可学习的预测收集模块,对有利区域的预测进行收集和聚合,便于定位和分类。作者采用两步策略来学习这些动态点位置,首先对不同目标的先验位置进行估计,然后网络在更好地感知目标属性的情况下进一步预测这些位置的残差。在MS COCO基准上的大量实验证明了作者的方法的有效性和效率。以单个ResNeXt-64x4d-101作为骨干,作者的检测器通过单尺度测试实现48.7个AP,在相同的实验设置下,其性能明显优于最先进的方法。此外,作者的检测器作为一个一级框架是高效的。作者的代码将被公开。

总的来说,这项工作的贡献是:
作者分析了传统一级检测器的密集预测,发现用于推断目标类别和边界位置的最佳位置是不同的。受此启发,作者提出了基于预测解耦机制的PDNet,以灵活地收集和聚合来自不同位置的不同目标的预测。
作者设计了两组动态点,即动态边界点和语义点,并提出了两步动态点生成策略,以方便学习适合的点位置进行定位和分类。
没有铃铛和哨子,作者的方法在MS COCO基准上实现了最先进的性能。以单个ResNeXt-64x4d-101为骨干,作者的检测器在单尺度测试中实现了48.7个AP,在相同的实验设置下明显优于其他方法。

框架结构
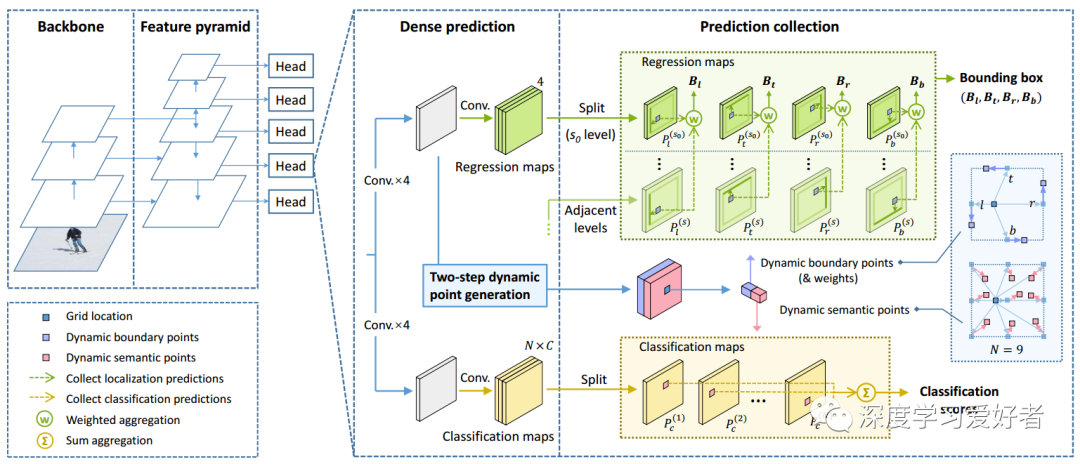
06 = 9网格位置图3,PDNet的整体网络架构
PDNet基于特征提取主干和特征金字塔网络(FPN),从FPN扩展多个检测头,实现多尺度密集检测。在检测头中,密集预测步骤首先生成用于分类和定位的密集预测图,这与大多数传统的单阶段方法相似。作者的预测映射沿着通道维度进行分割,其中不同的通道为每个位置编码相应的不同目标。具体来说,回归图切片为绿色,其中,包含对象边界框四边的相对偏移量的密集预测,而分类地图切片黄色部分,包含不同语义区域的密集分类分数。在获得这些密集预测之后,作者对每个网格位置在两组动态点(来自两步动态点生成模块)的指导下进行预测收集,从各自有利的位置收集预测得到分类分数和边界框。

实验结果
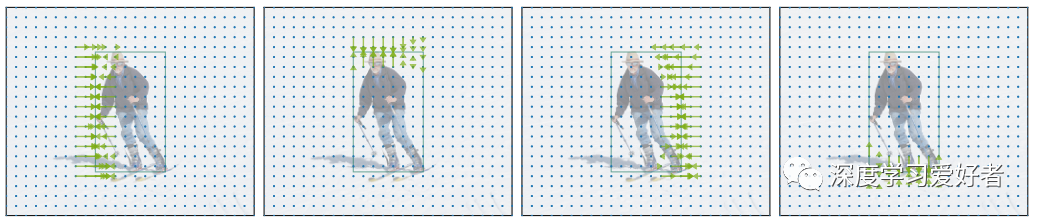
用于定位对象边界框的左、上、右和下侧面的回归图的可视化。为了清楚地演示,作者只显示边界区域的预测偏移量。作者可以看到,从物体边缘附近的网格的位置偏移精确地匹配剩余距离到相应的边界框边缘。
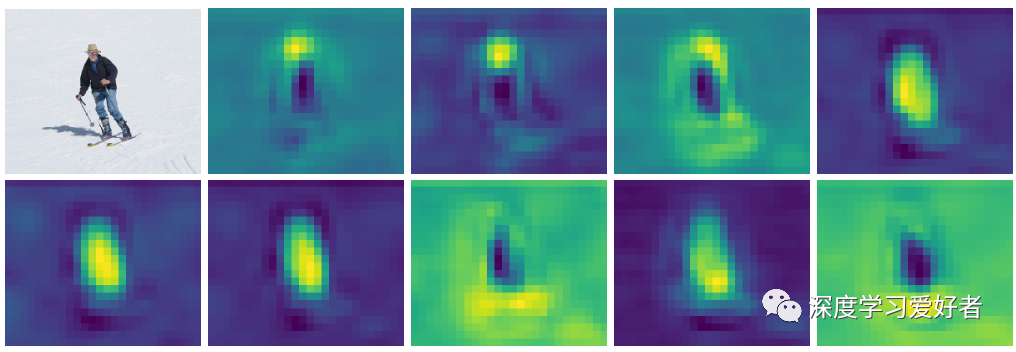
人员分类图的可视化
这些分类图在这个人的不同区域产生强烈的激活,表明它们分别建模了不同对象区域的语义信息。

在MS COCO val2017集上可视化一些检测结果。最后的对象边界框用绿色表示,预测的动态边界点和语义点分别用绿色和橙色表示。动态边界点(绿色)位于物体边缘附近,在那里可以准确地推断出边界框的边界。动态语义点(橙色)主要分布在对象的不同部位,有利于对象分类。
 结论
结论
在这项工作中,作者提出了一种精确和高效的目标检测器PDNet,它可以推断出不同的目标(即目标类别和边界位置)在其相应的适当位置。具体来说,作者在密集预测方法的基础上,提出了一种基于预测解耦机制的PDNet,可以灵活地从不同位置收集不同的目标预测,并将其聚合为最终的检测结果。此外,作者设计了两组动态点,即动态边界点和语义点,并结合两步生成策略,以方便学习适合的推理位置进行定位和分类。在MS COCO基准上的大量实验证明了作者的方法具有最先进的性能和效率。
论文链接:https://arxiv.org/pdf/2104.13876.pdf
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
整理不易,点赞三连!