
【Python基础】这个Pandas函数可以自动爬取Web图表
Pandas作为数据科学领域鳌头独占的利器,有着丰富多样的函数,能实现各种意想不到的功能。
作为学习者没办法一次性掌握Pandas所有的方法,需要慢慢积累,多看多练。
这次为大家介绍一个非常实用且神奇的函数-read_html(),它可免去写爬虫的烦恼,自动帮你抓取静态网页中的表格。
简单用法:pandas.read_html(url)
主要参数:
io:接收网址、文件、字符串 header:指定列名所在的行 encoding:The encoding used to decode the web page attrs:传递一个字典,用其中的属性筛选出特定的表格
只需要传入url,就可以抓取网页中的所有表格,抓取表格后存到列表,列表中的每一个表格都是dataframe格式。
我们先简单抓取天天基金网的基金净值表格,目标url:http://fund.eastmoney.com/fund.html
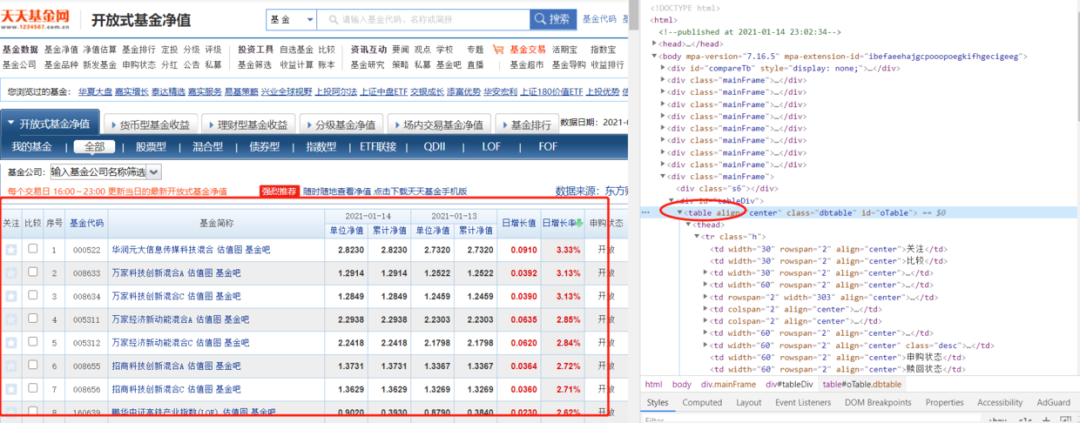
可以看到上面html里是table表格数据,刚好适合抓取。
import pandas as pd
url = "http://fund.eastmoney.com/fund.html"
data = pd.read_html(url,attrs = {'id': 'oTable'})
# 查看表格数量
tablenum = len(data)
print(tablenum)
输出:1
通过'id': 'oTable'的筛选后,只有一个表格,我们直接爬取到了基金净值表。
data[1]
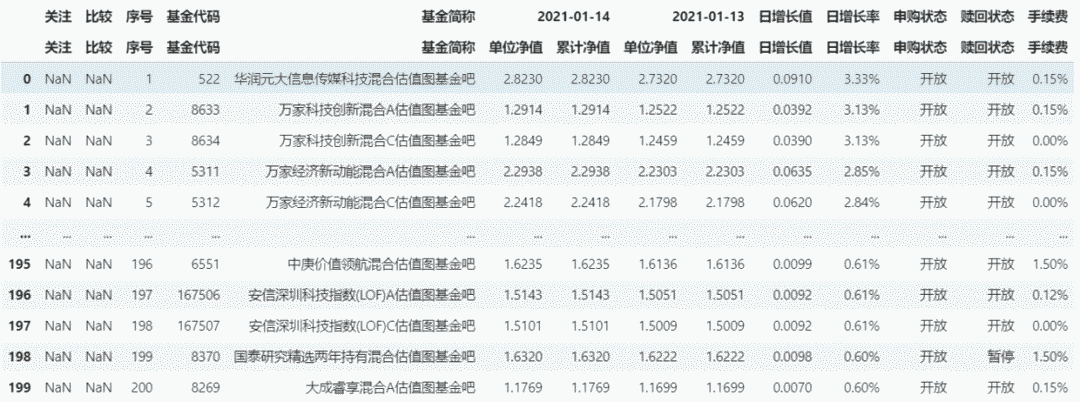
但这里只爬取了第一页的数据表,因为天天基金网基金净值数据每一页的url是相同的,所以read_html()函数无法获取其他页的表格,这可能运用了ajax动态加载技术来防止爬虫。
❝一般来说,一个爬虫对象的数据一次展现不完全时,就要多次展示,网站的处理办法有两种:
1、下一个页面的url和上一个页面的url不同,即每个页面的url是不同的,一般是是序号累加,处理方法是将所有的html页面下载至本地,从而拿到所有数据;(天天基金网显示不是这种类型)
❞
2、下一个页面的url和上一个页面的url相同,即展示所有数据的url是一样的,这样的话网页上一般会有“下一页”或“输入框”与“确认”按钮,处理方法是将代码中触发“下一页”或“输入框”与“确认”按钮点击事件来实现翻页,从而拿到所有数据。(天天基金网是这种类型)
刚只是简单地使用了read_html()获取web表格的功能,它还有更加复杂的用法,需要了解其参数含义。
详细用法
pandas.read_html( io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
详细参数
「io:」 str, path object 或 file-like objectURL,file-like对象或包含HTML的原始字符串。请注意,lxml仅接受http,ftp和文件url协议。如果您的网址以'https'您可以尝试删除's'。
「match:」 str 或 compiled regular expression, 可选参数将返回包含与该正则表达式或字符串匹配的文本的表集。除非HTML非常简单,否则您可能需要在此处传递非空字符串。默认为“。+”(匹配任何非空字符串)。默认值将返回页面上包含的所有表。此值转换为正则表达式,以便Beautiful Soup和lxml之间具有一致的行为。
「flavor:」 str 或 None要使用的解析引擎。‘bs4’和‘html5lib’彼此同义,它们都是为了向后兼容。默认值None尝试使用lxml解析,如果失败,它会重新出现bs4+html5lib。
「header:」 int 或 list-like 或 None, 可选参数该行(或MultiIndex)用于创建列标题。
「index_col:」 int 或 list-like 或 None, 可选参数用于创建索引的列(或列列表)。
「skiprows:」 int 或 list-like 或 slice 或 None, 可选参数解析列整数后要跳过的行数。从0开始。如果给出整数序列或切片,将跳过该序列索引的行。请注意,单个元素序列的意思是“跳过第n行”,而整数的意思是“跳过n行”。
「attrs:」 dict 或 None, 可选参数这是属性的词典,您可以传递该属性以用于标识HTML中的表。在传递给lxml或Beautiful Soup之前,不会检查它们的有效性。但是,这些属性必须是有效的HTML表属性才能正常工作。例如,
attrs = {'id': 'table'}
是有效的属性字典,因为‘id’ HTML标记属性是任何HTML标记的有效HTML属性,这个文件。attrs = {'asdf': 'table'}
不是有效的属性字典,因为‘asdf’即使是有效的XML属性,也不是有效的HTML属性。可以找到有效的HTML 4.01表属性这里。可以找到HTML 5规范的工作草案这里。它包含有关现代Web表属性的最新信息。
「parse_dates:」 bool, 可选参数参考read_csv()更多细节。
「thousands:」 str, 可选参数用来解析成千上万个分隔符。默认为','。
「encoding:」 str 或 None, 可选参数用于解码网页的编码。默认为NoneNone保留先前的编码行为,这取决于基础解析器库(例如,解析器库将尝试使用文档提供的编码)。
「decimal:」 str, 默认为 ‘.’可以识别为小数点的字符(例如,对于欧洲数据,请使用“,”)。
「converters:」 dict, 默认为 None用于在某些列中转换值的函数的字典。键可以是整数或列标签,值是采用一个输入参数,单元格(而非列)内容并返回转换后内容的函数。
「na_values:」 iterable, 默认为 None自定义NA值。
「keep_default_na:」 bool, 默认为 True如果指定了na_values并且keep_default_na为False,则默认的NaN值将被覆盖,否则将附加它们。
「displayed_only:」 bool, 默认为 True是否应解析具有“display:none”的元素。
最后, read_html() 仅支持静态网页解析,你可以通过其他方法获取动态页面加载后response.text 传入 read_html() 再获取表格数据。
往期精彩回顾
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: