
50种常见Matplotlib科研论文绘图合集!赶紧收藏~~
内容来源:和鲸社区
有效图表的重要特征:
在不歪曲事实的情况下传达正确和必要的信息。
设计简单,您不必太费力就能理解它。
从审美角度支持信息而不是掩盖信息。
信息没有超负荷。
关联图表用于可视化2个或更多变量之间的关系。也就是说,一个变量如何相对于另一个变化。
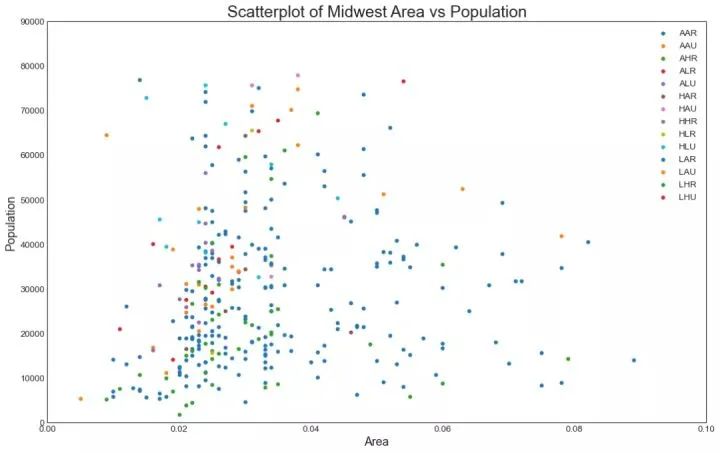
1、散点图(Scatter plot)
散点图是用于研究两个变量之间关系的经典的和基本的图表。如果数据中有多个组,则可能需要以不同颜色可视化每个组。在 matplotlib 中,您可以使用 plt.scatter() 方便地执行此操作。
np.unique():列表元素去重
当前的图表和子图可以使用plt.gcf()和plt.gca()获得,分别表示"Get Current Figure"和"Get Current Axes",这样可以方便的设置x,y轴显示范围及标签。
enumerate(sequence, [start=0])函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
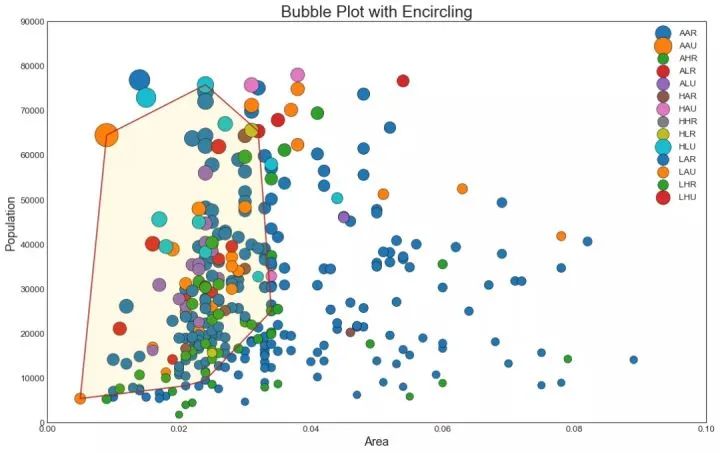
2、带边界的气泡图(Bubble plot with Encircling)
有时,您希望在边界内显示一组点以强调其重要性。在这个例子中,你从数据框中获取记录,并用下面代码中描述的 encircle() 来使边界显示出来。
np.r_是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等,类似于pandas中的concat()。
np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等,类似于pandas中的merge()。
ConvexHull:给定二维平面上的点集,凸包就是将最外层的点连接起来构成的凸多边型,它能包含点集中所有的点。
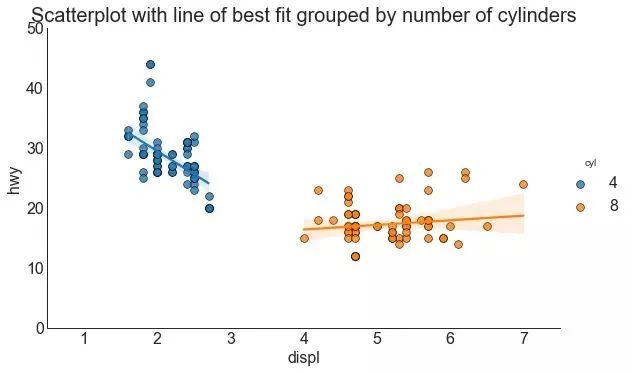
3、带线性回归最佳拟合线的散点图 (Scatter plot with linear regression line of best fit)
如果你想了解两个变量如何相互改变,那么最佳拟合线就是常用的方法。下图显示了数据中各组之间最佳拟合线的差异。要禁用分组并仅为整个数据集绘制一条最佳拟合线,请从下面的sns.lmplot()调用中删除hue ='cyl'参数。
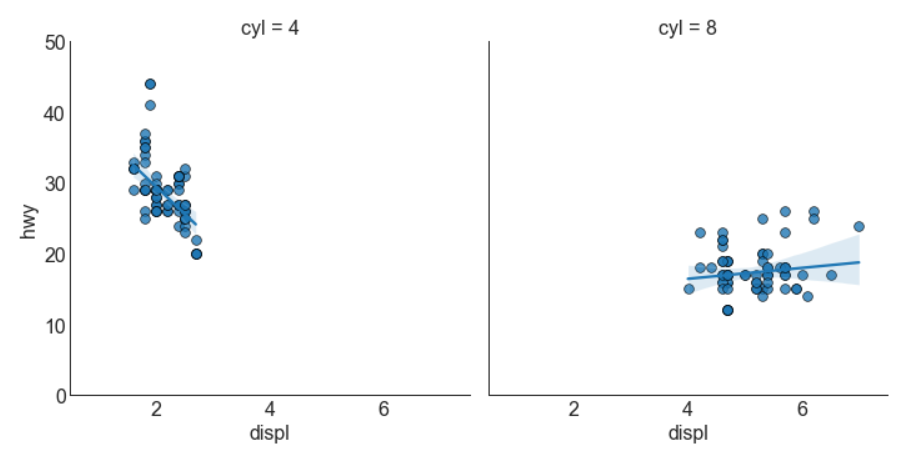
针对每列绘制线性回归线
或者,可以在其每列中显示每个组的最佳拟合线。可以通过在 sns.lmplot() 中设置 col=groupingcolumn 参数来实现,如下:
4、抖动图 (Jittering with stripplot)
通常,多个数据点具有完全相同的 X 和 Y 值。结果,多个点绘制会重叠并隐藏。为避免这种情况,请将数据点稍微抖动,以便您可以直观地看到它们。使用 seaborn 的 stripplot() 很方便实现这个功能。
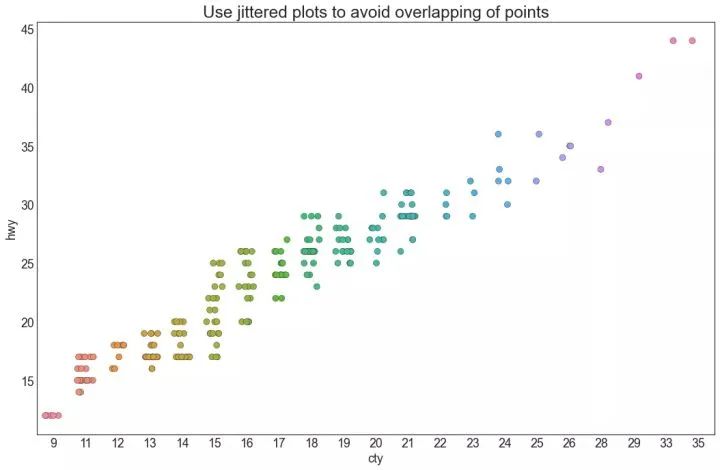
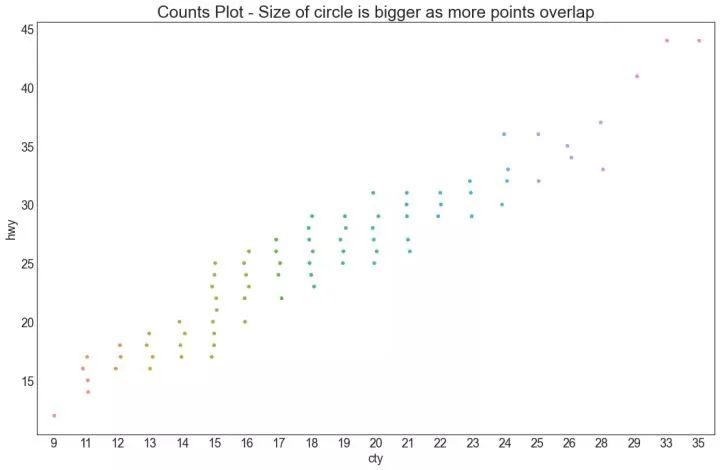
5、计数图 (Counts Plot)
避免点重叠问题的另一个选择是增加点的大小,这取决于该点中有多少点。因此,点的大小越大,其周围的点的集中度越高。
groupby操作涉及拆分对象,应用函数和组合结果的某种组合。这可用于对这些组上的大量数据和计算操作进行分组。
reset_index重置DataFrame的索引,并使用默认值。如果DataFrame具有MultiIndex,则此方法可以删除一个或多个级别。
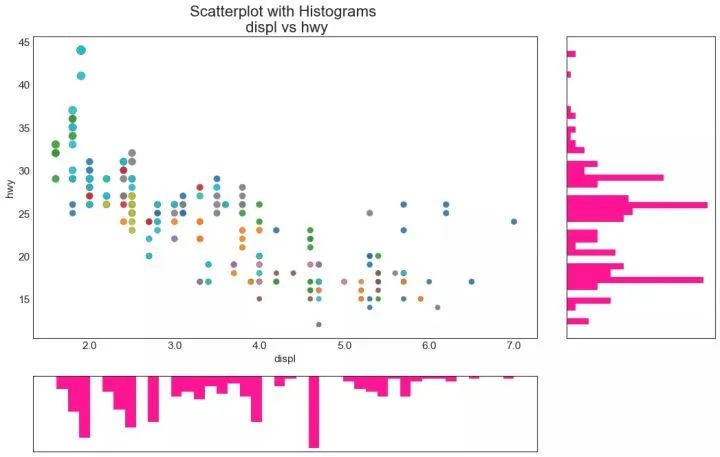
6、边缘直方图 (Marginal Histogram)
边缘直方图具有沿 X 和 Y 轴变量的直方图。这用于可视化 X 和 Y 之间的关系以及单独的 X 和 Y 的单变量分布。这种图经常用于探索性数据分析(EDA)。
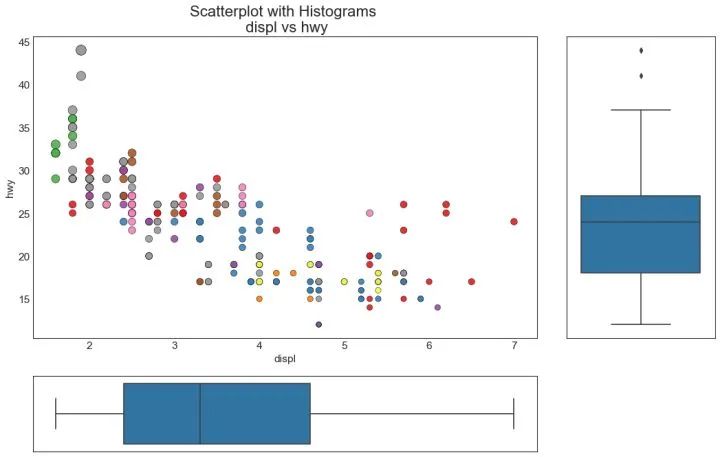
7、边缘箱形图 (Marginal Boxplot)
边缘箱图与边缘直方图具有相似的用途。然而,箱线图有助于精确定位 X 和 Y 的中位数、第25和第75百分位数。
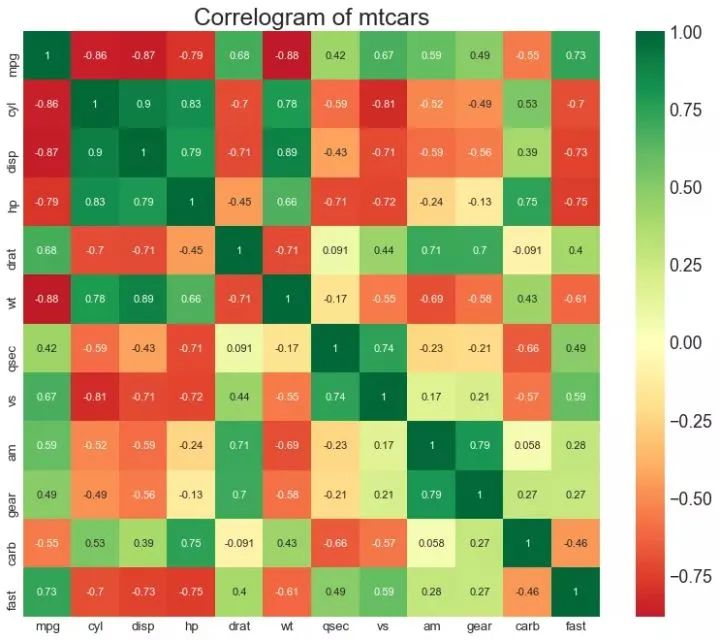
8、相关图 (Correllogram)
相关图用于直观地查看给定数据框(或二维数组)中所有可能的数值变量对之间的相关度量。
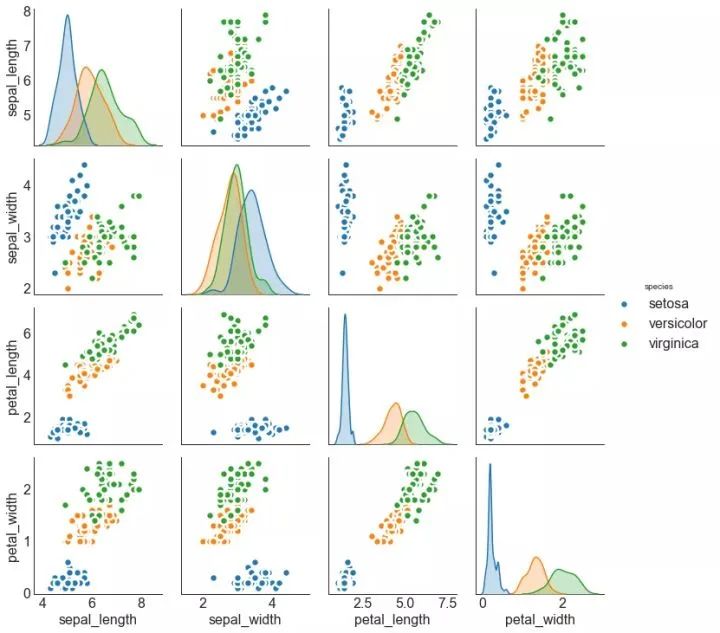
9、矩阵图 (Pairwise Plot)
矩阵图是探索性分析中的最爱,用于理解所有可能的数值变量对之间的关系。它是双变量分析的必备工具。
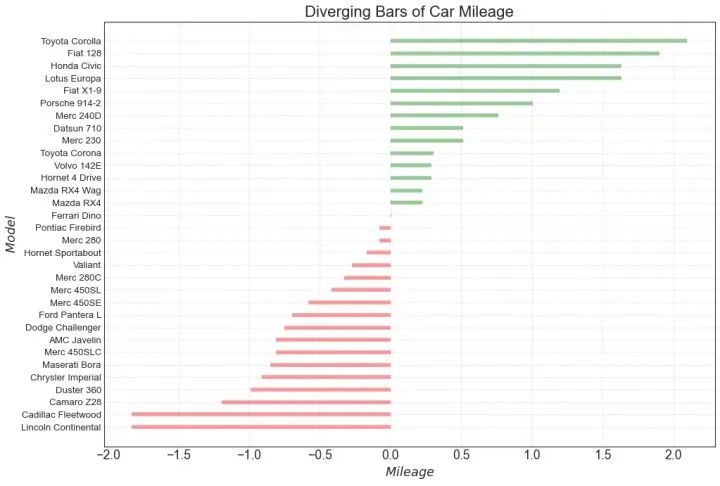
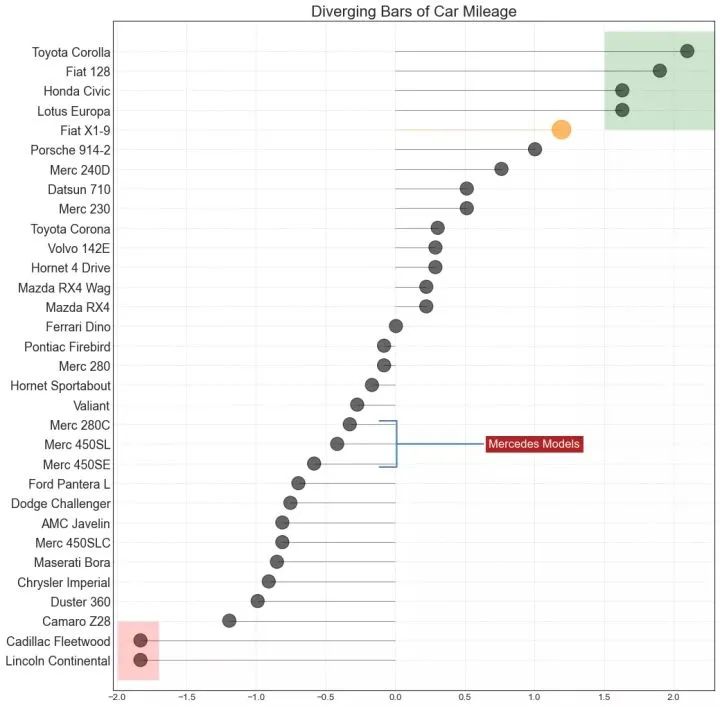
10、发散型条形图 (Diverging Bars)
如果您想根据单个指标查看项目的变化情况,并可视化此差异的顺序和数量,那么散型条形图 (Diverging Bars) 是一个很好的工具。它有助于快速区分数据中组的性能,并且非常直观,并且可以立即传达这一点。
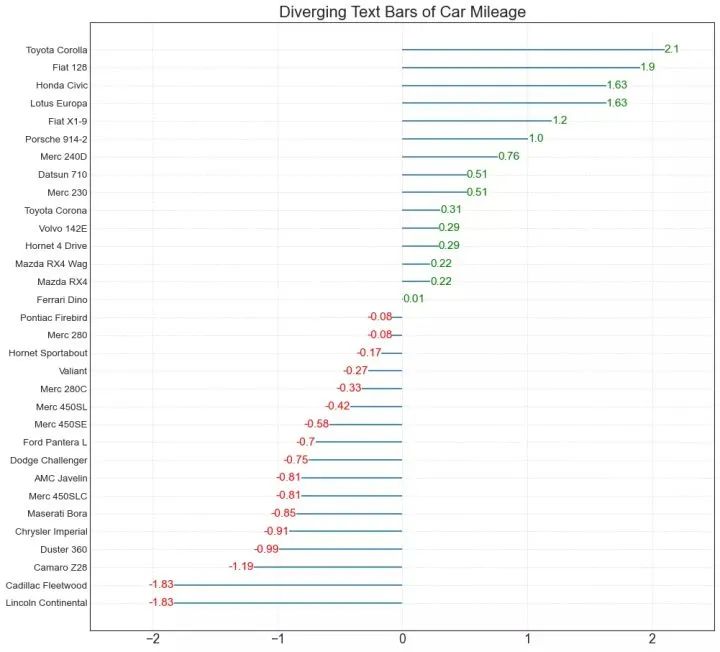
11、发散型文本 (Diverging Texts)
发散型文本 (Diverging Texts)与发散型条形图 (Diverging Bars)相似,如果你想以一种漂亮和可呈现的方式显示图表中每个项目的价值,就可以使用这种方法。
12、发散型包点图 (Diverging Dot Plot)
发散型包点图 (Diverging Dot Plot)也类似于发散型条形图 (Diverging Bars)。然而,与发散型条形图 (Diverging Bars)相比,条的缺失减少了组之间的对比度和差异。
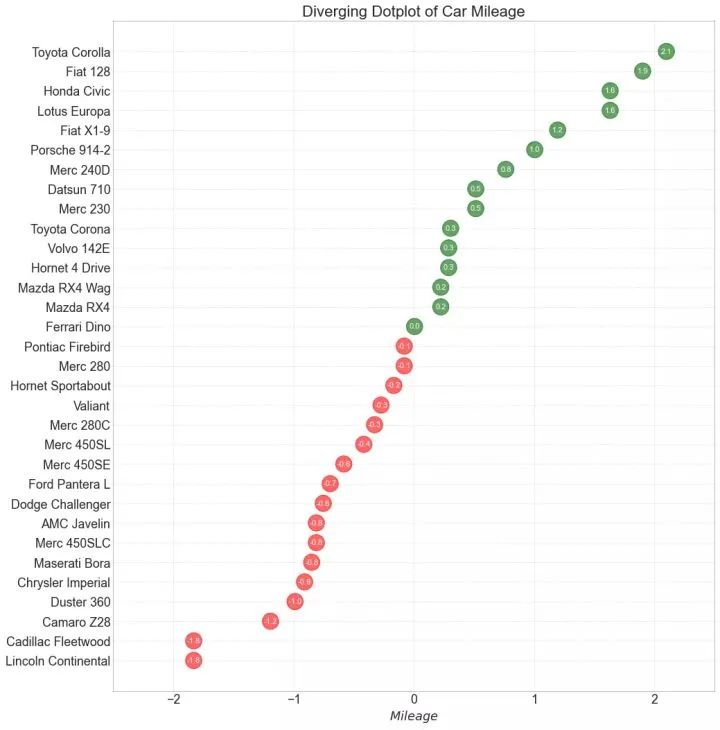
13、带标记的发散型棒棒糖图 (Diverging Lollipop Chart with Markers)
带标记的棒棒糖图通过强调您想要引起注意的任何重要数据点并在图表中适当地给出推理,提供了一种对差异进行可视化的灵活方式。
14、面积图 (Area Chart)
通过对轴和线之间的区域进行着色,面积图不仅强调峰和谷,而且还强调高点和低点的持续时间。高点持续时间越长,线下面积越大。
这里annotate的函数值得学习,台风路径信息的框框或者文字避让算法,都需要用到这个函数。
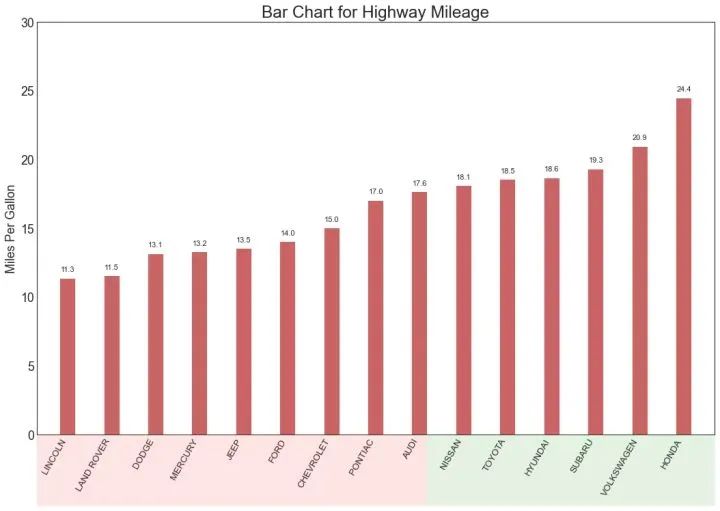
15、有序条形图 (Ordered Bar Chart)
有序条形图有效地传达了项目的排名顺序。但是,在图表上方添加度量标准的值,用户可以从图表本身获取精确信息。
16、棒棒糖图 (Lollipop Chart)
棒棒糖图表以一种视觉上令人愉悦的方式提供与有序条形图类似的目的。
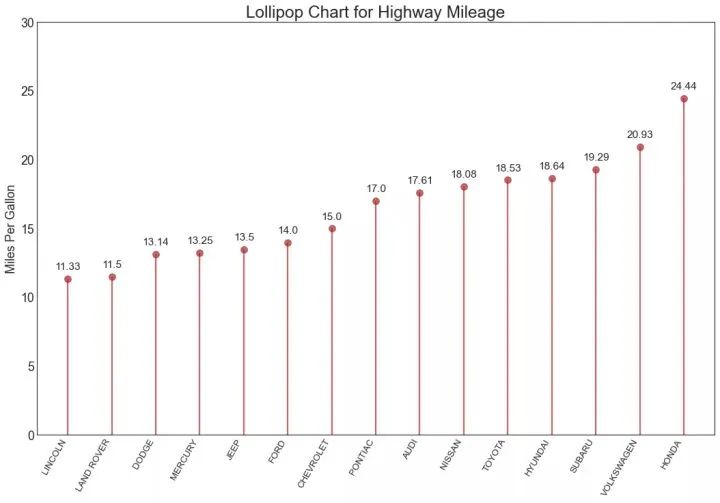
17、包点图 (Dot Plot)
包点图表传达了项目的排名顺序,并且由于它沿水平轴对齐,因此您可以更容易地看到点彼此之间的距离。
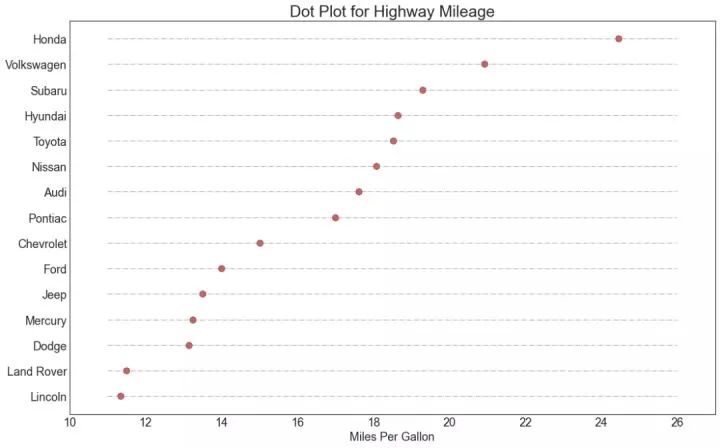
18、坡度图 (Slope Chart)
坡度图最适合比较给定人/项目的“前”和“后”位置。
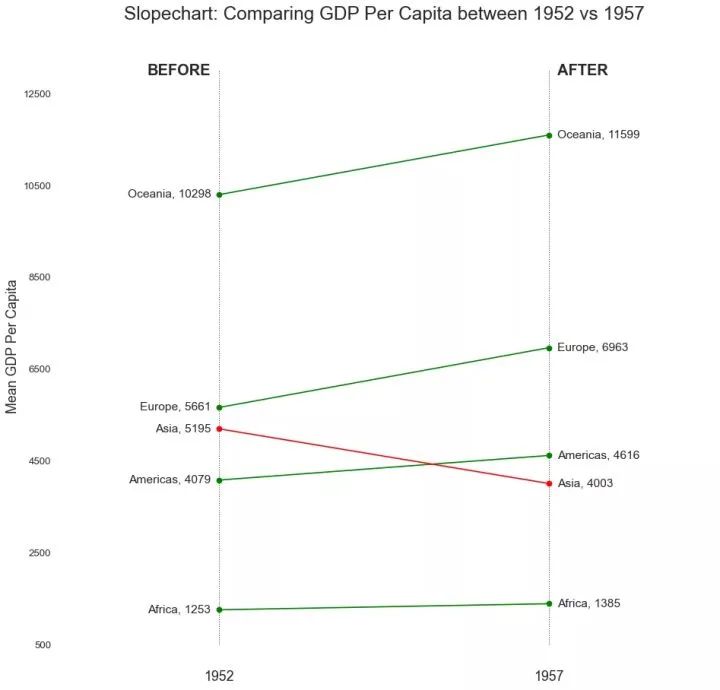
19、哑铃图 (Dumbbell Plot)
哑铃图表传达了各种项目的“前”和“后”位置以及项目的等级排序。如果您想要将特定项目/计划对不同对象的影响可视化,那么它非常有用。
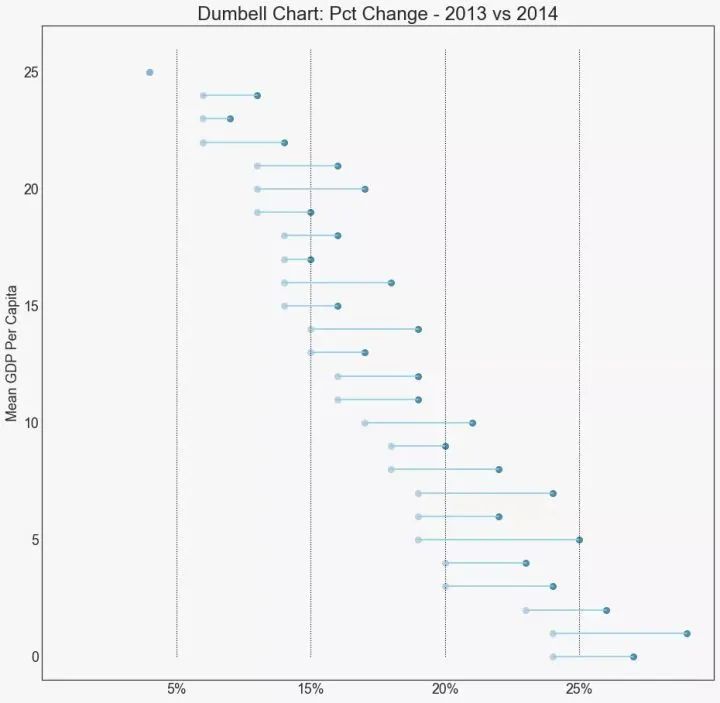
20、连续变量的直方图 (Histogram for Continuous Variable)
直方图显示给定变量的频率分布。下面的图表示基于类型变量对频率条进行分组,从而更好地了解连续变量和类型变量。
也可以看成堆叠图的形式,同样适用于空气质量的分级。
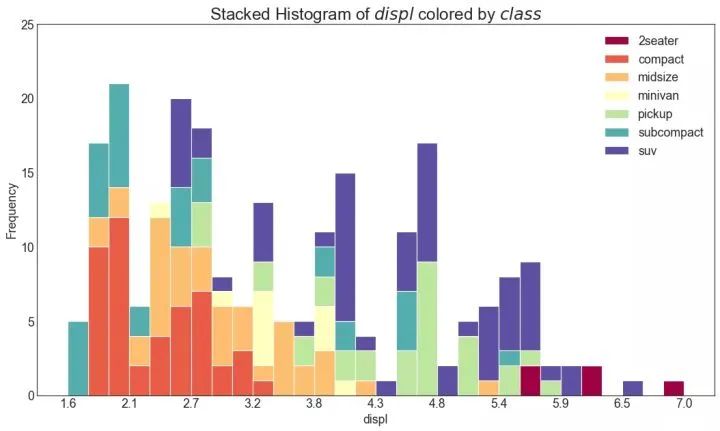
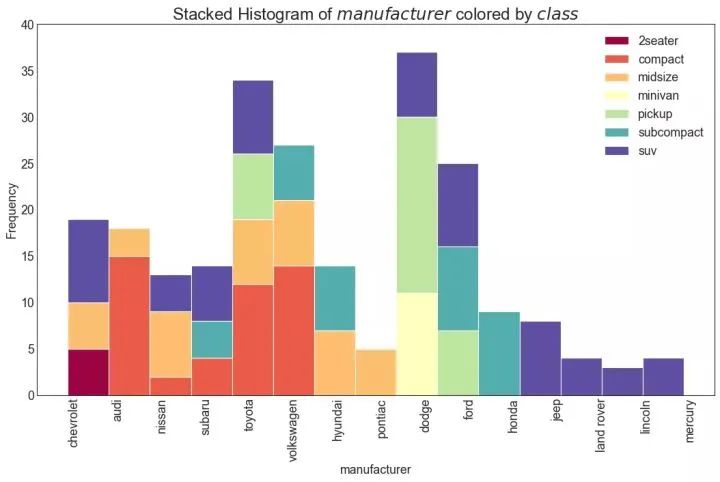
21、类型变量的直方图 (Histogram for Categorical Variable)
类型变量的直方图显示该变量的频率分布。通过对条形图进行着色,可以将分布与表示颜色的另一个类型变量相关联。
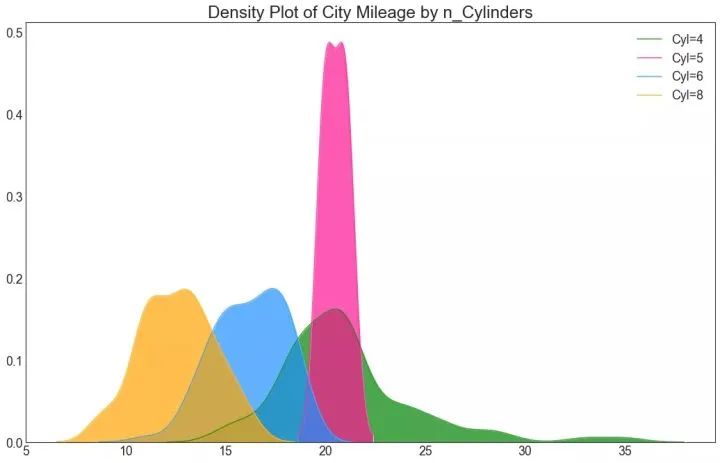
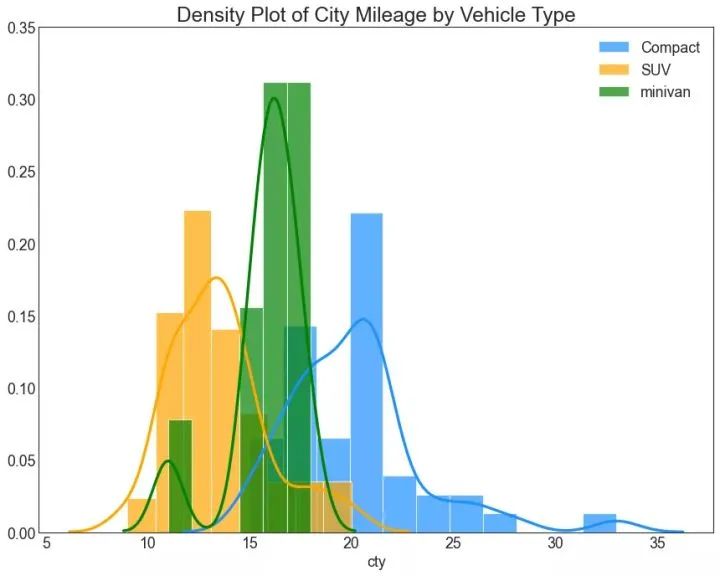
22、密度图 (Density Plot)
密度图是一种常用工具,用于可视化连续变量的分布。通过“响应”变量对它们进行分组,您可以检查 X 和 Y 之间的关系。以下情况用于表示目的,以描述城市里程的分布如何随着汽缸数的变化而变化。
23、直方密度线图 (Density Curves with Histogram)
带有直方图的密度曲线汇集了两个图所传达的集体信息,因此您可以将它们放在一个图中而不是两个图中。
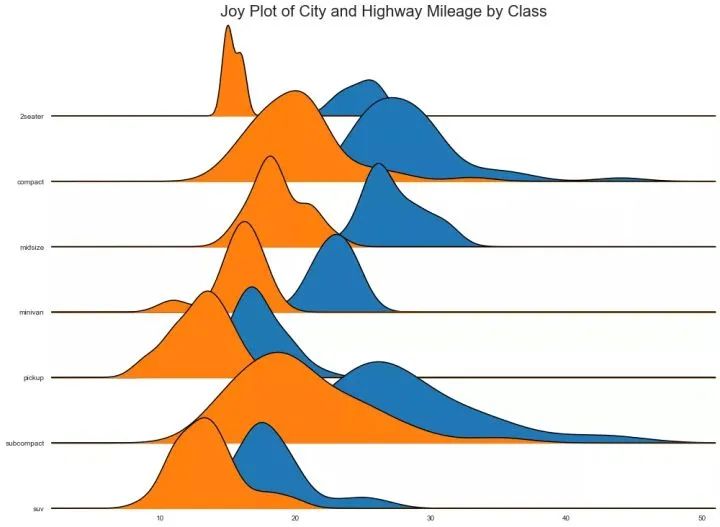
24、Joy Plot
Joy Plot允许不同组的密度曲线重叠,这是一种可视化大量分组数据的彼此关系分布的好方法。它看起来很悦目,并清楚地传达了正确的信息。它可以使用基于 matplotlib 的 joypy 包轻松构建。(需要安装 joypy 库)
25、分布式包点图 (Distributed Dot Plot)
分布式包点图显示按组分割的点的单变量分布。点数越暗,该区域的数据点集中度越高。通过对中位数进行不同着色,组的真实定位立即变得明显。
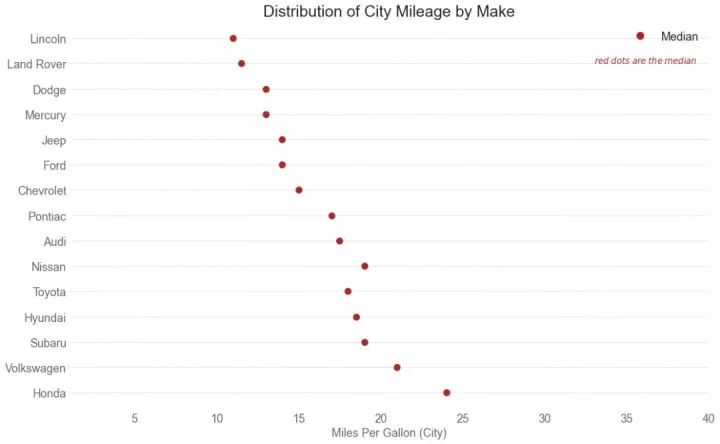
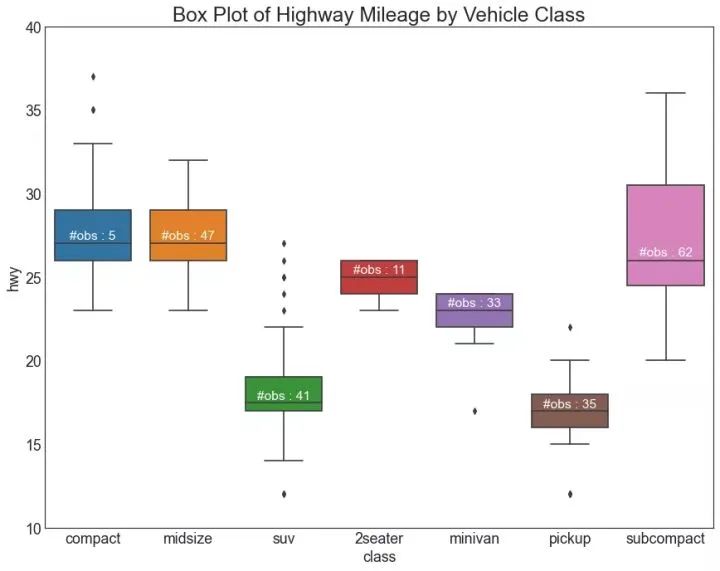
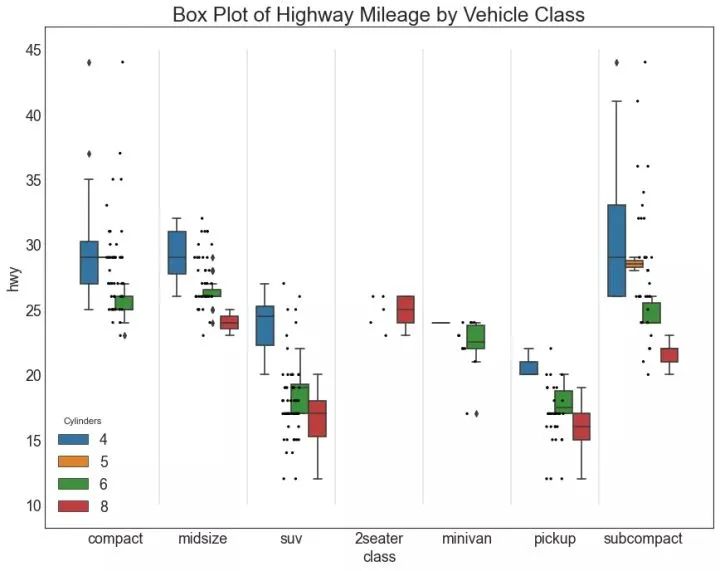
26、箱形图 (Box Plot)
箱形图是一种可视化分布的好方法,记住中位数、第25个第45个四分位数和异常值。但是,您需要注意解释可能会扭曲该组中包含的点数的框的大小。因此,手动提供每个框中的观察数量可以帮助克服这个缺点。
例如,左边的前两个框具有相同大小的框,即使它们的值分别是5和47。因此,写入该组中的观察数量是必要的。
27、包点+箱形图 (Dot + Box Plot)
包点+箱形图 (Dot + Box Plot)传达类似于分组的箱形图信息。此外,这些点可以了解每组中有多少数据点。
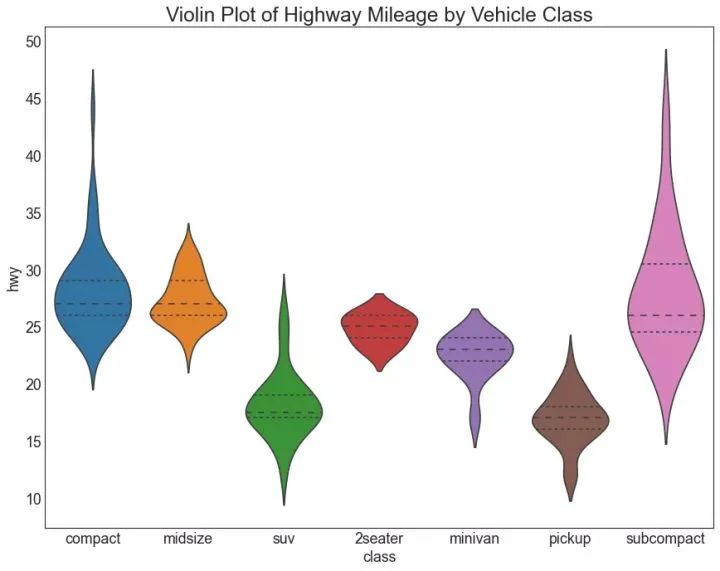
28、小提琴图 (Violin Plot)
小提琴图是箱形图在视觉上令人愉悦的替代品。小提琴的形状或面积取决于它所持有的观察次数。但是,小提琴图可能更难以阅读,并且在专业设置中不常用。
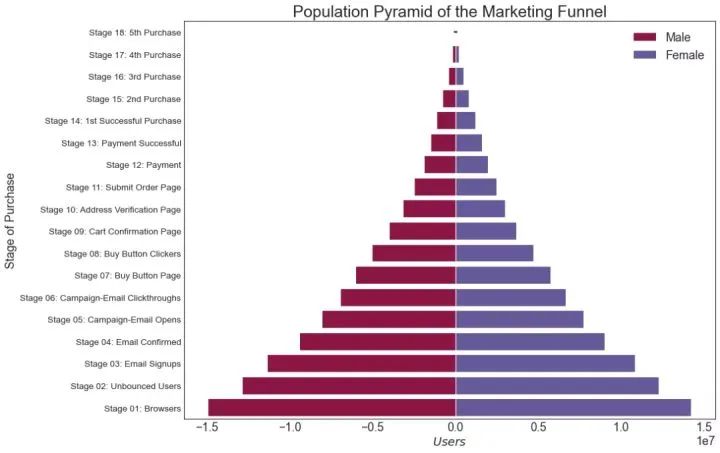
29、人口金字塔 (Population Pyramid)
人口金字塔可用于显示由数量排序的组的分布。或者它也可以用于显示人口的逐级过滤,因为它在下面用于显示有多少人通过营销渠道的每个阶段。
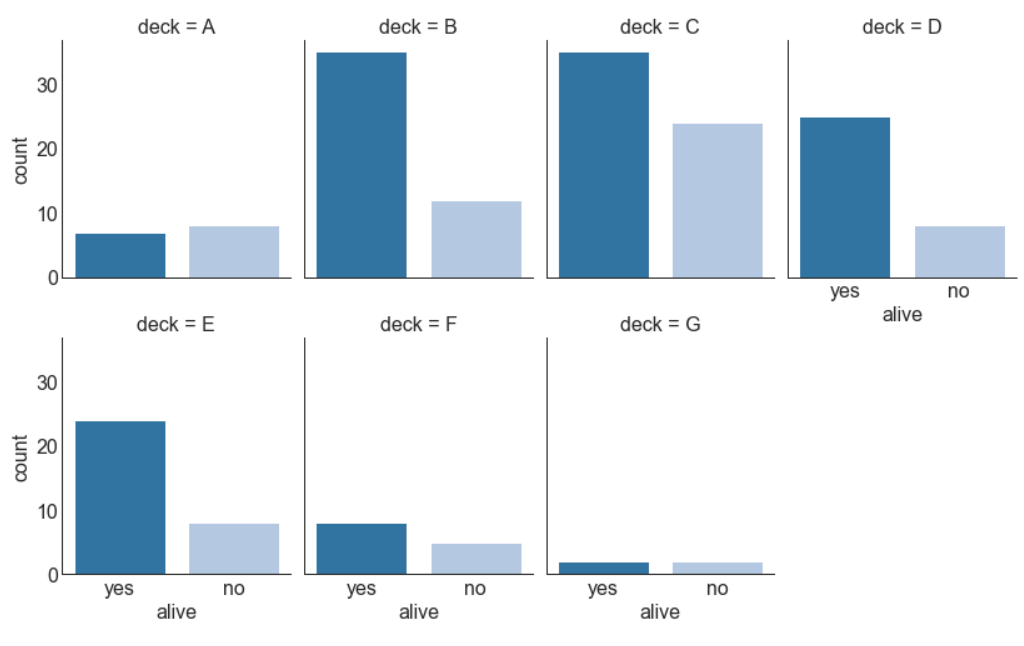
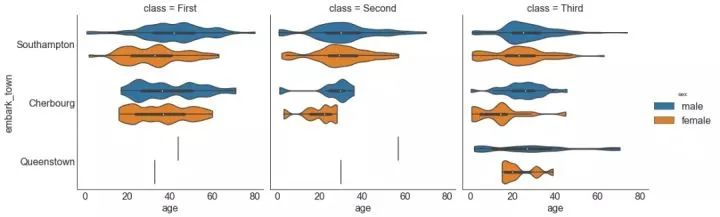
30、分类图 (Categorical Plots)
由 seaborn库 提供的分类图可用于可视化彼此相关的2个或更多分类变量的计数分布。
31、华夫饼图 (Waffle Chart)
可以使用 pywaffle包 创建华夫饼图,并用于显示更大群体中的组的组成。(需要安装 pywaffle 库)
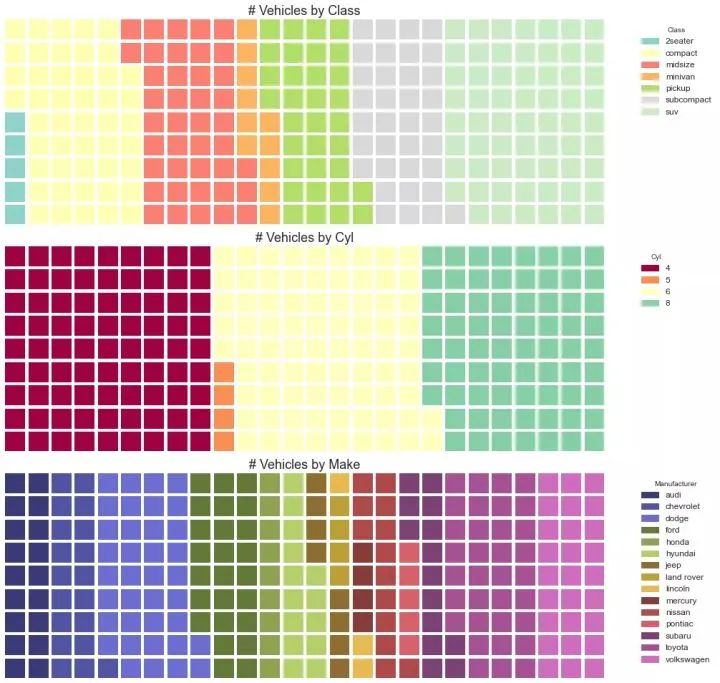
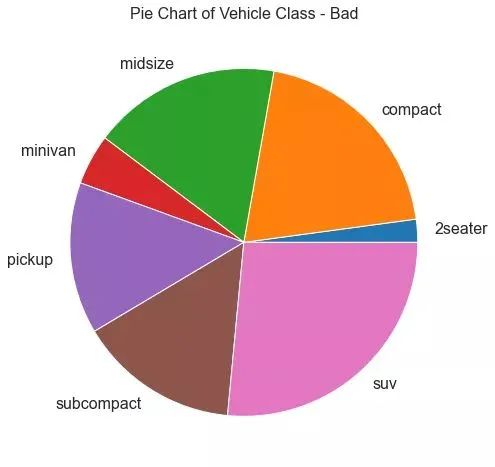
32、饼图 (Pie Chart)
饼图是显示组成的经典方式。然而,现在通常不建议使用它,因为馅饼部分的面积有时会变得误导。因此,如果您要使用饼图,强烈建议明确记下饼图每个部分的百分比或数字。
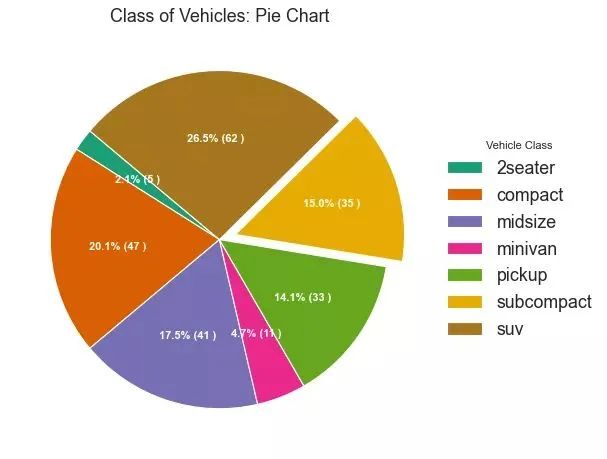
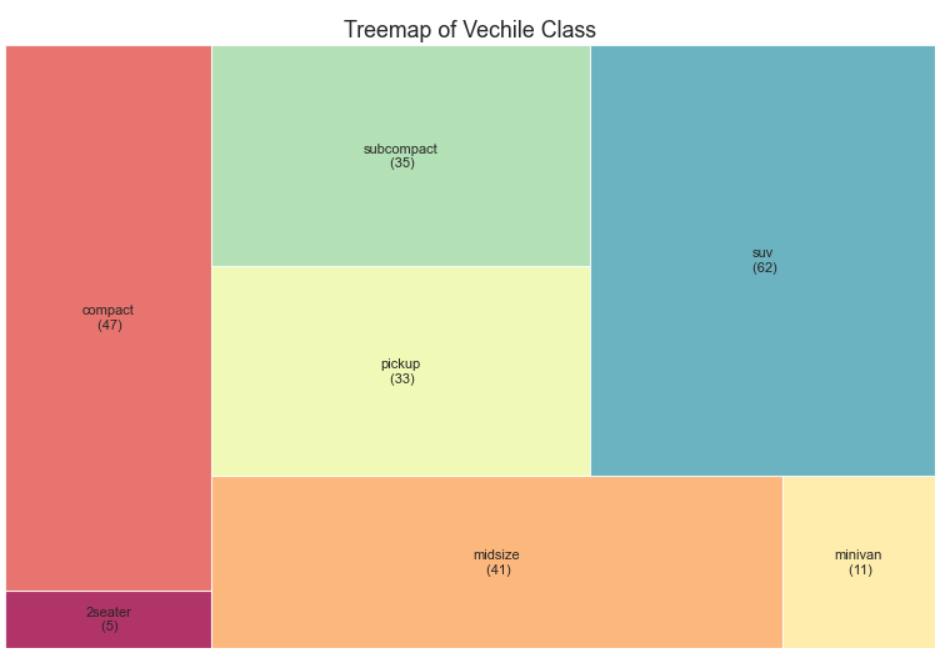
33、树形图 (Treemap)
树形图类似于饼图,它可以更好地完成工作而不会误导每个组的贡献。(需要安装 squarify 库)
34、条形图 (Bar Chart)
条形图是基于计数或任何给定指标可视化项目的经典方式。在下面的图表中,我为每个项目使用了不同的颜色,但您通常可能希望为所有项目选择一种颜色,除非您按组对其进行着色。颜色名称存储在下面代码中的all_colors中。您可以通过在plt.plot()中设置颜色参数来更改条的颜色。
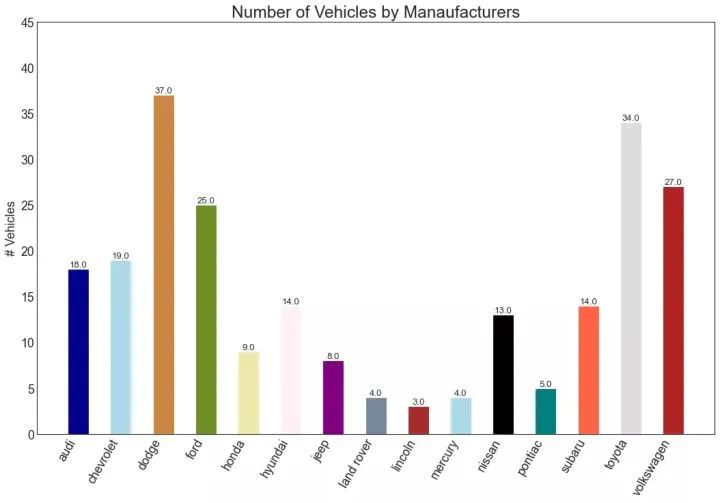
变化 (Change)
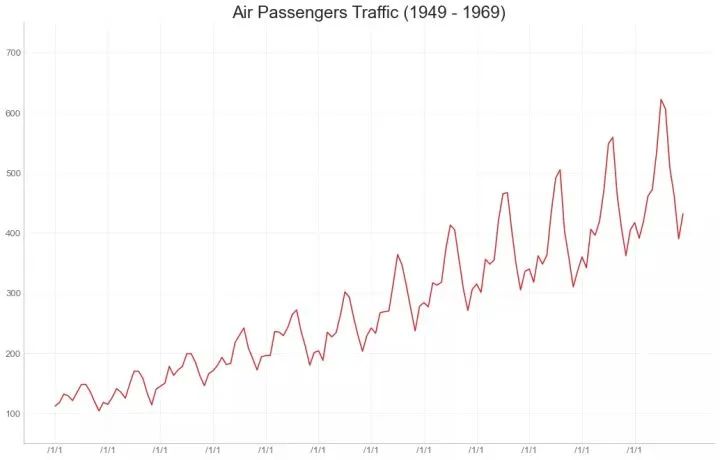
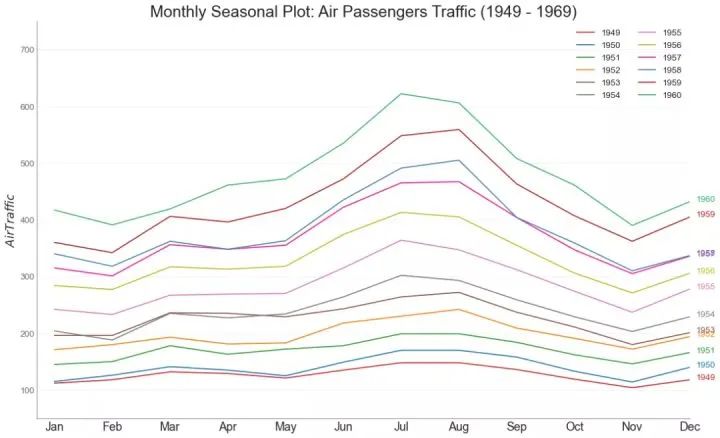
35、时间序列图 (Time Series Plot)
时间序列图用于显示给定度量随时间变化的方式。在这里,您可以看到 1949年 至 1969年间航空客运量的变化情况。
plt.plot('date', 'traffic', data = df):其中前两项即为df的表头
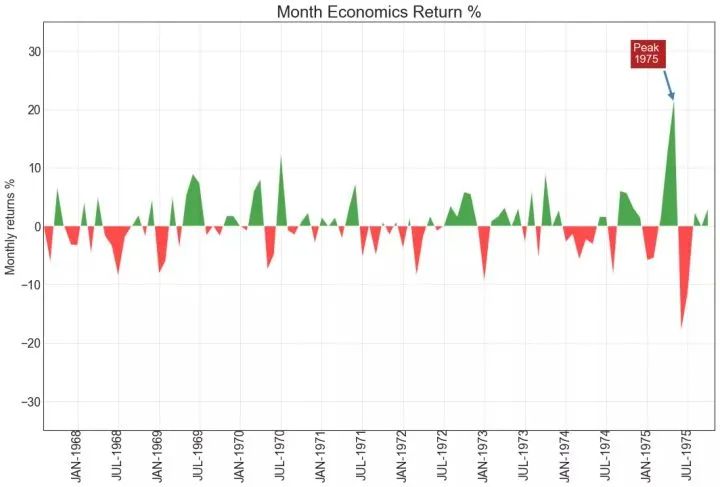
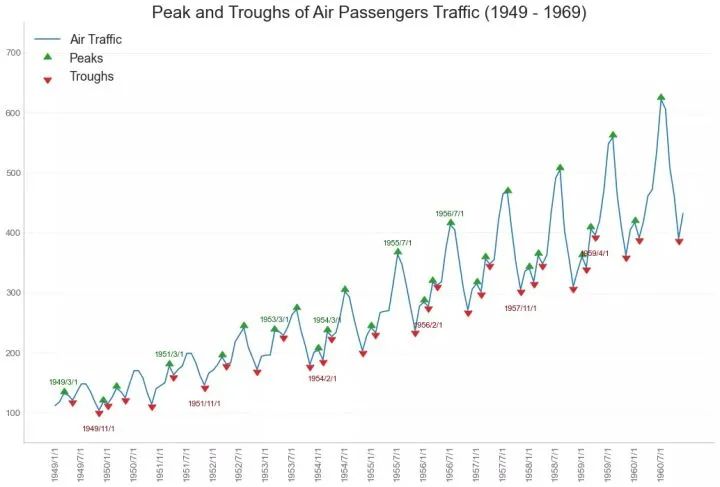
36、带波峰波谷标记的时序图 (Time Series with Peaks and Troughs Annotated)
下面的时间序列绘制了所有峰值和低谷,并注释了所选特殊事件的发生。
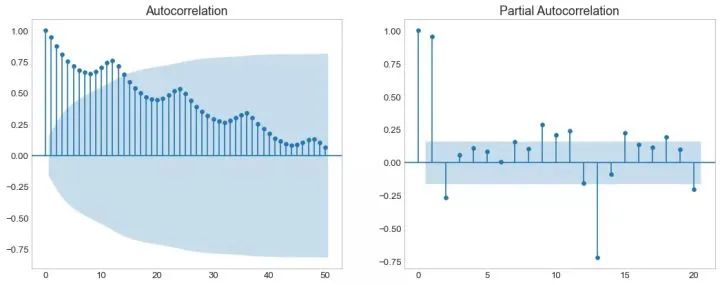
37、自相关和部分自相关图 (Autocorrelation (ACF) and Partial Autocorrelation (PACF) Plot)
自相关图(ACF图)显示时间序列与其自身滞后的相关性。每条垂直线(在自相关图上)表示系列与滞后0之间的滞后之间的相关性。图中的蓝色阴影区域是显着性水平。那些位于蓝线之上的滞后是显着的滞后。
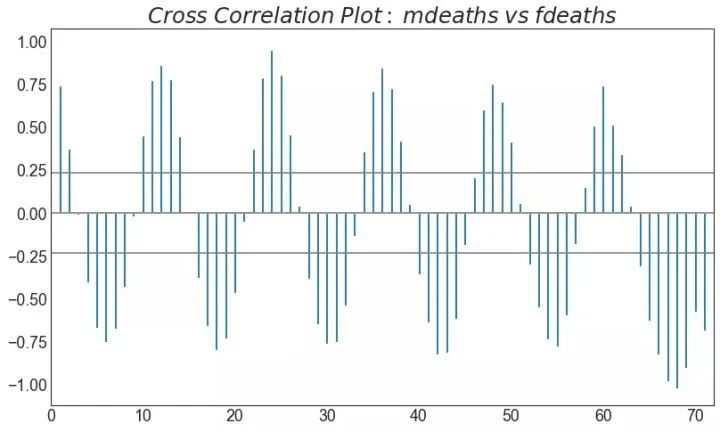
38、交叉相关图 (Cross Correlation plot)
交叉相关图显示了两个时间序列相互之间的滞后。
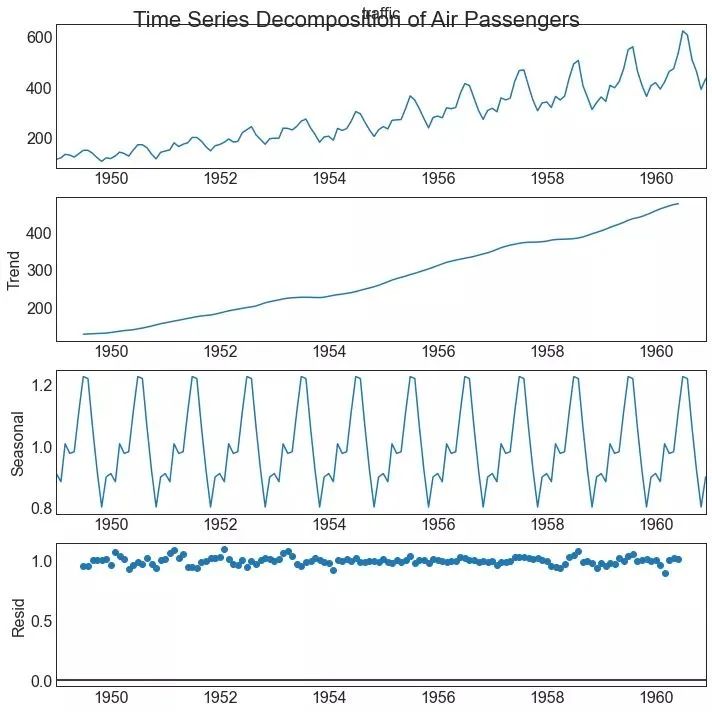
39、时间序列分解图 (Time Series Decomposition Plot)
时间序列分解图显示时间序列分解为趋势,季节和残差分量。
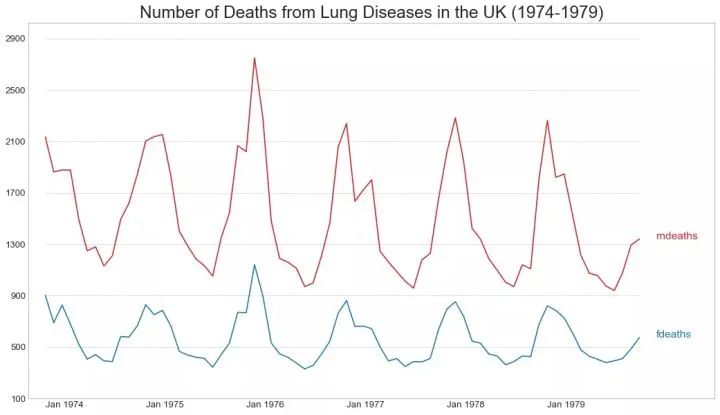
40、多个时间序列 (Multiple Time Series)
您可以绘制多个时间序列,在同一图表上测量相同的值,如下所示。
41、使用辅助 Y 轴来绘制不同范围的图形 (Plotting with different scales using secondary Y axis)
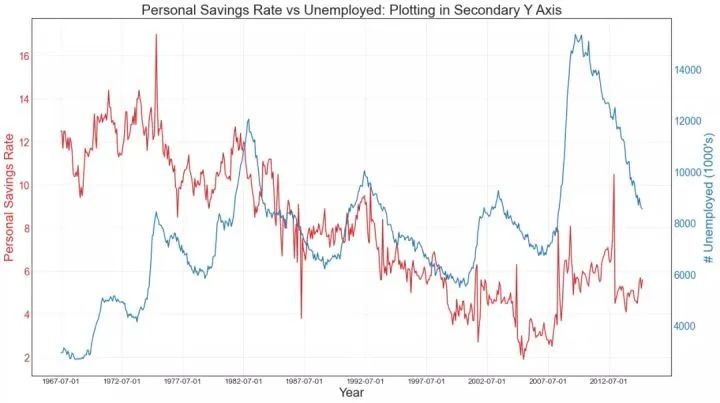
如果要显示在同一时间点测量两个不同数量的两个时间序列,则可以在右侧的辅助Y轴上再绘制第二个系列。
42、带有误差带的时间序列 (Time Series with Error Bands)
如果您有一个时间序列数据集,每个时间点(日期/时间戳)有多个观测值,则可以构建带有误差带的时间序列。您可以在下面看到一些基于每天不同时间订单的示例。另一个关于45天持续到达的订单数量的例子。
在该方法中,订单数量的平均值由白线表示。并且计算95%置信区间并围绕均值绘制。
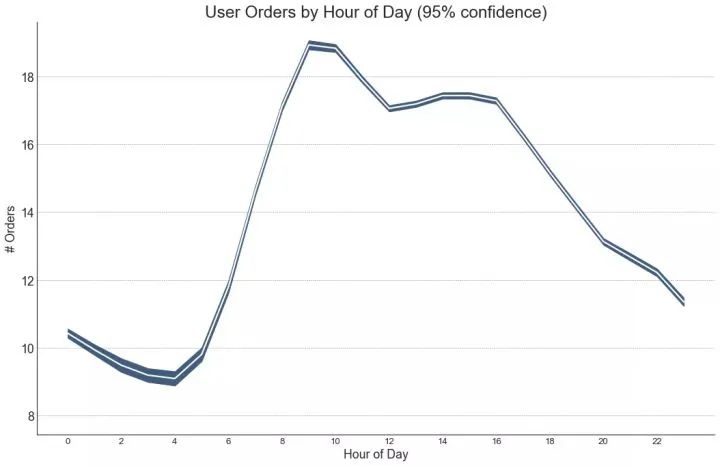
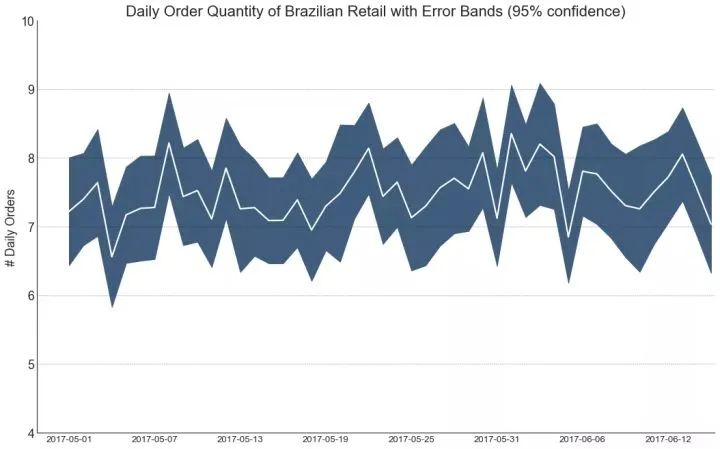
43、堆积面积图 (Stacked Area Chart)
堆积面积图可以直观地显示多个时间序列的贡献程度,因此很容易相互比较。
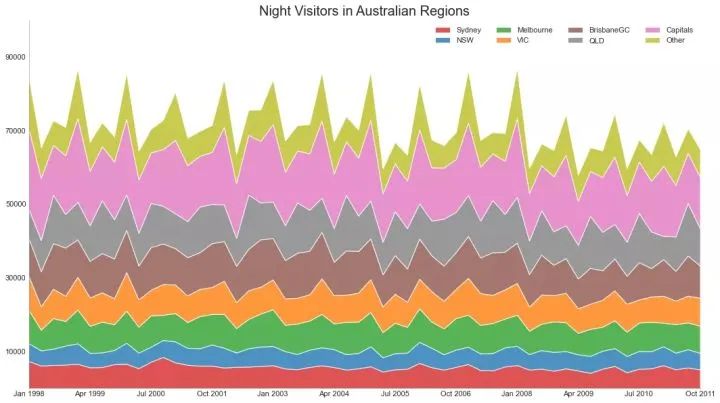
44、未堆积的面积图 (Area Chart UnStacked)
未堆积面积图用于可视化两个或更多个系列相对于彼此的进度(起伏)。在下面的图表中,您可以清楚地看到随着失业中位数持续时间的增加,个人储蓄率会下降。未堆积面积图表很好地展示了这种现象。
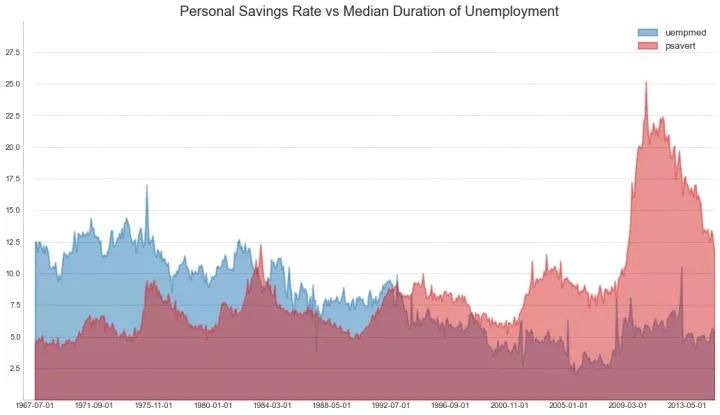
45、日历热力图 (Calendar Heat Map)
与时间序列相比,日历地图是可视化基于时间的数据的备选和不太优选的选项。虽然可以在视觉上吸引人,但数值并不十分明显。然而,它可以很好地描绘极端值和假日效果。(需要安装 calmap 库)
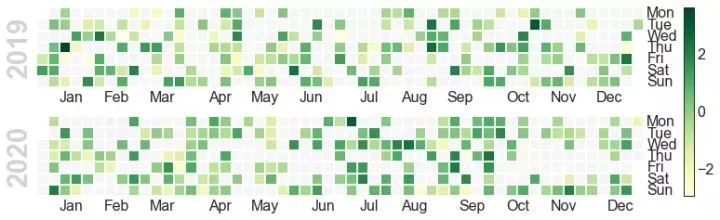
46、季节图 (Seasonal Plot)
季节图可用于比较上一季中同一天(年/月/周等)的时间序列。
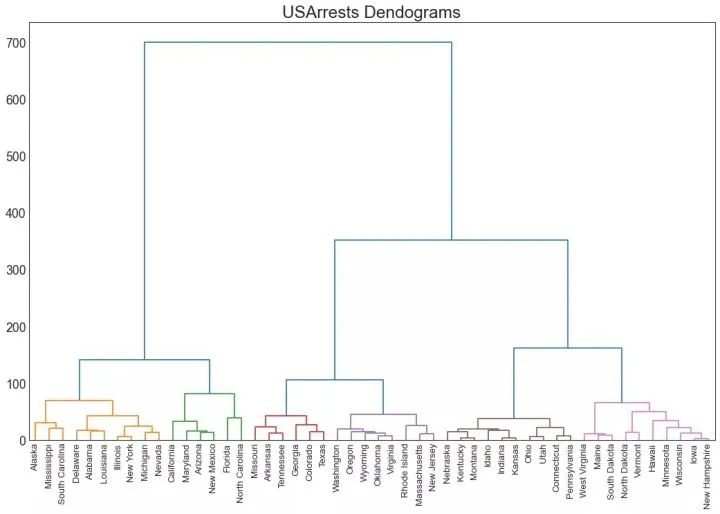
47、树状图 (Dendrogram)
树形图基于给定的距离度量将相似的点组合在一起,并基于点的相似性将它们组织在树状链接中。
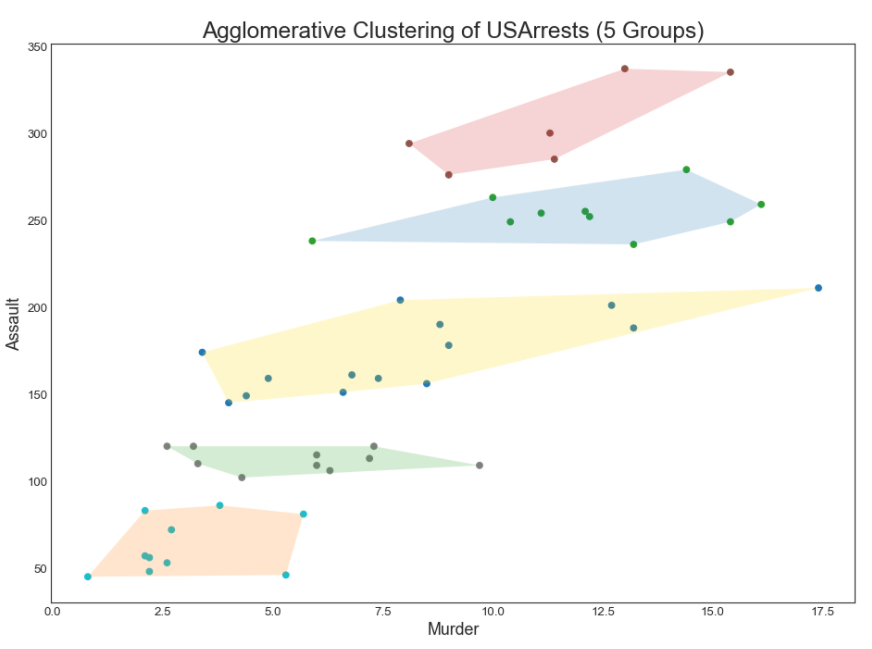
48、簇状图 (Cluster Plot)
簇状图 (Cluster Plot)可用于划分属于同一群集的点。下面是根据USArrests数据集将美国各州分为5组的代表性示例。此图使用“谋杀”和“攻击”列作为X和Y轴。或者,您可以将第一个到主要组件用作X轴和Y轴。
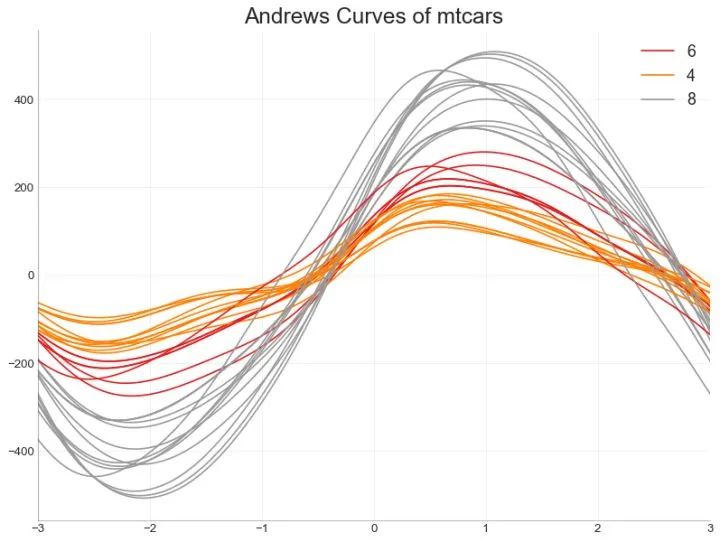
49、安德鲁斯曲线 (Andrews Curve)
安德鲁斯曲线有助于可视化是否存在基于给定分组的数字特征的固有分组。如果要素(数据集中的列)无法区分组(cyl),那么这些线将不会很好地隔离,如下所示。
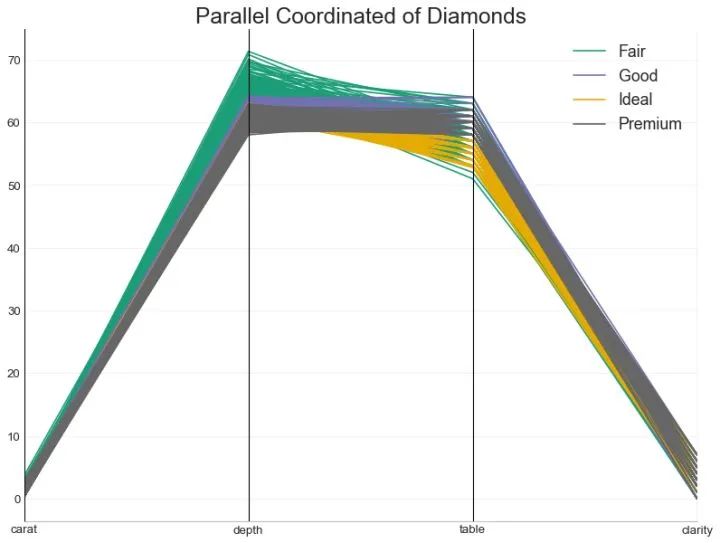
50、平行坐标 (Parallel Coordinates)
平行坐标有助于可视化特征是否有助于有效地隔离组。如果实现隔离,则该特征可能在预测该组时非常有用。
内容来源:和鲸社区,仅用于学术分享,著作权归作者所有。如有侵权,请联系后台作删文处理。
- END - 对比Excel系列图书累积销量达15w册,让你轻松掌握数据分析技能,可以点击下方链接进行了解选购: