AI看图说话首超人类!微软认知AI团队提出视觉词表预训练超越Transformer
共
2791字,需浏览
6分钟
·
2020-10-18 16:15

编辑:白峰
【新智元导读】能看图会说话的AI,表现还超过了人类?最近,Azure悄然上线了一个新的人工智能服务,能精准的说出图片中的内容。而背后的视觉词表技术,更是超越了基于Transformer的前辈们,拿到nocaps挑战赛冠军。
现在很多搜索引擎都是基于图片的文本标签,但是我们的世界每天产生不计其数的照片,很多都没有标记直接传到了网上,给图片搜索带来了很多混乱。如果系统能自动给图片加上精准的描述,图像搜索的效率将大为提高。
看图说话的AI:基于模板和Transformer都不尽如人意看图说话(或者叫图像描述),近年来受到了很多关注,它可以自动生成图片描述。但是目前无论是学术界还是工业界,做的效果都差强人意。
看图说话系统一方面需要计算机视觉进行图像的识别,另一方面需要自然语言来描述识别到的物体。带标签的图片可以针对性训练,那如果出现了从未标注的新物体,系统是不是就失效了?这个问题困扰了人们很久,即描述清楚一个新出现的东西。人工智能领域验证一个模型的好坏,通常会用一个基准测试。比如NLP方向会用GLUE、SuperGLUE等,图像识别会用ImageNet等。为了测试模型能否在没有训练数据的情况下完成看图说话,nocaps应运而生。nocaps可以衡量模型能否准确描述未出现过的物体。传统的看图说话方法主要有两种:一种是模板生成,一种是基于 Transformer 的图像文本交互预训练。模板生成方法,在简单场景下可以使用,但无法捕捉深层次的图像文本关系,而基于Transformer的模型又需要海量的标注数据,所以不适合nocaps。为解决这些问题,微软认知服务团队的研究人员提出了一种名为视觉词表预训练(Visual Vocabulary Pre-training,简称VIVO)的解决方案。
无需配对图文数据,VIVO看图说话夺冠nocaps首次超越人类
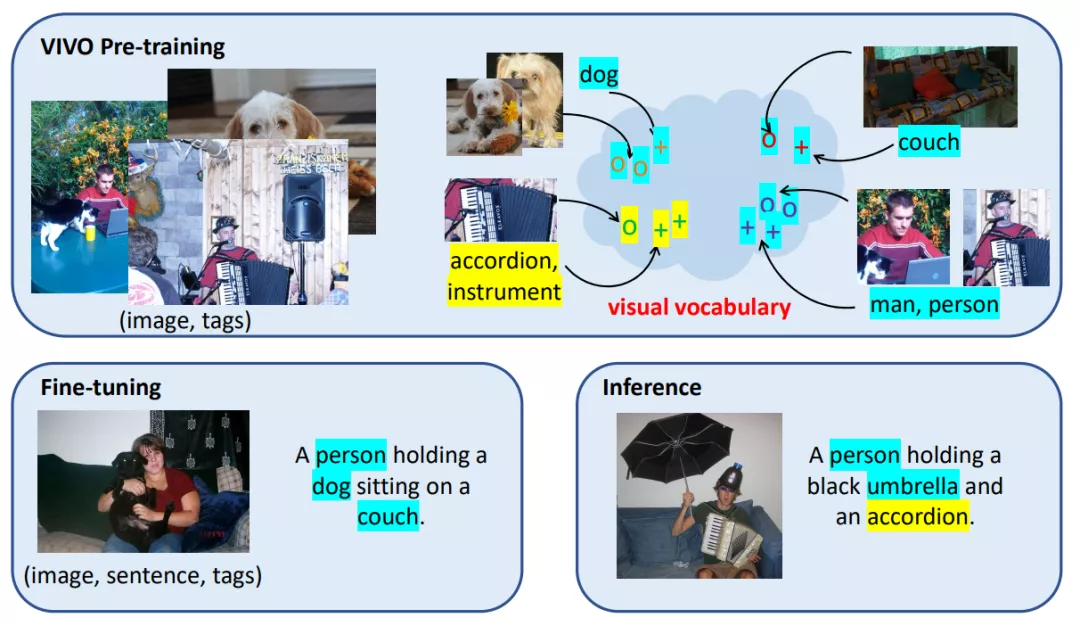
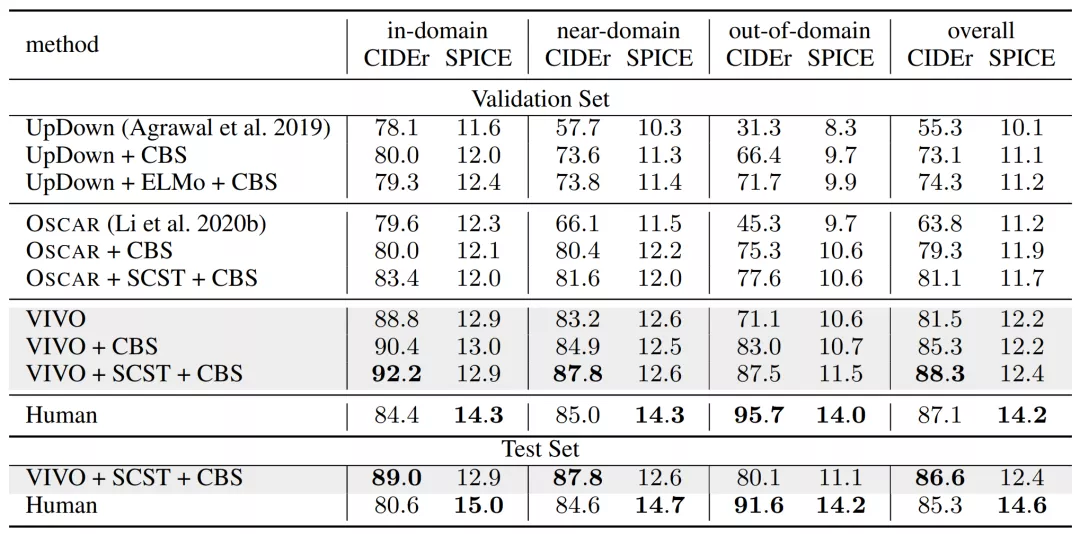
VIVO可以在没有文本标签的数据上进行文本和图像的多模态预训练,摆脱了对配对图文数据的依赖,可以直接利用ImageNet等数据集的类别标签。借助VIVO,模型可以学习到物体的视觉外表和语义之间的关系,建立视觉词表。这个视觉词表是啥呢?其实就是一个图像和文本的联合特征空间,在这个特征空间中,语义相近的词会聚类到一起,如金毛和牧羊犬,手风琴和乐器等。预训练建好词表后,模型只需在有少量共同物体的配对图文的数据上进行微调,模型就能自动生成通用的模板语句,使用时,即使出现没见过的词,也能从容应对,相当于把图片和描述的各部分解耦了。所以VIVO既能利用预训练强大的物体识别能力,也能够利用模板的通用性,从而应对新出现的物体。Azure AI 认知服务首席技术官黄学东解释说,视觉词表的预训练类似于让孩子们先用一本图画书来阅读,这本图画书将单个单词与图像联系起来,比如一个苹果的图片下面有个单词apple,一只猫的图片下面有个单词cat。视觉词表的预训练本质上就是训练系统完成这种动作记忆。目前,VIVO 在 nocaps 挑战中取得了 SOTA效果,并首次超越人类表现。VIVO取得成功可不仅仅是挑战赛的SOTA,目前已经有了实际应用。
看图说话SOTA已上线,AI不能一直处于灰色的迭代据世界卫生组织统计,各年龄段视力受损的人数估计有2.85亿人,其中3900万人是盲人。实力受损的用户想要获取图片和视频中的信息,就要依靠自动生成的图片描述或字幕(或者进一步转化为语音),他们非常相信这些自动生成的描述,不管字幕是否有意义。「理想情况下,每个人都应该在文档、网络、社交媒体中给图片添加描述,因为这样可以让盲人访问内容并参与对话。」但是,这很不现实,很多图片都没有对应的文本。Azure AI 认知服务公司首席技术官黄学东说: 「看图说话是计算机视觉的核心能力之一,可以提供广泛的服务」。现在VIVO看图说话的能力已经集成到了Azure AI中,任何人都可以将它集成到自己的视觉AI应用中。黄学东认为, 把VIVO的突破带到 Azure 上,为更广泛的客户群服务,不仅是研究上的突破,更重要的是将这一突破转化为 Azure 上的产品所花费的时间。基于VIVO的小程序Seeing AI在苹果应用商店已经可以使用了,Azure也已经上线了免费API,供盲人或者视障人士免费使用。如果再加上Azure的翻译服务,看图说话可以支持80多种语言。的确,有太多的实验室SOTA技术倒在了灰色的不断迭代中,没能完成它最初的使命。
看图说话只是认知智能的一小步,受古登堡印刷机启发开创新魔法
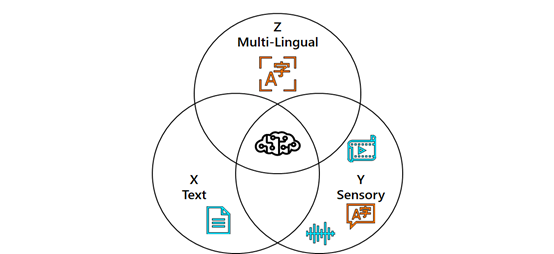
作为 Azure 认知服务的首席技术官,黄学东所在的团队一直在探索,如何更全面、更人性化地来学习和理解这个世界。他认为要想获得更好的认知能力,三个要素至关重要,单语言文本(X)、音频或视觉等感觉信号(Y)和多语言(Z)。在这三者的交汇处,有一种新魔法ーー XYZ-Code,可以创造出更强大的人工智能,能够更好地听、说、看和理解人类。「我们相信 XYZ-Code正在实现我们的长期愿景: 跨领域、跨模式和跨语言学习。我们的目标是建立预先训练好的模型,这些模型可以学习大范围的下游人工智能任务的表示,就像今天人类所做的那样。」黄学东团队从德国发明家约翰内斯·古登堡那里获得灵感,他在1440年发明了印刷机,使人类能够快速、大量地分享知识。作为历史上最重要的发明之一,古登堡的印刷机彻底改变了社会进化的方式。在今天的数字时代,认知智能的愿景也是开发一种能够像人一样学习和推理的技术,对各种情况和意图做出精准推断,进而做出合理的决策。在过去的五年里,我们已经在人工智能的很多领域实现了人类的平等地位,包括语音识别对话、机器翻译、问答对话、机器阅读理解和看图说话。这五个突破让我们更有信心实现人工智能的飞跃,XYZ-Code将成为多感官和多语言学习的重要组成部分,最终让人工智能更像人类。正如古登堡的印刷机革命性地改变了通信的过程,认知智能将帮助我们实现人工智能的伟大复兴。https://apps.apple.com/us/app/seeing-ai/id999062298


点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报