
多任务学习中的网络架构和梯度归一化

来源:DeepHub IMBA 本文约2600字,建议阅读5分钟
本文介绍了多任务学习中的网络架构与梯队归一化。
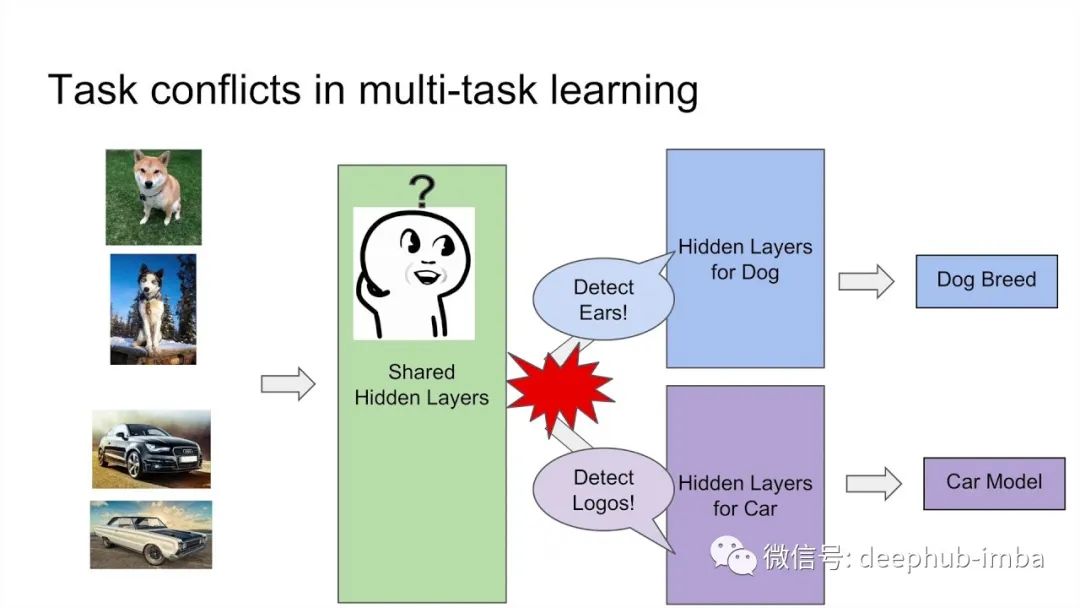
多任务学习中的优化
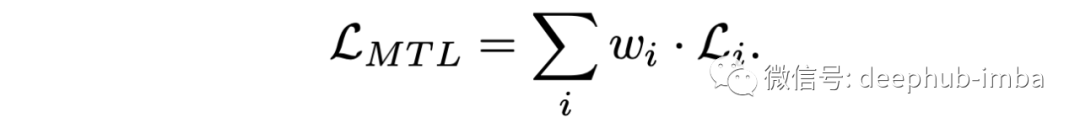
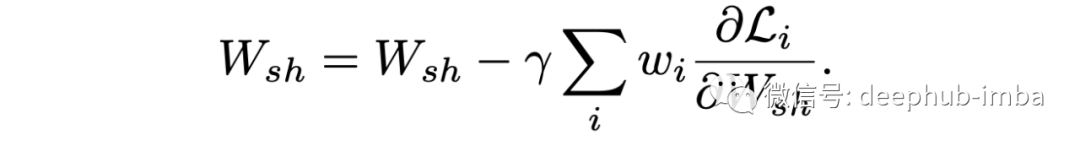


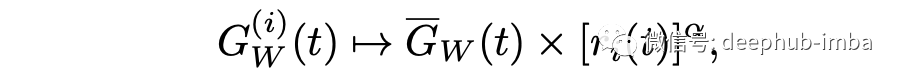
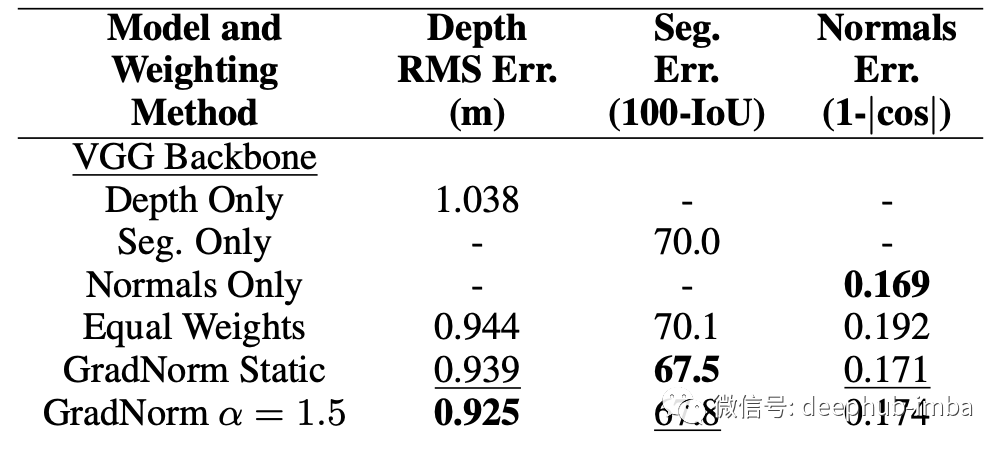
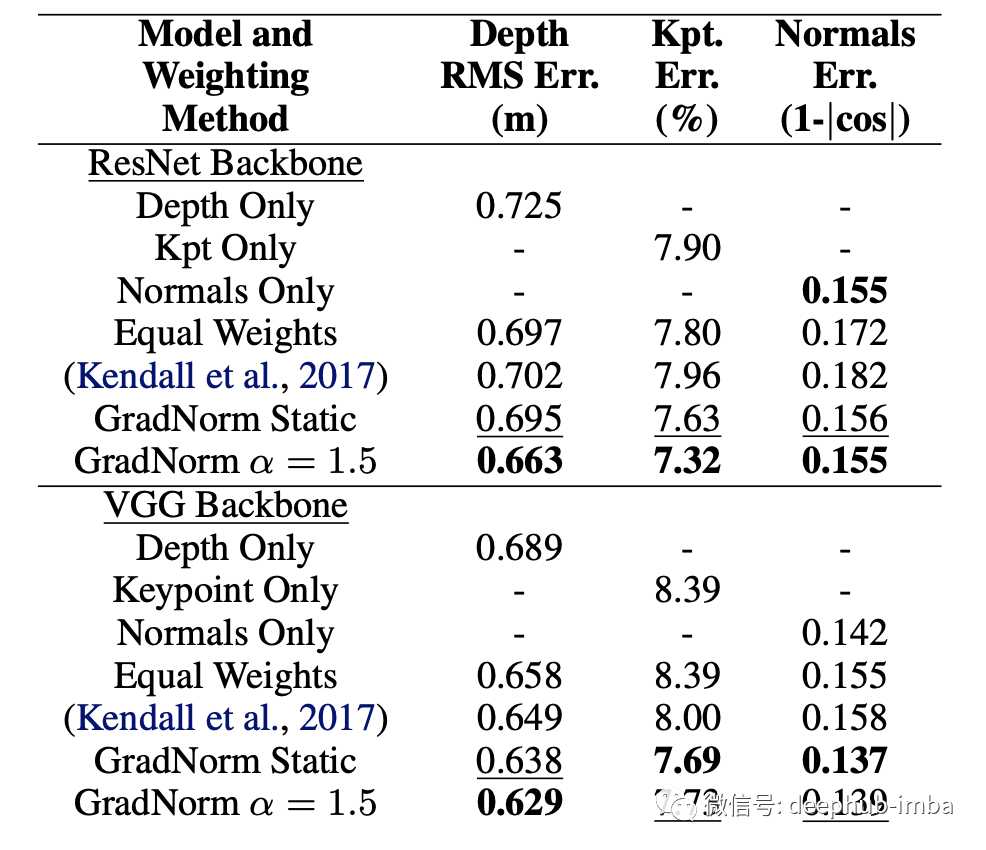
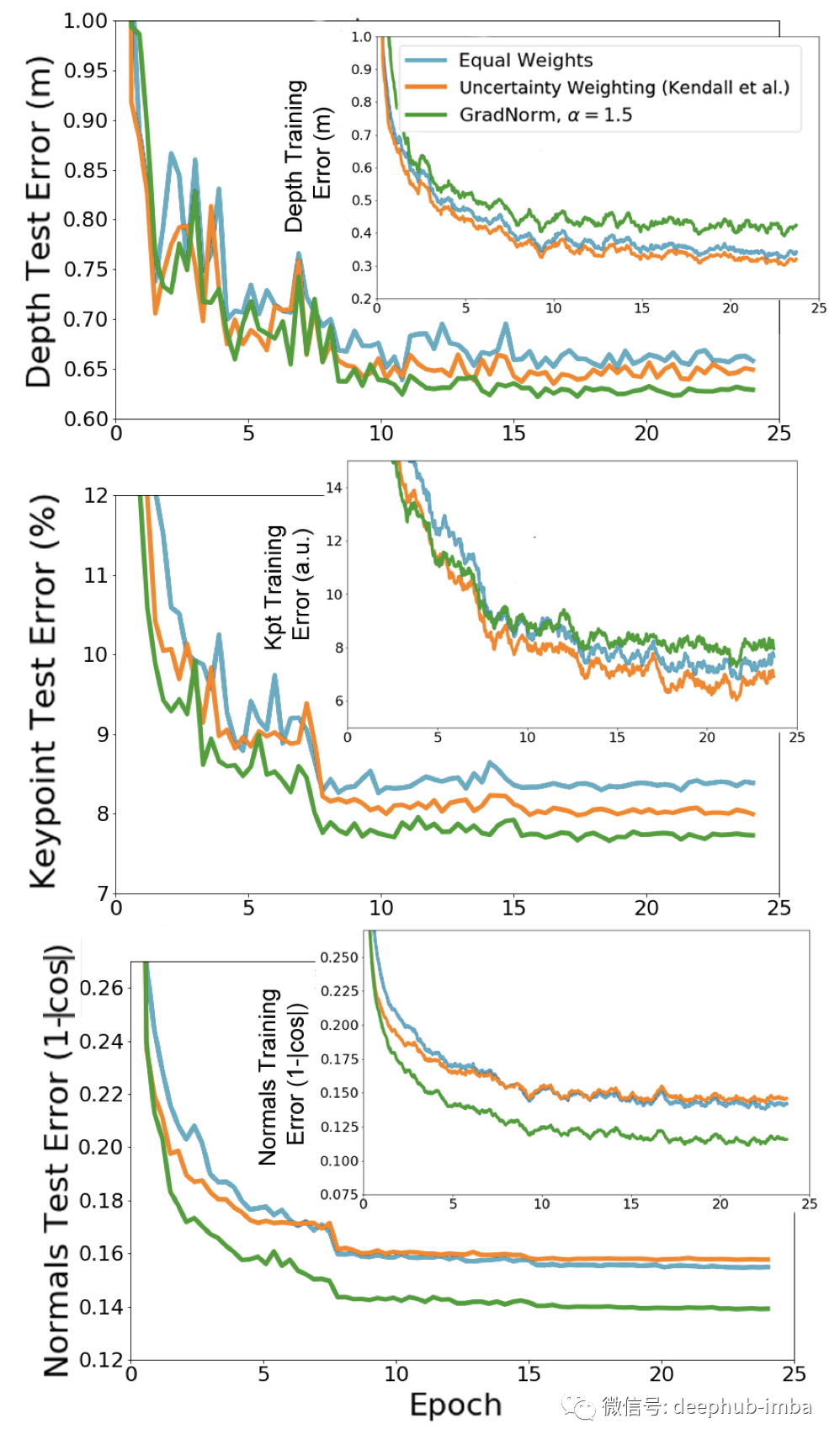
深度多任务学习架构
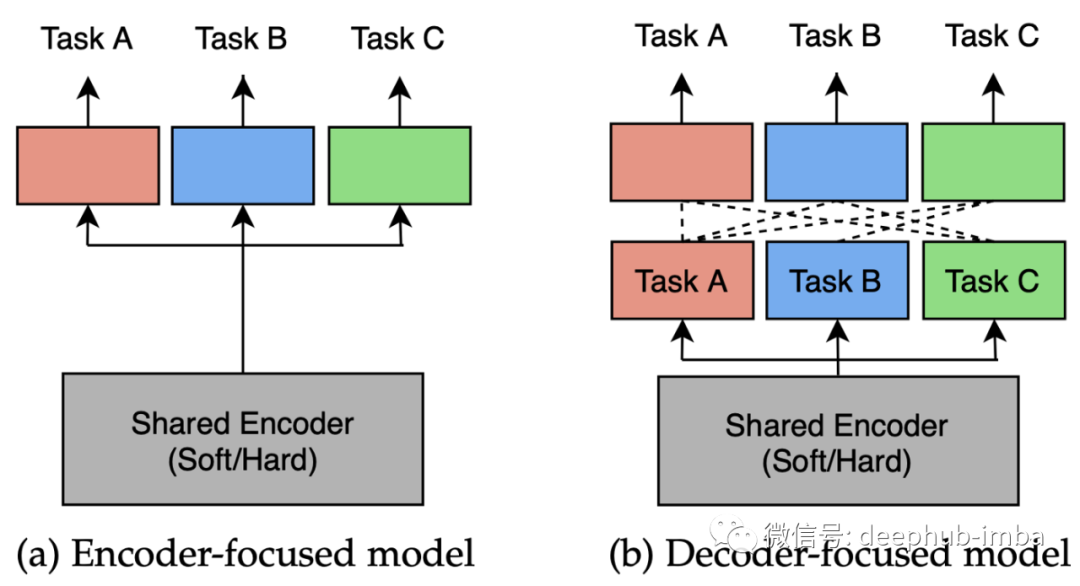
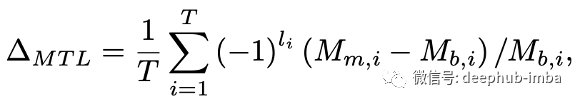
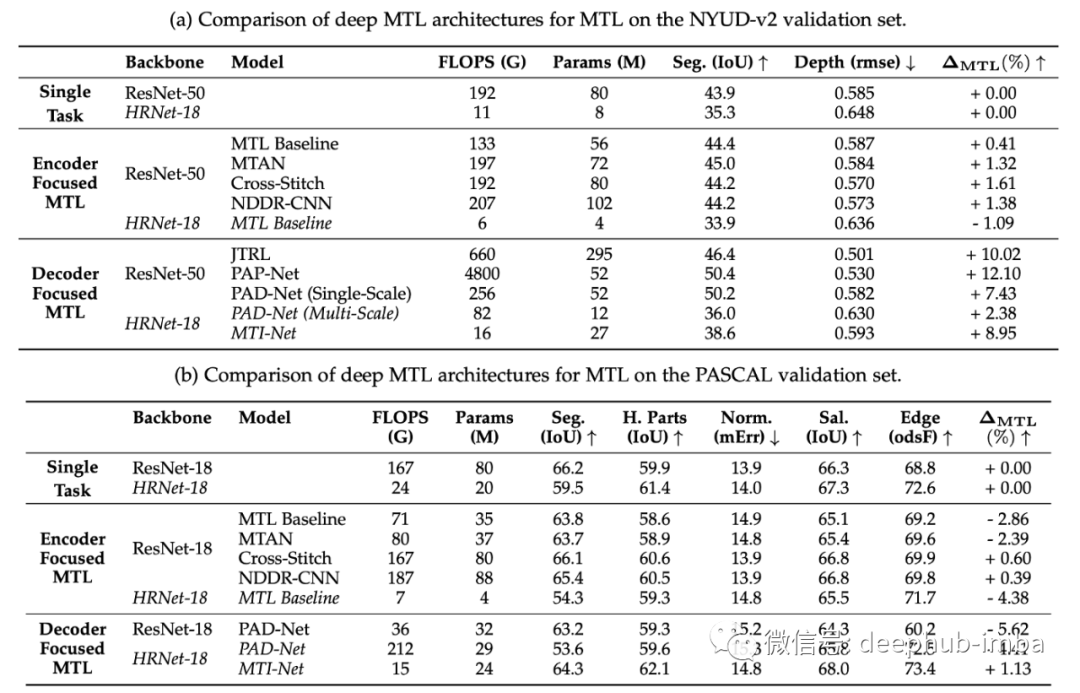
深入研究
引用
[1] GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks, arxiv 1711.02257
[2] Multi-Task Learning for Dense Prediction Tasks: A Survey, arxiv 2004.13379
编辑:王菁
校对:杨学俊
评论