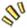如何实现用户行为的动态采集与分析

本文首发于政采云前端团队博客:如何实现用户行为的动态采集与分析
https://www.zoo.team/article/user-data-analysis

开场介绍

哈喽,大家好,我是清音,来自政采云前端团队。从去年开始负责用户行为采集与分析体系的建设。很高兴有机会能在这里给大家分享我们从 0-1 建设用户采集与分析系统的经验。
建设价值

数据埋点的业务价值



我们将这个用户行为采集与分析的系统取名为为浑仪,数据采集服务上线一年半,目前浑仪平台的日志数量已经达到了 16 亿,每个工作日收集的数量大约在 1000 万左右,前端内部建立了虚线的兴趣小组,从采集需求,设计方案到落地,总的人力成本是在 90 人天左右。

后面我会分四个部分去介绍浑仪系统,首先是关键架构的总体介绍,然后分成数据采集、分析和应用三个模块详细介绍。
关键结构

浑仪系统总体流程可以归纳为三大步。首先,收集数据,然后进行数据处理,最后,数据透出展示。
而支撑这三大部门,实现了 4 个功能模块:
数据采集的 SDK 数据处理和数据存储的服务 进行坑位级数据展示的 Chrome 插件 系统级数据展示的站点
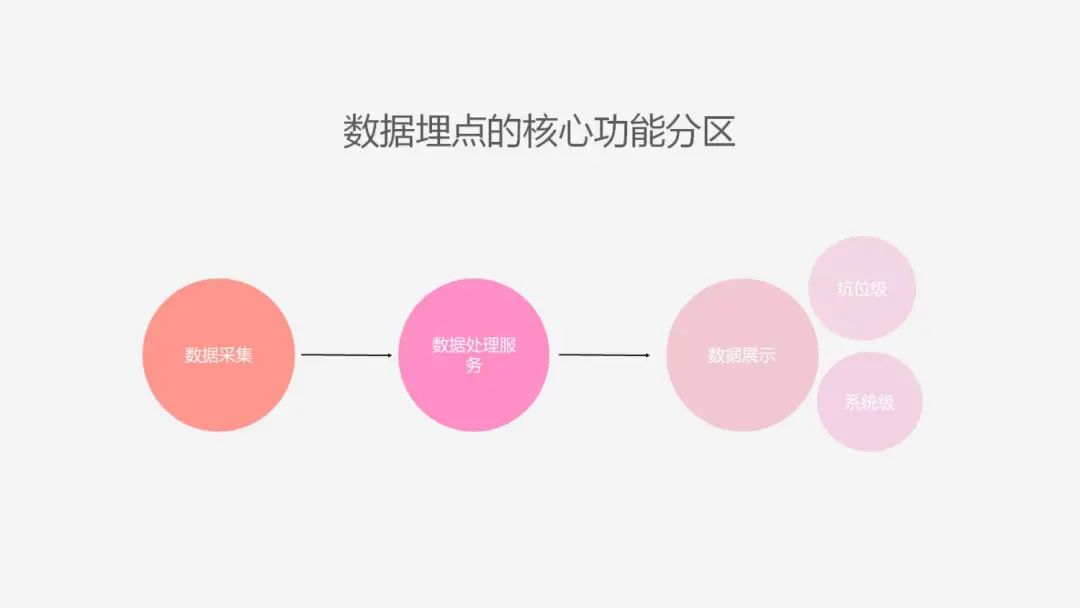
浑仪的总体架构图
总体架构预览
首先来看下浑仪的总体架构图,我们收集了三端的数据,PC、H5 和 APP。
在 PC 端和 H5 使用了两套 sdk 去监听不同的事件。然后将监听到的事件通过 rest 接口上报给数据处理的服务,存储至阿里云日志服务中。我们进行了测试环境和真线环境,两个环境的数据隔离。测试环境的 sdk 会走协商缓存的形式去刷新,真线会使用强缓存,并且进行版本控制;由于真线数据量庞大,我们会定期将日志库一年半以上的历史数据数据存储至 OSS。每天会有定时任务,筛选一部分数据存储到数据库中。另外还会和外部的很多系统进行交互。
权限系统:主要控制浑仪站点的访问权限; 性能系统:输出一些高频访问页面,进行性能检测; 运维平台,用来部署系统;和大数据平台会做一些数据的交互,我们会将行为数据推给大数据平台,也会从平台上捞取一些业务相关的数据。
系统关键架构
从上图重点模块的详细架构图可以看到。左边这一个模块,是面向用户进行行为采集的,右边模块是面向内部用户;提供给用户非常丰富的数据可视化展示。除了有可视化的站点,还提供了 Chrome 的插件,进行数据的展示,还作为一个 pass 平台,对外提供一些 SQL 查询,报表 Excel 导出,和提供 API 拉取报表的数据,也可以基于现有的数据进行二次开发。
数据采集

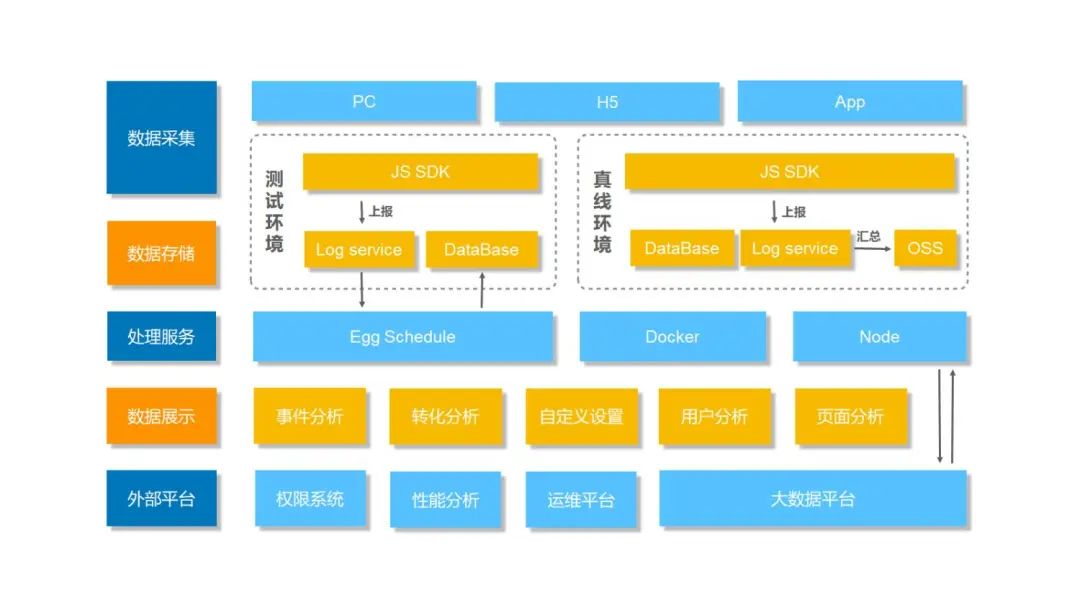
首先讲一下数据采集模块的实现。我们采集了页面进入和离开,用户点击和滚屏事件,还有一些标准的自定义事件。页面进入、离开和滚屏的事件我们能进行自动化的采集,点击以及自定义事件需要,前端同学配合,进行代码植入。
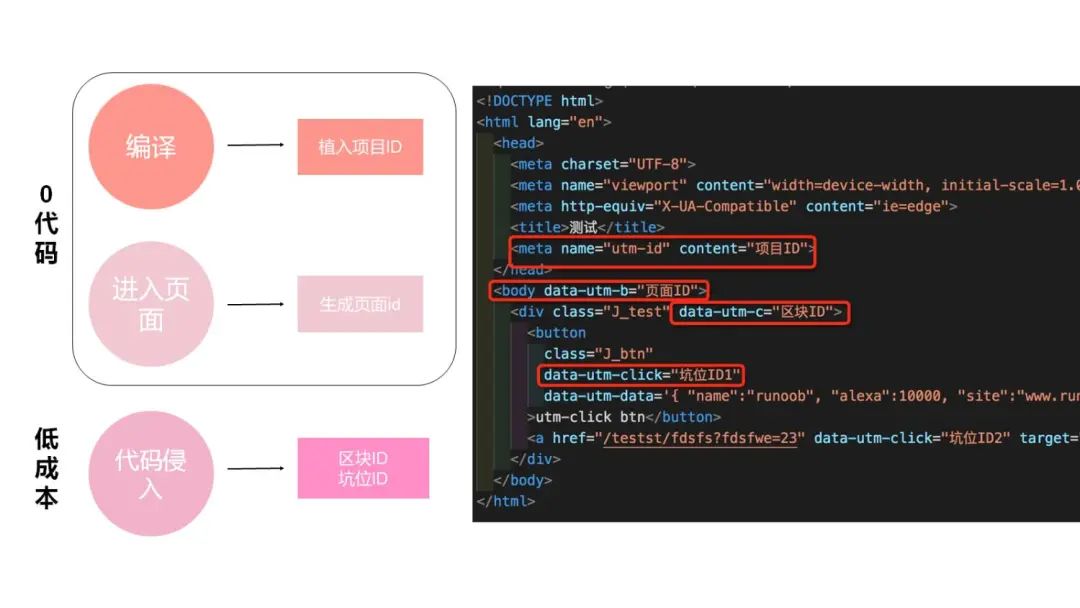
首先我们在页面当中通过项目编译过程当中,为项目植入了项目 ID,挂载页面的 head 部分
然后在进入页面的时候,根据页面的路径,去自动生成页面 ID,挂载在 body 节点上 最后在用户进入页面和离开页面的时候,数据采集的 SDK 能自动拿到项目 ID,页面 ID,去定位一个唯一的页面,做到自动化的上报进入和离开的事件
以点击事件为例,当前触发点击事件的 DOM 点,我们称之为坑位。坑位的外层包裹的 DOM 节点我们称之为区块。这两者需要以代码侵入的方式,进行挂载,为了降低挂载的成本,我们也提供了一些工具去帮助他们进行操作。
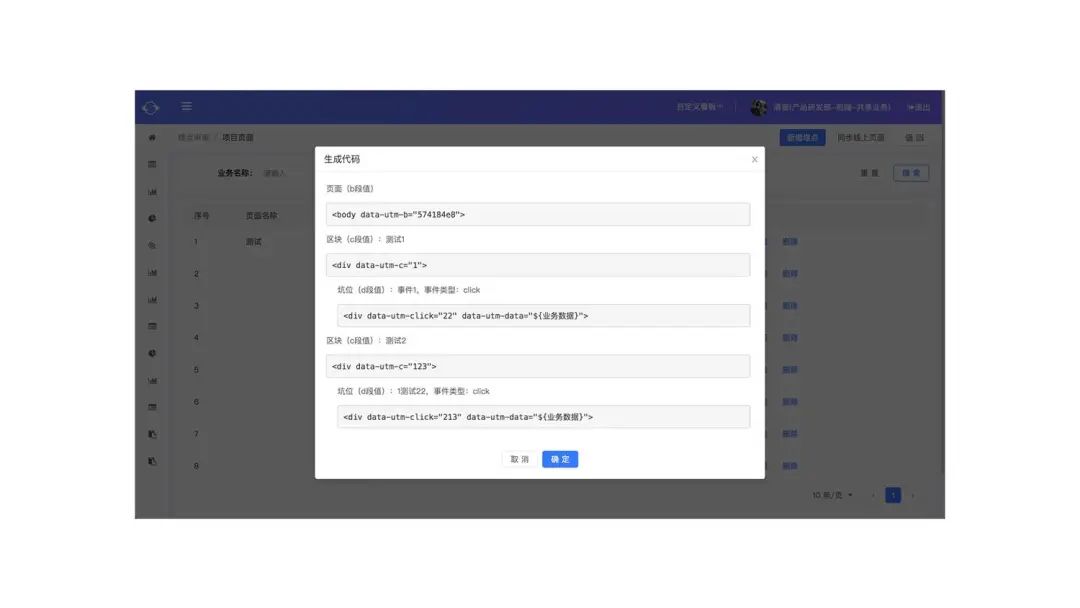
统一的站点中我们提供了埋点申请的功能,在申请完成之后点击生成代码,但马上会详细列出需要挂载的位置以及 ID,开发人员只需要将生成的代码粘贴到需要埋点的位置即可。
另外上一场我们讲到了搭建,通过搭建系统生成的页面也会自动植入这些位置 ID,有了这些数据之后,我们就可以开始进行一次完整的上报。
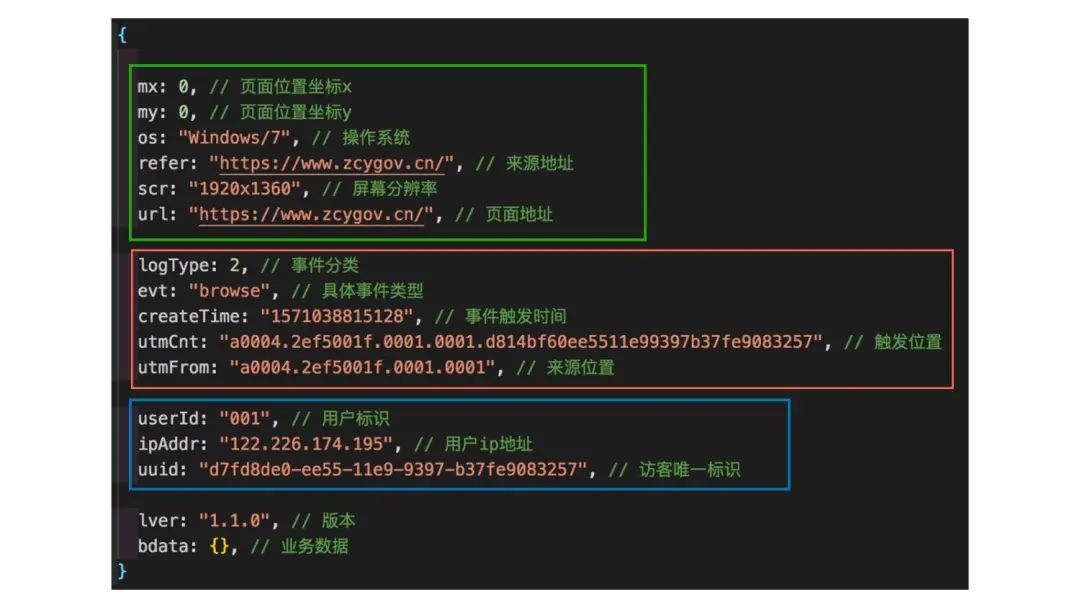
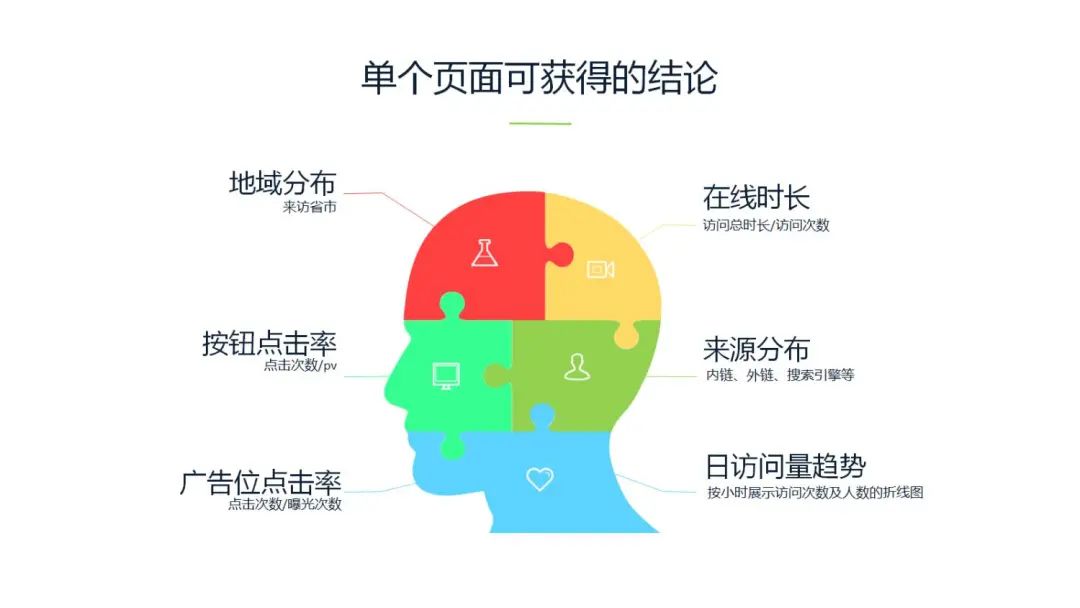
操作系统、分辨率、浏览器这些信息可以让我们分析当前平台主流用户的一些主流浏览器,用来确定平台的兼容情况
如果是 APP 端还会有例如是客户端版本,手机型号,当前网络情况的一些其他的数据 logType 对事件进行分类 evt 去具体的指定事件类型 createTime 是事件发生时间,可以用来串联事件发生的前后顺序记录了 utmCnt 是触发位置用来把当前的事件定位到具体的 dom 节点 uuid 是访客的唯一标识,每次用户进入页面之后,SDK 会去 cookie 中查找它,如果没有的话,我们就会生成,并且将过期时间设为永久。记录用户的 IP 地址可以追溯到用户的省市区 userId 可以和 uuid 关联起来,将无意义的访客,关联到平台的用户,形成详细的用户画像 utmfrom 标记了来源的位置,后面会详细讲 a 链接的跳转,这个字段是用来串联前后的链路 绿色框内的上报信息,我们可以归结为浏览器页面相关的一些信息,红色框内的是事件相关的一些信息,蓝色框内的信息,我们可以归结为用户相关的信息
具体事件拦截
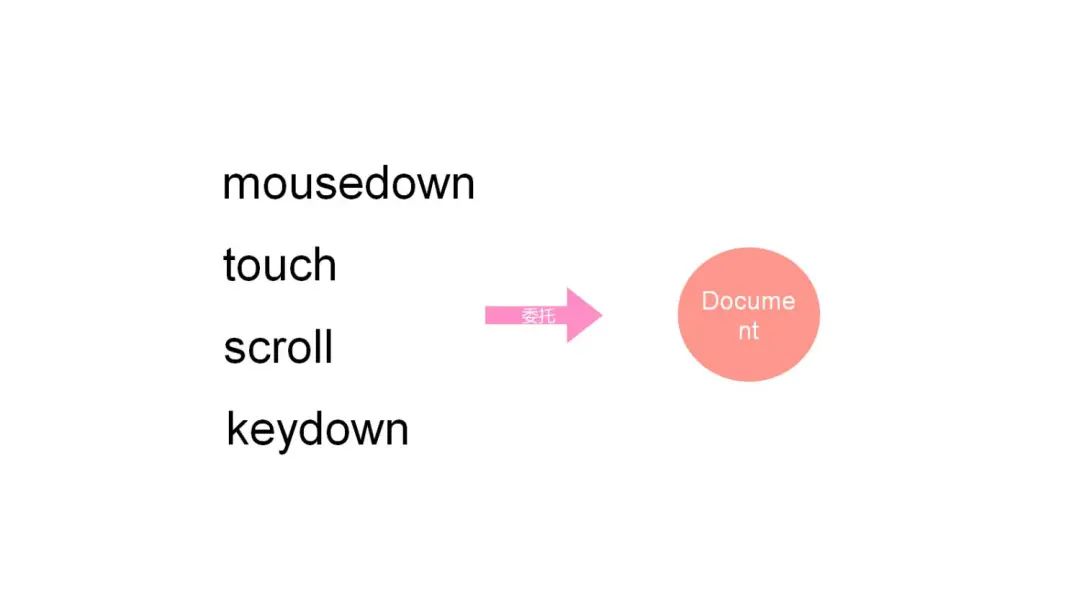 我们将四个目标事件都委托在了 document 上,所有这些事件只要触发都会被拦截,但是经过特定的筛选,只有能获取到坑位 ID 和区块 ID 的 target 上触发的事件才会被上报。这让我们收集的数据更加精准,如果在这里不做筛选的话,上报的数据变得大而全,数据量就会特别庞大,就把目前的代码侵入式埋点切换为了全埋点,这也会让数据的分析变得比较困难。
我们将四个目标事件都委托在了 document 上,所有这些事件只要触发都会被拦截,但是经过特定的筛选,只有能获取到坑位 ID 和区块 ID 的 target 上触发的事件才会被上报。这让我们收集的数据更加精准,如果在这里不做筛选的话,上报的数据变得大而全,数据量就会特别庞大,就把目前的代码侵入式埋点切换为了全埋点,这也会让数据的分析变得比较困难。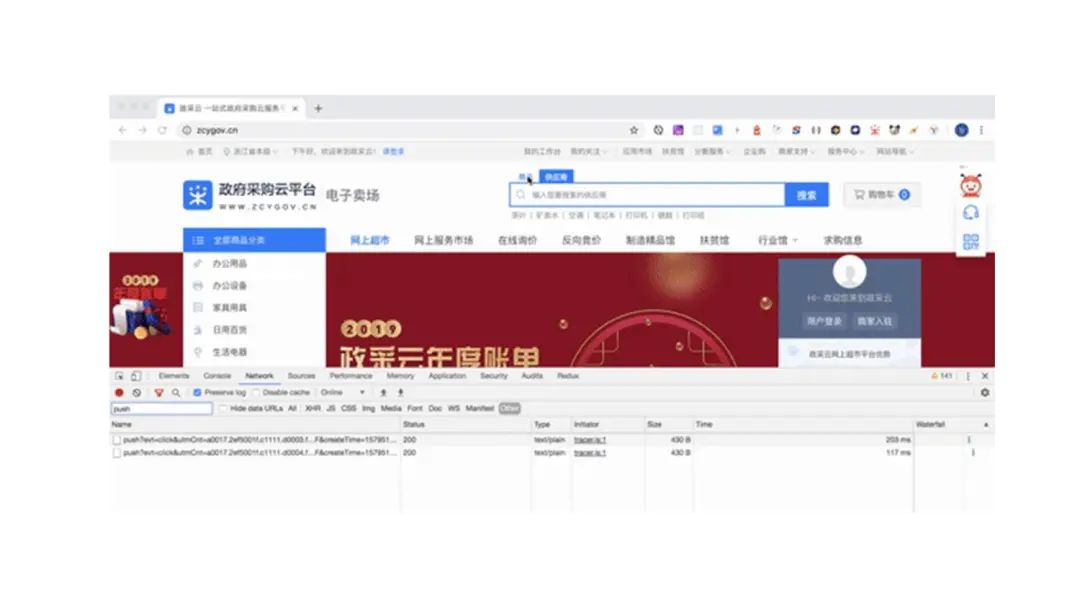 从上图可以看见,刚进入页面的时候,默认会有一个 push 请求发送。每次点击的时候也会有一个 push 请求发出去,但是它的归类都是是在 other 里面。
从上图可以看见,刚进入页面的时候,默认会有一个 push 请求发送。每次点击的时候也会有一个 push 请求发出去,但是它的归类都是是在 other 里面。这是因为离开的过程当中,发送 HTTP 请求通常都会被 cancel,而我们使用 sendBeacon 就是一种用来保证数据被发送的方法,他能在 unload 的或者 beforeunload 的事件处理器中发起一个 HTTP request 来发送数据,这样就能确保我们离开页面的请求会被记录下来。
 在数据上报这里我们还使用
在数据上报这里我们还使用 ** 标签主要是为了保证浏览器的兼容性。因为目前,IE 是不支持 sendBeacon 方法的,而我们平台还有一部分用户还在使用 IE,我们也在持续的关注 IE 的使用比例,所以这部分的数据也会很重要。为了能收集到更多 IE 的使用数据,我们会先判断 sendBeacon 方法是否可用,不可使用的时候,会使用 ** 进行,请求的发送。而 cors 是我们最常见的一种跨域请求发送的方式,它能够使用 post 的请求,让我们批量上报的一些数据能够不超出长度的限制,能够成功发送。同样能够发送单一维度的一些上报数据之外,我们还需要,上报的数据能够串联起整个用户浏览的流程。当中最常见的一种方式就是链接的跳转。
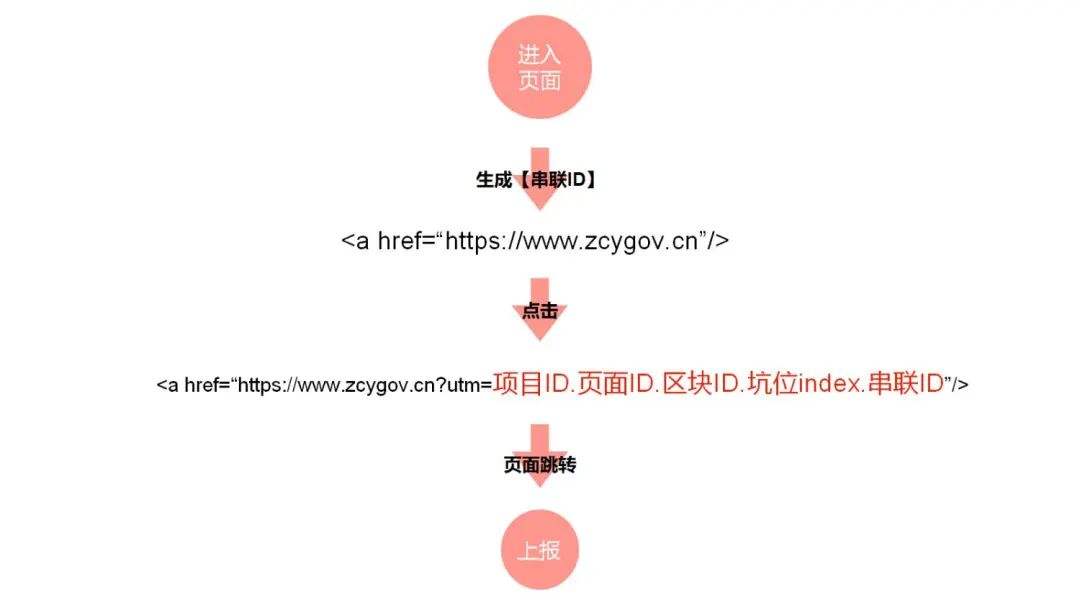
可能就有人会问为什么不用 refer 去串联整个流程呢?主要还是因为他的维度太粗了。他只能进入来源页面而不能记录,来源于页面上哪个位置。
当我们进入页面的时候,我们会生成当次进入页面的唯一标识 ID 到用户点击一个链接的时候,我们会将当前的项目 LED 页面 ID 区块 ID 和当前 a 链接的坑位下标 最后是,生成页面时生成的 ID 5 个标记 id 拼成一个 uTM 值,在页面跳转之后,SDK 会从页面的 URL 上面获取,uTM 值进行上报
这样我们就能确认,当前页面的来源是来源于上一个页面的哪一个位置的链接点击,也让链接的点击行为变成一个自动化采集的事件,只要当前区块被植入了区块 ID,它下面的所有 a 链接点击都会被记录下来,用于串联整个流程。
数据分析

在数据处理部分我们使用了阿里云的 LOG Service,他的一个非常大的好处就是能提供日志的实时消费接口,查询手段也非常丰富;能够添加实时索引;目前可以满足我们大部分的查询需求。
 在数据分析的过程当中,非常重要的一个点怎么样让我们采集到的数据转化为可理解的指标。
在数据分析的过程当中,非常重要的一个点怎么样让我们采集到的数据转化为可理解的指标。 上图我们的一个主要流程,要进行数据的分析,首先要先搭建指标,然后能获取到需要分析的点的数据之后,再进行数据分析,最后将数据应用到实际的场景中。
上图我们的一个主要流程,要进行数据的分析,首先要先搭建指标,然后能获取到需要分析的点的数据之后,再进行数据分析,最后将数据应用到实际的场景中。根据之前采集到的数据,我们很容易就能计算出页面的 PV、UV、点击数、曝光数一些基础的指标,但是我们要怎么把它转换成一个漏斗模型?
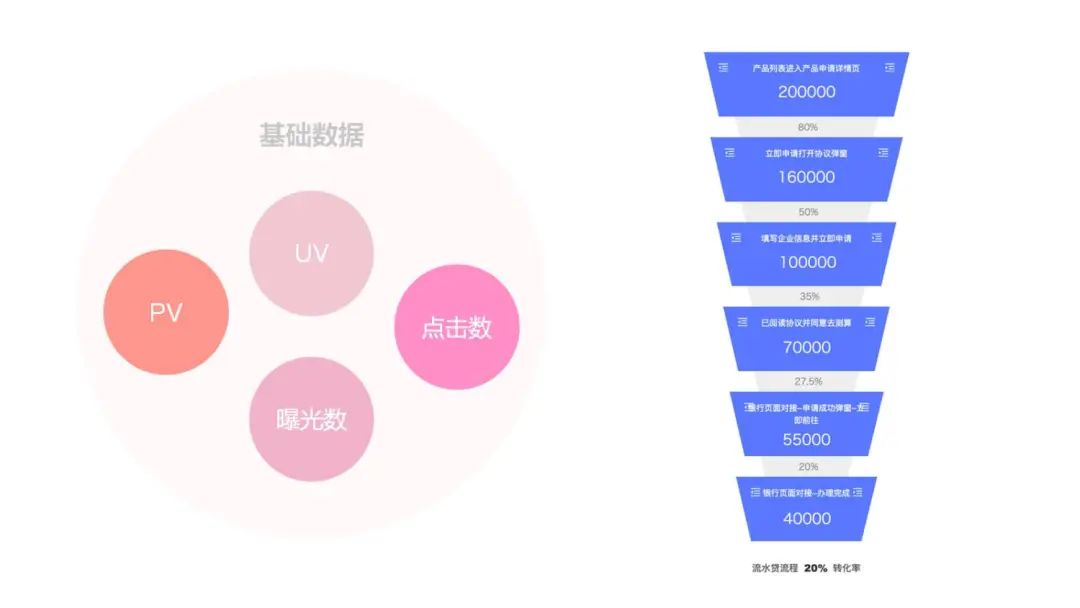
那就是去拼接这些基础数据。以我们平台的流水贷流程举例:
进入申请详情页之后,我们可以将进入页面的 UV 作为第 1 个数据 将点击立即申请打开协议弹窗,点击人数作为第二个数据,以此类推,就成组装成一个漏斗模型 我们可以计算出每个步骤相对于前一步的数量百分比,这就是一个无序的漏斗 假设部分用户可能从第三步直接进入,这时候就可能存在百分比超过 100% 的情况 如果是有序漏斗,会以用户为维度进行筛选,我们会从前到后过滤每一步的用户就表示,我们只会保留从第 1 部,按照顺序进入到最后一步的那些用户,并不把从中间进入的一些用户计算在内。这样就使得转化百分比必定小于等于 100%,也让数据更具有参考价值
下面是一个设置置信区间的场景:
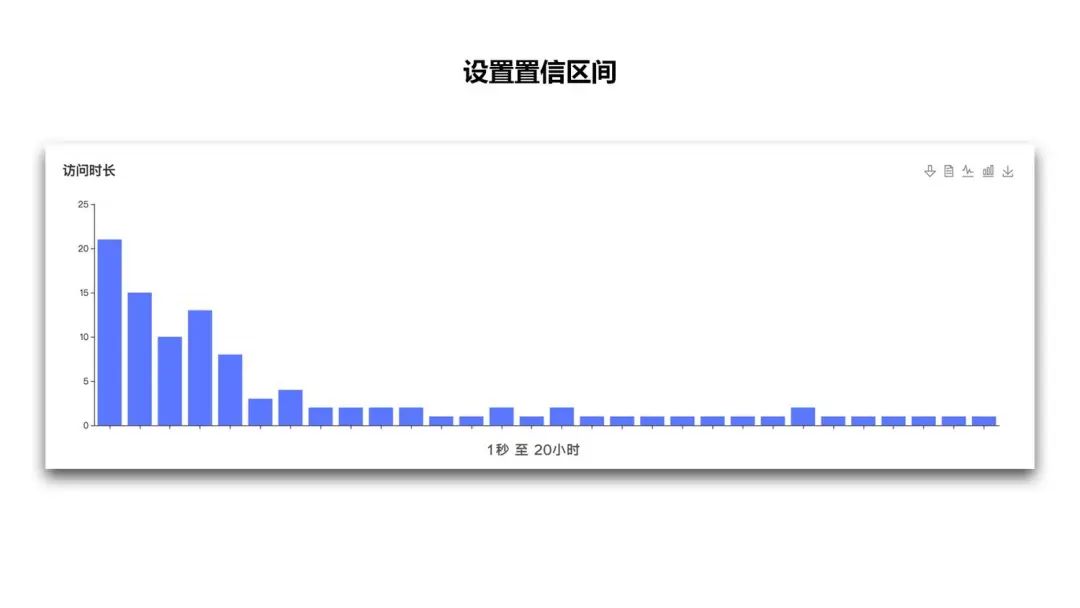
页面停留时长其实就是页面进入和页面离开的时间差,最快的情况下用户 1s 就离开了页面
但是也有可能用户在中间中断了操作但一直没有关闭窗口,导致停留时间非常的长 在样本比较少的情况下这样特殊的数据可能会拉升了页面的平均访问时长,使得平均时长超过了 4 个小时,这时候平均访问时长可能失去了参考价值 这里的中位数指的是将用户访问时长从小到大排序之后,取中间的数值,得到了 22 分 8 秒,这时候,中位数更能反映页面实际的使用情况
那么怎么才能让平均时长,具有价值呢?
我们可以设置置信区间,根据页面具体情况排除页面使用时长大于 5 小时或 8 小时的用户,然后再来看整个页面的平均访问时长,或者是借助柱状图,查看时长的总体分布和趋势。
数据应用

当前分析模型主要分为事件分析,页面分析,转化分析和用户分析四大块,内部还分成了 10 几种小的指标;还在自定义设置中提供了帮助指标建立的工具;
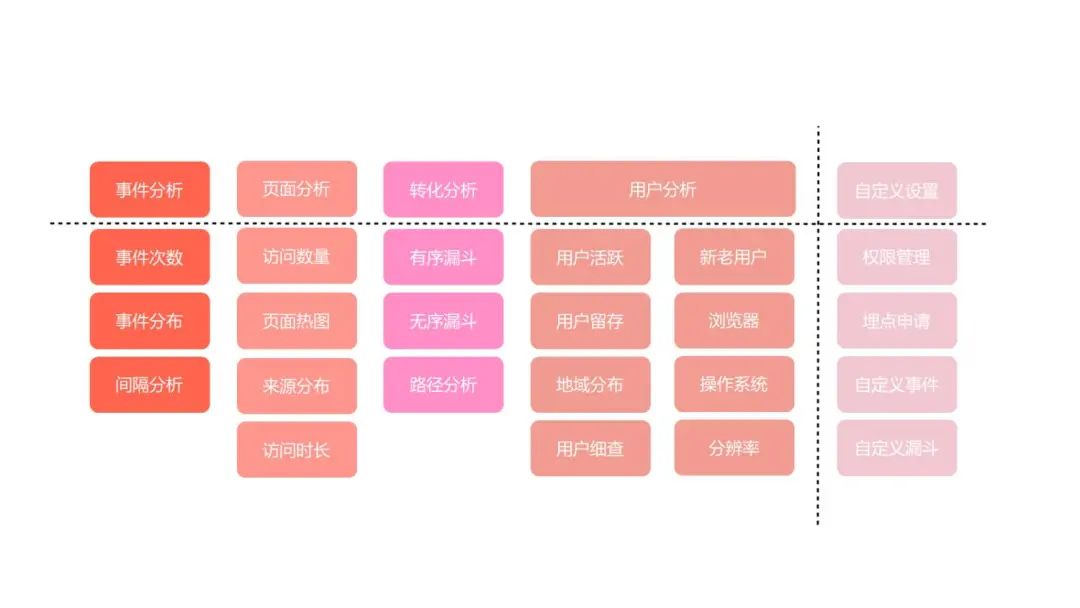
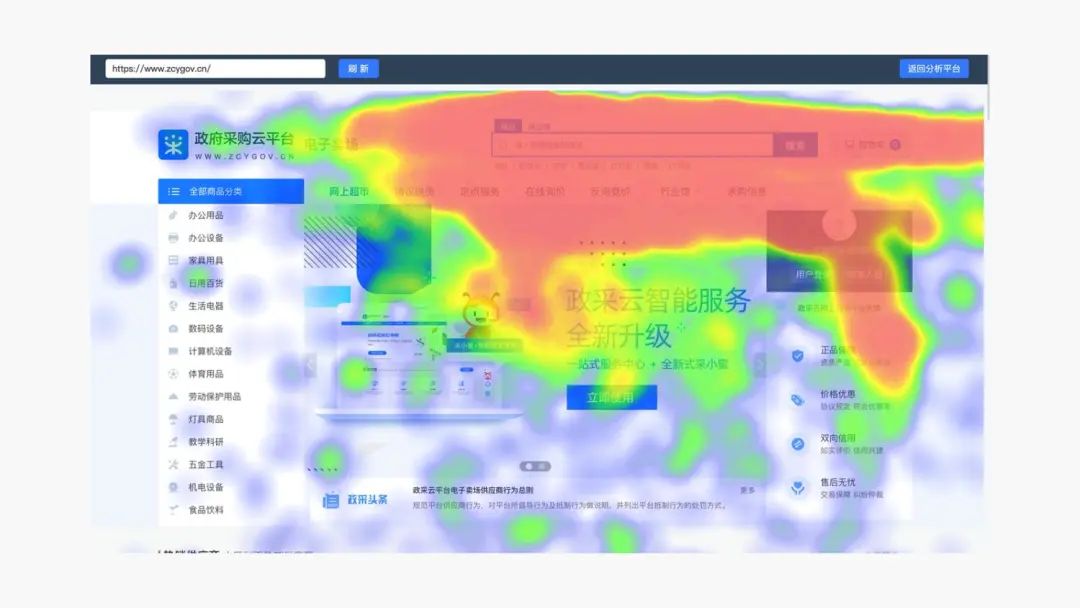
事件分析是用户行为分析的基础也是最常用的功能,次数、分布、间隔,通过事件分析可以创建各种分析报表。页面基于各个页面的行为数据,针对性的优化着陆页的页面布局,增加着陆页的访问吸引力。热力图分析,通过将用户行为进行可视化展示,帮助我们深入分析用户对内容及功能的注意力
转化分析是用户行为分析中最重要的分析模型,通过转化分析可以找出用户行为的转化路径和漏斗,提升平台的整体转化率。从触达用户到用户完成转化的整个过程中都存在转化率
用户分析能够很好的帮助我们确定产品的目标用户群,用户的行为习惯,掌握用户的活跃和留存特征,通过用户分群可以实现精细化的用户运营
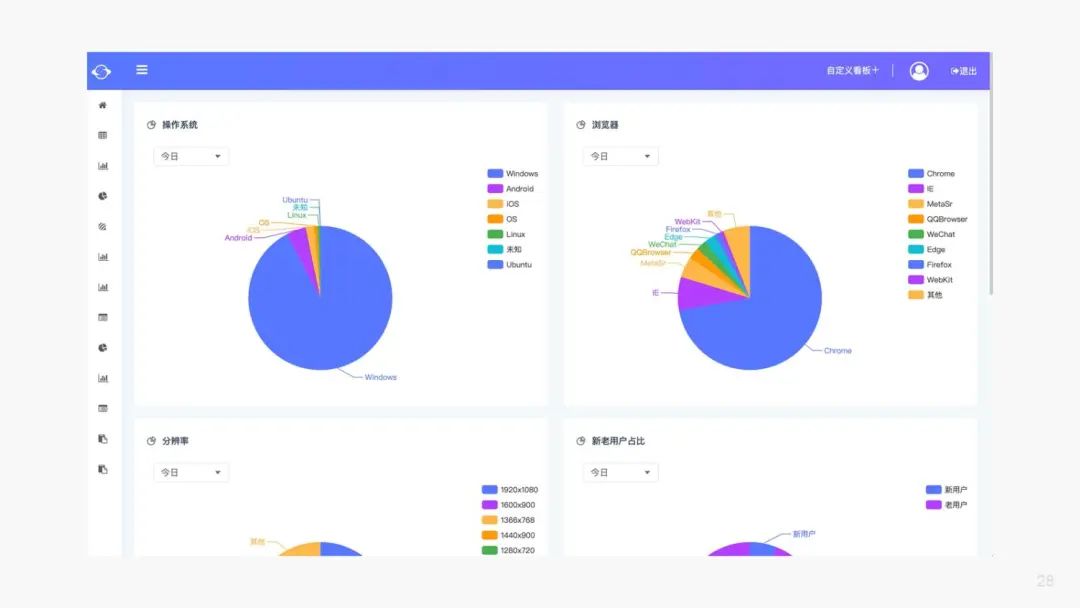
这是一个数据看板,实时查看自定义的核心指标和报表,对关键指标做实时掌握,帮助用户实时发现问题。
操作系统,浏览器占比,可以点击细查:
访问次数、访问人数 热力图:通过坐标,分辨率换算,得到热图 路径分析:可以看到来源和去向 这里是自定义设置的功能:用于创建事件和漏斗
其他

浑仪算是一个比较基础的数据采集分析的产品,后面还有很多可扩展的点。


最后
欢迎加我微信(winty230),拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个专业的技术人...