
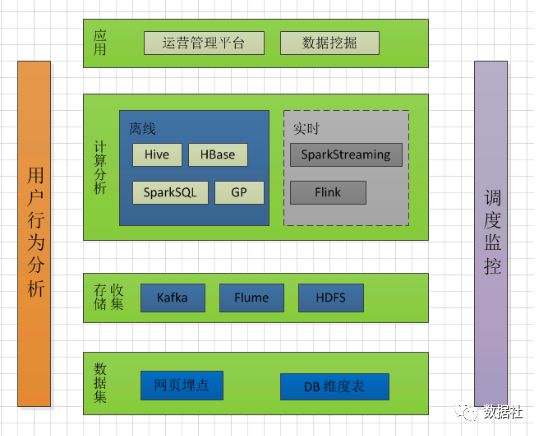
用户行为分析之数据采集
用户行为分析主要关心的指标可以概括如下:哪个用户在什么时候做了什么操作在哪里做了什么操作,为什么要做这些操作,通过什么方式,用了多长时间等问题,总结出来就是WHO,WHEN,WHERE,WHAT,WHY以及HOW,HOW TIME。
根据以上5个W和2H,我们来讨论下们如何实现。
WHO,首先需要x获取登陆用户个人的信息。用户名称,角色等
WHEN,获取用户访问页面每个模块的时间,开始时间,结束时间等
WHAT,获取用户登陆页面后都做了什么操作,点击了哪些页面以及模块等
WHY,分析用户点击这些模块的目的是什么
HOW,用户通过什么方式访问的系统,web,APP,小程序等
HOW TIME,用户访问每个模块,浏览某个页面多长时间等
以上都是我们要获取的数据,获取到相关数据我们才能接着分析用户的行为。
用户行为数据采集
埋点
埋点一般分为无埋点和代码埋点。这两种各有优缺点,这里只做一个简单的介绍:
全埋点是前端的一种埋点方式, 在产品中嵌入SDK,最统一的埋点,通过界面配置的方式对关键的行为进行定义,完成埋点采集,这种是前端埋点方式之一。
优势:
可视化展示宏观指标,满足基础分析需求,如PV,UV,每个控件的点击联系
使用和部署较简单,只需要嵌入SDK,避免了很多因为需求变更,埋点错误等导致需要重新埋点(这个深有体会)
用户友好性强,触发埋点之后自动向服务器发送数据,避免人为失误
劣势:
作为前端埋点会存在一些天然的劣势
只能采集用户交互数据,对于一些关键行为还是需要代码埋点
兼容性问题
数据采集不全面,传输问题,时效性,数据可靠性
代码埋点,这个也是目前我们使用的埋点方式,代码埋点分为前端代码埋点和后端代码埋点,前端埋点类似于全埋点,也需要嵌入SDK,不同的是对于每个事件行为都需要调用SDK代码,传入必要的事件名,属性参数等等,然后发到后台数据服务器。后端埋点则将事件、属性通过后端模块调用SDK接口方式发送到后台服务器。
我们采用的是代码埋点,分为前后端。埋点是一个特别重要的过程,它是数据的源头,如果数据源头出现问题,那么数据本身就存在问题,分析结果也就丧失了意义。
由于我负责日志检测,也就是埋点后的事件日志的检测告警,并通知对应的埋点开发人员,运营方,产品方,所以也就遇到了过其中存在的很多坑,大部分是流程方面的。
事件属性是有一套元数据管理系统,业内的一些服务也是这种结构。一般是先定义事件、属性,后埋点的方式,原因是事件日志数据是需要经过检查的,需要检查事件是否存在,属性是否缺失,数据是否正常等等。
遇到的坑:
运营产品未定义,开发便已经埋点上线
运营产品和埋点开发的需求文档有问题或者沟通问题或开发未按照规范
导致事件对不上,属性字段对不上,缺失或格式存在问题
开发埋点漏埋点,埋点不全,或者埋点逻辑有问题出现重复埋点,出现重复数据
属性数据对不上
元数据定义,运营人员的理解和给开发的需求以及开发的理解可能不对应,但最终检测逻辑只会按照定义的情况判断
数据不对,这种情况很难检测出来,需要运营产品在分析中发现,这也是就难受的一点
有了上面的思路,下面我们来说下实现的相关技术问题,如何落地用户行为分析。
数据采集
根据运营定义好的埋点接口形式获取到的用户的访问日志数据,一定要提前后端和前端定义好数据的保存格式,也就是保存哪些字段内容,需要把埋点数据按照约定的格式统一封装,以便于存储分析。
下面该数据采集神器Flume出场了。
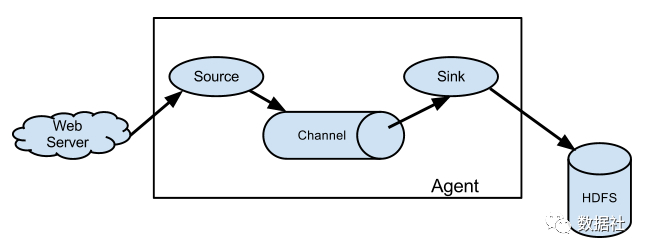
source 可以接收外部源发送过来的数据。不同的 source,可以接受不同的数据格式。比如有目录池(spooling directory)数据源,可以监控指定文件夹中的新文件变化,如果目录中有文件产生,就会立刻读取其内容。
channel 是一个存储地,接收 source 的输出,直到有 sink 消费掉 channel 中的数据。channel 中的数据直到进入到下一个channel中或者进入终端才会被删除。当 sink 写入失败后,可以自动重启,不会造成数据丢失,因此很可靠。
sink 会消费 channel 中的数据,然后送给外部源或者其他 source。如数据可以写入到 HDFS 或者 HBase 中。
实时的埋点数据采集一般会与两种方法:
直接触发的日志发送到指定的HTTP端口,写入kafka,然后Flume消费kafka到HDFS
用户访问日志落磁盘,在对应的主机上部署flume agent,采集日志目录下的文件,发送到kafka,然后在云端部署flume消费kafka数据到HDFS中
那么Flume 采集系统的搭建相对简单,只需要两步:
在服务器上部署 agent 节点,修改配置文件
启动 agent 节点,将采集到的数据汇聚到指定的 HDFS 目录中
flume配置模板:
a1.sources = source1a1.sinks = k1a1.channels = c1a1.sources.source1.type = org.apache.flume.source.kafka.KafkaSourcea1.sources.source1.channels = c1a1.sources.source1.kafka.bootstrap.servers = kafka-host1:port1,kafka-host2:port2...a1.sources.source1.kafka.topics = flume-testa1.sources.source1.kafka.consumer.group.id = flume-test-group# Describe the sinka1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = /tmp/flume/test-dataa1.sinks.k1.hdfs.fileType=DataStream# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 100a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela1.sources.source1.channels = c1a1.sinks.k1.channel = c1