
基于ClickHouse的用户行为分析实践
点击上方蓝色字体,选择“设为星标”




前言
ClickHouse为用户提供了丰富的多参聚合函数(parametric aggregate function)和基于数组+Lambda表达式的高阶函数(higher-order function),将它们灵活使用可以达到魔法般的效果。在我们的体系中,ClickHouse定位点击流数仓,所以下面举几个用它来做用户行为(路径)分析的实战例子,包括:
路径匹配
智能路径检测
有序漏斗转化
用户留存
Session统计
路径匹配
CK默认提供了sequenceMatch函数检查是否有事件链满足输入的模式,sequenceCount函数则统计满足输入模式的事件链的数量。示例:
SELECT
site_id,
sequenceMatch('(?1)(?t<=15)(?2).*(?3)')(
ts_date_time,
event_type = 'shtLogon',
event_type = 'shtKkclick' AND column_type = 'homePage',
event_type = 'shtAddCart'
) AS is_match
FROM ods.analytics_access_log_all
WHERE ts_date >= '2020-07-01'
AND site_id IN (10266,10022,10339,10030)
GROUP BY site_id;
┌─site_id─┬─is_match─┐
│ 10030 │ 1 │
│ 10339 │ 1 │
│ 10266 │ 1 │
│ 10022 │ 1 │
└─────────┴──────────┘SELECT
site_id,
sequenceCount('(?1)(?t<=15)(?2).*(?3)')(
ts_date_time,
event_type = 'shtLogon',
event_type = 'shtKkclick' AND column_type = 'homePage',
event_type = 'shtAddCart'
) AS seq_count
FROM ods.analytics_access_log_all
WHERE ts_date >= '2020-07-01'
AND site_id IN (10266,10022,10339,10030)
GROUP BY site_id;
┌─site_id─┬─seq_count─┐
│ 10030 │ 33611 │
│ 10339 │ 14045 │
│ 10266 │ 74542 │
│ 10022 │ 31534 │
└─────────┴───────────┘这两个函数都需要指定模式串、时间列和期望的事件序列(最多可指定32个事件)。模式串的语法有以下三种:
(?N):表示时间序列中的第N个事件,从1开始。例如上述SQL中,(?2)即表示event_type = 'shtKkclick' AND column_type = 'homePage'。(?t op secs):插入两个事件之间,表示它们发生时需要满足的时间条件(单位为秒)。例如上述SQL中,(?1)(?t<=15)(?2)即表示事件1和2发生的时间间隔在15秒以内。.*:表示任意的非指定事件。
智能路径检测
CK内置的sequenceMatch和sequenceCount函数只能满足部分需求,现有一个更复杂的需求:
给定期望的路径终点、途经点和最大事件时间间隔,查询出符合条件的路径详情及符合路径的用户数(按用户数降序排列)。
目前并没有现成的函数可以直接出结果,但是我们可以曲线救国,用数组和高阶函数的组合间接实现。完整SQL语句如下,略长:
SELECT
result_chain,
uniqCombined(user_id) AS user_count
FROM (
WITH
toUInt32(maxIf(ts_date_time, event_type = 'shtOrderDone')) AS end_event_maxt,
arrayCompact(arraySort(
x -> x.1,
arrayFilter(
x -> x.1 <= end_event_maxt,
groupArray((toUInt32(ts_date_time), (event_type, column_type)))
)
)) AS sorted_events,
arrayEnumerate(sorted_events) AS event_idxs,
arrayFilter(
(x, y, z) -> z.1 <= end_event_maxt AND (z.2.1 = 'shtOrderDone' OR y > 600),
event_idxs,
arrayDifference(sorted_events.1),
sorted_events
) AS gap_idxs,
arrayMap(x -> x + 1, gap_idxs) AS gap_idxs_,
arrayMap(x -> if(has(gap_idxs_, x), 1, 0), event_idxs) AS gap_masks,
arraySplit((x, y) -> y, sorted_events, gap_masks) AS split_events
SELECT
user_id,
arrayJoin(split_events) AS event_chain_,
arrayCompact(event_chain_.2) AS event_chain,
hasAll(event_chain, [('shtKkClick', 'homePage')]) AS has_midway_hit,
arrayStringConcat(arrayMap(
x -> concat(x.1, '#', x.2),
event_chain
), ' -> ') AS result_chain
FROM (
SELECT ts_date,ts_date_time,event_type,column_type,user_id
FROM ods.analytics_access_log_all
WHERE ts_date >= '2020-06-30' AND ts_date <= '2020-07-02'
AND site_id IN (10266,10022,10339,10030)
)
GROUP BY user_id
HAVING length(event_chain) > 1
)
WHERE event_chain[length(event_chain)].1 = 'shtOrderDone'
AND has_midway_hit = 1
GROUP BY result_chain
ORDER BY user_count DESC LIMIT 20;简述思路:
将用户的行为用groupArray函数整理成<时间, <事件名, 页面名>>的元组,并用arraySort函数按时间升序排序;
利用arrayEnumerate函数获取原始行为链的下标数组;
利用arrayFilter和arrayDifference函数,过滤出原始行为链中的分界点下标。分界点的条件是路径终点或者时间差大于最大间隔;
利用arrayMap和has函数获取下标数组的掩码(由0和1组成的序列),用于最终切分,1表示分界点;
调用arraySplit函数将原始行为链按分界点切分成单次访问的行为链。注意该函数会将分界点作为新链的起始点,所以前面要将分界点的下标加1;
调用arrayJoin和arrayCompact函数将事件链的数组打平成多行单列,并去除相邻重复项。
调用hasAll函数确定是否全部存在指定的途经点。如果要求有任意一个途经点存在即可,就换用hasAny函数。当然,也可以修改WHERE谓词来排除指定的途经点。
将最终结果整理成可读的字符串,按行为链统计用户基数,完成。
有序漏斗转化
CK提供了windowFunnel函数实现漏斗,以指定时长(单位为秒)滑动窗口按序匹配事件链,并返回在窗口内转化到的步数。如有多种匹配,以步数最大(转换最深)的为准。
通过对该步数进行统计,即可得到漏斗中每步的转化率。SQL语句如下,查询结果是敏感数据,不再贴出来了。
SELECT
level,user_count,conv_rate_percent
FROM (
SELECT
level,
uniqCombined(user_id) AS user_count,
neighbor(user_count, -1) AS prev_user_count,
if (prev_user_count = 0, -1, round(user_count / prev_user_count * 100, 3)) AS conv_rate_percent
FROM (
SELECT
user_id,
windowFunnel(900)(
ts_date_time,
event_type = 'shtLogon',
event_type = 'shtKkClick' AND column_type = 'homePage',
event_type = 'shtOpenGoodsDetail',
event_type = 'shtAddCart',
event_type = 'shtOrderDone'
) AS level
FROM (
SELECT ts_date,ts_date_time,event_type,column_type,user_id
FROM ods.analytics_access_log_all
WHERE ts_date >= '2020-06-30' AND ts_date <= '2020-07-02'
AND site_id IN (10266,10022,10339,10030)
)
GROUP BY user_id
)
WHERE level > 0
GROUP BY level
ORDER BY level ASC
);如果想要更准确一些,实现漏斗步骤之间的字段关联(如商品详情→加入购物车→下单三步中的商品ID关联)怎么办呢?可以利用https://github.com/housepower/olap2018项目中提出的xFunnel函数。它是windowFunnel函数的鼻祖,不过需要修改ClickHouse源码并重新编译之,今后有时间的话会简单写一下过程。
用户留存
retention函数可以方便地计算留存情况。该函数接受多个条件,以第一个条件的结果为基准,观察后面的各个条件是否也满足,若满足则置1,不满足则置0,最终返回0和1的数组。通过统计1的数量,即可计算出留存率。
下面的SQL语句计算次日重复下单率与七日重复下单率(语义与留存相同)。
SELECT
sum(ret[1]) AS original,
sum(ret[2]) AS next_day_ret,
round(next_day_ret / original * 100, 3) AS next_day_ratio,
sum(ret[3]) AS seven_day_ret,
round(seven_day_ret / original * 100, 3) AS seven_day_ratio
FROM (
WITH toDate('2020-06-24') AS first_date
SELECT
user_id,
retention(
ts_date = first_date,
ts_date = first_date + INTERVAL 1 DAY,
ts_date = first_date + INTERVAL 7 DAY
) AS ret
FROM ods.ms_order_done_all
WHERE ts_date >= first_date AND ts_date <= first_date + INTERVAL 7 DAY
GROUP BY user_id
);Session统计
Session,即"会话",是指在指定的时间段内在网站/H5/小程序/APP上发生的一系列用户行为的集合。例如,一次会话可以包含多个页面浏览、交互事件等。Session是具备时间属性的,根据不同的切割规则,可以生成不同长度的Session。
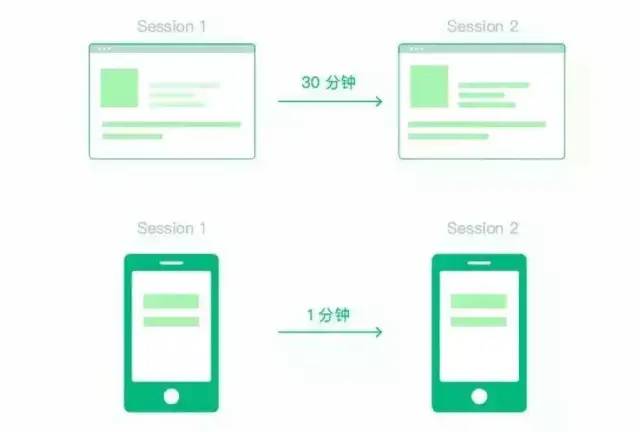
可见,Session统计与上述智能路径检测的场景有相似之处,都需要寻找用户行为链的边界并进行切割。以下SQL语句以30分钟为超时时间,按天统计所有用户的Session总数(跨天的Session也会被切割)。
SELECT
ts_date,
sum(length(session_gaps)) AS session_cnt
FROM (
WITH
arraySort(groupArray(toUInt32(ts_date_time))) AS times,
arrayDifference(times) AS times_diff
SELECT
ts_date,
arrayFilter(x -> x > 1800, times_diff) AS session_gaps
FROM ods.analytics_access_log_all
WHERE ts_date >= '2020-06-30'
GROUP BY ts_date,user_id
)
GROUP BY ts_date;

版权声明:
文章不错?点个【在看】吧! ?