
spring cloud------ hystrix熔断机制
在spring cloud微服务架构中熔断机制是必不可少的一个重要功能点。我们先了解一下什么是熔断,熔断是怎么产生的?
一、熔断产生的原因
雪崩效应:是一种因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程。
比如我们去访问一个服务的时候,发现这个服务崩了,然后我们一直在访问,后面的也一直排队等访问,但是我们有没有成功,导致后面所有的请求在排队,就越来越多的请求等待,这时候系统的资源也会被逐渐的给耗尽,导致所有的服务都可能崩。
产生的原因:
1、服务提供者出现故障导致不可用 :短时间大量的用户请求;硬件故障:硬件损坏造成的服务器主机宕机, 网络硬件故障造成的服务提供者的不可访问;程序bug;缓存击穿:缓存击穿一般发生在缓存应用重启, 所有缓存被清空时,以及短时间内大量缓存失效时. 大量的缓存不命中, 使请求直击后端,造成服务提供者超负荷运行,引起服务不可用;
2、开启重试机制导致流量的增加;
3、服务调用者不可用
同步等待造成的资源耗尽:当服务调用者使用同步调用 时, 会产生大量的等待线程占用系统资源. 一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态, 于是服务雪崩效应产生了。
二、什么是熔断
可能一提及到熔断的话,大家第一时间可能就想起保险丝,对,没错,其实代码中熔断的作用和保险丝是一样的,都是为了保护我们的东西不受损,保险丝保护我们的用电器不会损坏,编程中保护我们的服务资源不会被耗尽。总的来说就相当于一个保护机制。他有两个方面一个叫服务熔断:就是当这个服务出现故障的时候,来访问我的请求我会直接响应他一个fallback而不会让他一直等待请求。还有一个就是服务降级:当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
三、hystrix的工作原理
我们用下面的这个图来讲: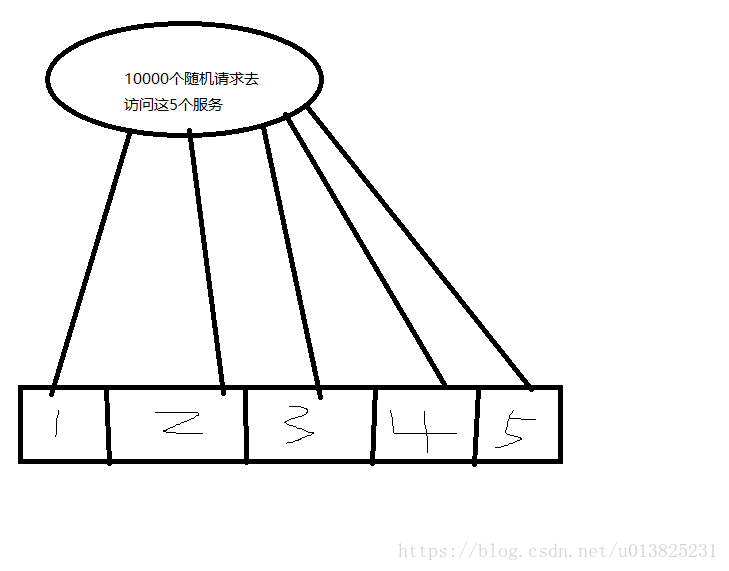
在没有hystrix之前,假如我们有100个线程可供调用,这时候我们1000的请求访问的时候是随机去访问的,也就是说前100个请求会去占用线程,后面的会去等待,加入运气不好,前面的100个请求都是去请求服务1的话,并且服务1出现故障,那么就会导致所有线程都不会释放,而剩下的9990个请求都在排队等待,如果后续还有请求,那么我们系统就要崩了。
而hystrix的原理其实是在服务和请求之前增加了一个线程池,原理其实就是用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,则会进行降级处理,用户的请求不会被阻塞,至少可以看到一个执行结果(例如返回友好的提示信息),而不是无休止的等待或者看到系统崩溃。
1、Hystrix为每个依赖调用分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间。线程数是可以被设定的。
在加hystrix之前我们是上图这样的结构,加入之后是这样的: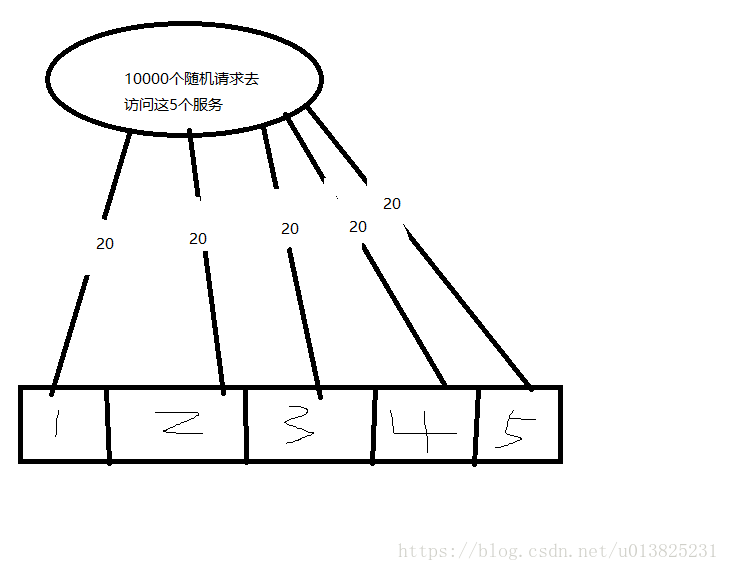
我们这样就在某个服务之前都分配了20个线程,这样的话,当我们的请求进来的时候,不管你前面的请求有多少个是服务1的都不会影响其他的服务,如果某个服务的线程满了的话,那么接下来请求会被拒绝或是降级。
如果某个目标服务调用慢或者有大量超时,此时,熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
熔断器是位于线程池之前的组件。用户请求某一服务之后,Hystrix会先经过熔断器,此时如果熔断器的状态是打开(跳起),则说明已经熔断,这时将直接进行降级处理,不会继续将请求发到线程池。熔断器相当于在线程池之前的一层屏障。每个熔断器默认维护10个bucket ,每秒创建一个bucket ,每个blucket记录成功,失败,超时,拒绝的次数。当有新的bucket被创建时,最旧的bucket会被抛弃。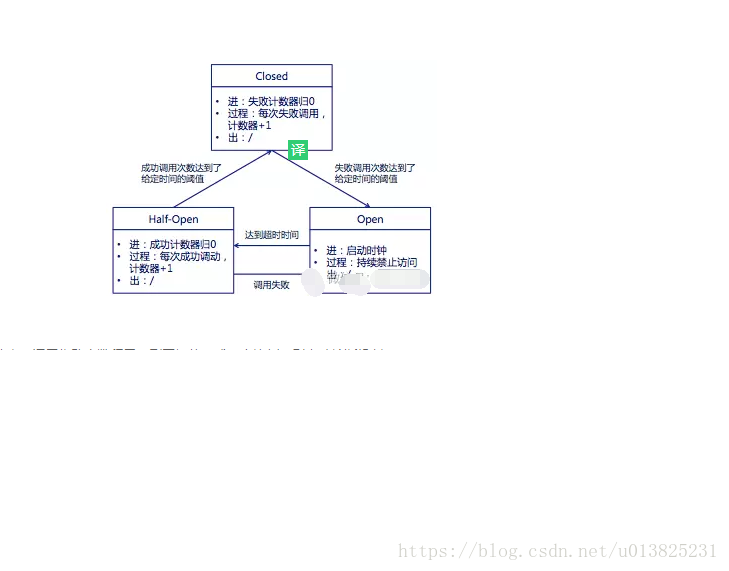
Closed:
熔断器关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制;
Open:
熔断器打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态;
Half-Open:
半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
四、spring boot中如何使用hystrix
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>我们在pom文件里面添加上面这个依赖。
添加完以后在我们的主函数上面添加这个注解@EnableHystrix或者是@EnableCircuitBreaker。
然后在你需要熔断操作的方法上面加一个 @HystrixCommand(fallbackMethod=”你需要回调的方法名”)注解,比如我们这样
@RequestMapping("/zj")
@HystrixCommand(fallbackMethod="test")
public String zj(){
return "zjhystrix";
}
public String test(){
return "error";
}上面的代码其实就是当我们请求调用这个接口的时候,我们发现这个接口有问题或者在加载过程中,这时候他不会一直去 等待响应,而是到达一个时间点后直接返回test里面的内容。之后的请求也就直接往test走,直到熔断恢复。
在spring cloud中还有一个hystrix监控,这个是Spring提供了hystrix-dashboard项目对支持hystrix熔断的项目提供链路状态监视的功能。
我们需要导入如下包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix-dashboard</artifactId>
</dependency>
然后在我们运行的主函数里面添加注解@EnableHystrixDashboard
然后访问http://localhost:8080/hystrix就会出现如下页面 
我们往里面添加这个http://localhost:8080/hystrix.stream并点击monitor stream按钮
进去之后看到是这样的页面 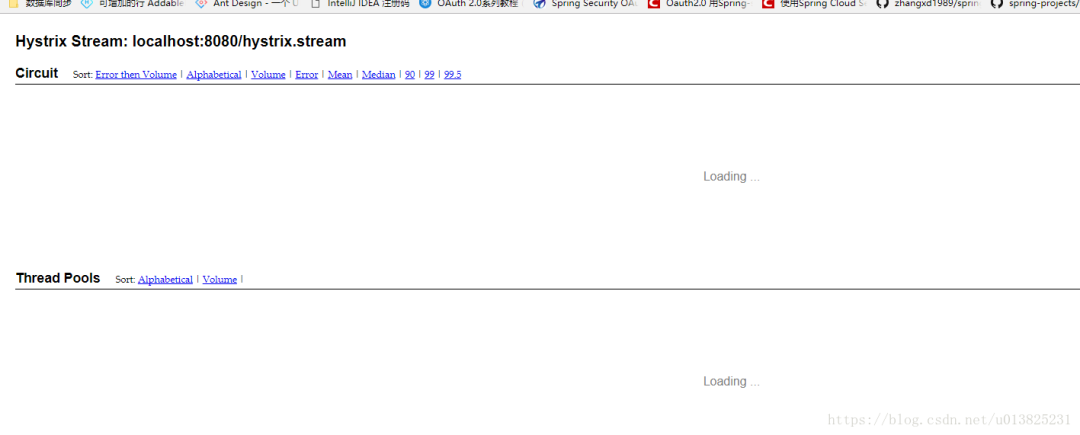
因为没有请求,所以一直处于loading,我们访问一下我们的那个接口,这时候就会出现另一个页面 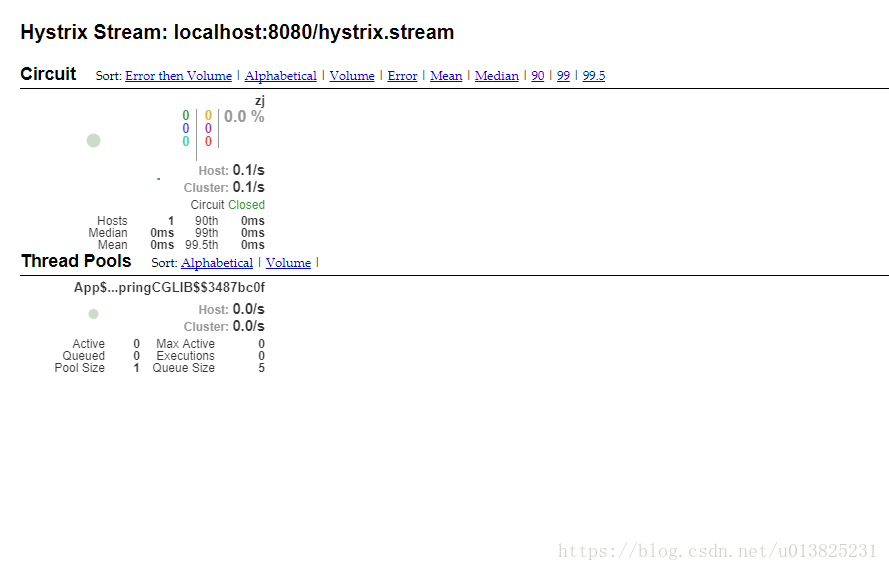
至于上面的每个指标我就不一一讲了。这个只是监控单应用的。
本文链接:https://blog.csdn.net/u013825231/article/details/79949420
end
*版权声明:转载文章和图片均来自公开网络,版权归作者本人所有,推送文章除非无法确认,我们都会注明作者和来源。如果出处有误或侵犯到原作者权益,请与我们联系删除或授权事宜。
长按识别图中二维码
关注获取更多资讯
不点关注,我们哪来故事?

点个再看,你最好看