
基于深度学习的人员跟踪
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

在不断进步的现代科技中,我认为最伟大的是我们在使计算机具有类似于人的感知能力方面取得了进步。以前训练计算机使它像人一样学习、做出像人一样的行为是很遥远的梦想。但现在随着神经网络和计算能力的进步,梦想逐渐成为现实。
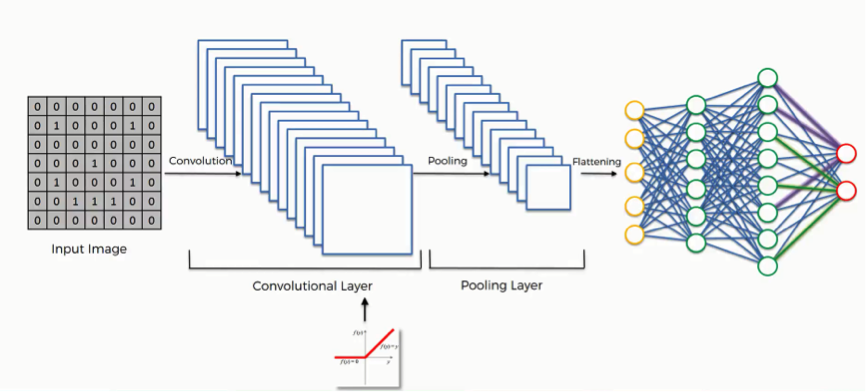
CNN
视觉智能是CNN(卷积神经网络)提供给计算机的。卷积神经网络是一种优雅的计算机制可以在图像或视频上运行,以便从图像或视频中提取一些信息。提取的信息允许用来进行机器学习任务,例如图像分类和目标定位。
目标检测通过在目标周围绘制边界框来定位视频帧或图像中的目标。我们可以将人员跟踪视为目标检测的一种形式——目标是人!在开始之前,先概述一下基本概念及原理。
1 基础知识
人员跟踪的工作原理:
1.在视频的第一帧中检测到每个人周围的边界框,图像的每个边界框区域生成一个128维向量。该步骤可视为将边界框区域编码为一个128个维的向量。
2.为图像中的所有人员生成这种向量以及边界框坐标。存储这些向量,并对视频的下一帧执行上述向量生成步骤。
3.比较所有向量,在“下一帧”中找到相似的向量,并相应地标记边界框。

这里深入研究的论文是:A Simple Baseline for Multi-Object Tracking. 这篇出色的论文改变了我们解决目标跟踪问题的方式。早期人们使用两阶段检测器(TSD)方法来解决类似问题。但本文针对此问题增强了单阶段检测(SSD)技术,提高了推理速度和准确性。
两阶段检测器:
在这种类型的检测器中,需要两个处理阶段:模型的一部分检测到边界框,提取边界框区域发送到模型的另一部分,利用CNN生成128维特征向量。
单阶段检测器:
这种类型的检测器,仅包含一个处理阶段:图像被送到模型中,仅通过一次即可生成输出。在TSD中,必须先产生候选边界框区域,之后剪切边界框区域进行特征提取处理。
鸟瞰图:
详细信息可以参考https://www.reddit.com/r/MachineLearning/comments/e9nm6b/d_what_is_the_definition_of_onestage_vs_twostage/
头部:
头部是CNN结构中负责特定任务的一部分。简而言之一个头部通过执行各种计算(涉及图像的卷积)来生成一些数字,如何解释和使用这些数字取决于我们。例如,我们有一个生成四个数字(x,y,w,h)集合的头部,那么这四个数字可以表示边界框坐标。与此类似不同的头部产生不同的数字,我们将根据自己的任务对数字进行解释。
边界框:
边界框由4个坐标(x,y,w,h)组成,(x,y)通常代表一个中心点,(w,h)代表宽度和高度。因此对图像执行一些计算,头部输出一组4维坐标那么代表边界框坐标。
锚框:
是一组预定义的数字(四个数字),类似于边界框坐标。我们重新缩放或移动的它以便可以更接近图像中的实际边界框。

放大后,锚框看起来像上面的图像,但它们数量庞大,几乎覆盖了所有图像的区域。想了解更多有关锚框的信息,请查看这篇文章:https://medium.com/@andersasac/anchor-boxes-the-key-to-quality-object-detection-ddf9d612d4f9
2 实现
利用深度学习跟踪人分为两个分支:1)目标检测分支;2)身份嵌入分支
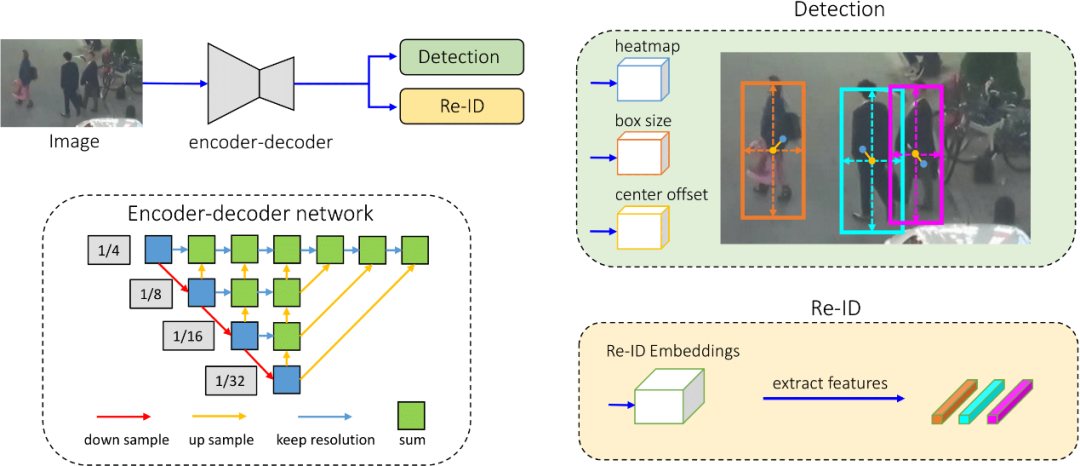
2.1目标检测分支
模型的这一部分负责检测图像中的目标,输出三组数字,将其组合以检测图像中存在的目标。
1. 热图信息:生成代表对象热图的数字,目标热图将通过以下公式生成:
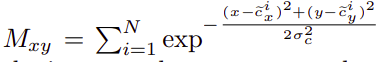
目标热图的公式
其中N代表图像中的物体数量,而σc代表标准偏差。为简单起见,假设我们根据所有地面真值框的中心创建目标热图,地面真值框的中心将具有很高的数值,并且随着远离中心,数值呈指数衰减。它将类似于下图:

根据真值框产生的热图为目标图像,该分支预测的目标热图为预测图像,我们可以根据此来定义损失,并使用随机梯度下降进行优化(神经网络的关键)。更多有关SGD的信息参考https://towardsdatascience.com/stochastic-gradient-descent-clearly-explained-53d239905d31它能帮助训练我们的网络,使实际输出与目标输出相似。
2. 中心偏移信息:预测边界框的中心,它输出一个数字解释目标边界框的中心在哪里。
3. 边界框尺寸信息:预测边界框的大小。通过组合中心偏移信息和框大小信息,可以生成预测的边界框。然后将该预测边界框与目标边界框进行比较,并使用SGD计算和优化损失,如前所述。
2.2身份嵌入分支
此分支负责生成与预测边界框相对应的图像块的向量表示,通常将图像补丁(区域块)的信息编码为128维向量,128维向量仅是模型的此分支为每个边界框预测生成的一组数字,该向量是相应帧中跟踪人物的关键。
2.3结合

我们研究了人员跟踪难题的每个部分,并对这些部分有了基本的了解。让我们将每个部分连接以获得最终的结果。
从视频的第一帧开始,将视频第一帧传递到网络(CNN)并获得4个输出。
1.热图输出;
2.中心偏移输出;
3.边界框尺寸输出;
4.Re-ID(128维重识别特征向量)
前三个输出负责获取图像中目标(人员)的边界框,第四个输出表示对象的标识,由前三个输出生成的边界框表示产生。如果从前三个输出预测有n个边界框,则将有n个表示所有边界框的128维向量标识。
现在,从第一帧开始预测n个框及其对应的Re-ID。我们将再次为下一帧生成Re-ID和边界框,然后通过一些相似性函数比较所有Re-ID,如果相似度很高,可以将其标记为与前一帧相同的人。通过这种方式可以处理整个视频并逐帧进行操作。
2.4训练方式
多种损失相结合来训练网络。网络训练是使用SGD的变体完成的。我将提供一些困难公式的高级详细信息,将其组合起来用作损失函数来训练模型。(注意:模型训练是使用称为反向传播的方法完成的,即简单地使用微积分朝函数的最小值移动——SGD的基本步骤)。
不同的损失是:



基本上,将所有这些损失综合起来并进行优化,从而获得训练有素的网络。
2.5总结理论
总之,我们为检测到的每个边界框使用网络产生向量,然后把这些向量与下一帧产生的向量进行匹配,并根据高度相似性进行过滤,以跨多个帧跟踪同一个人。
2 人员跟踪-代码实现
要从用于跟踪的视频中生成输出,您必须执行以下5个简单步骤:
第1步
克隆git仓库到所需文件夹:
https://github.com/harsh2912/people-tracking
存储库的原始代码是:
https://github.com/ifzhang/FairMOT
我对其进行了一些更改,使其适合我们当前的视频人员跟踪的任务。
第2步
下载预训练模型:
https://github.com/harsh2912/people-tracking
这将帮助我们生成所需的输出,将下载的模型放在models /文件夹中。
第3步
安装依赖项:安装所需的依赖项,以便脚本可以运行。请确保具有支持CUDA的GPU,以便此过程可以正常进行,执行以下操作:
conda create -n FairMOTconda activate FairMOTconda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=10.0 -c pytorchcd ${FAIRMOT_ROOT}pip install -r requirements.txtcd src/lib/models/networks/DCNv2_new sh make.sh
在这里,您只需创建一个称为FairMOT的conda环境,即可在其中使用pip和conda管理器安装所有Python依赖项。requirements.txt是包含所有必需库的文件,pip安装程序注意该文件。不要忘记运行DCNv2的make文件。
第4步
开始追踪:已完成所有设置,只需要运行适用于给定视频的Python脚本,然后生成输出并将其保存在上述路径中即可。我已将Python脚本命名为script.py,您可以根据需要对其进行调用。
该脚本具有三个输入参数:
1.model_path(mp):保存模型的路径
2.video_path(vp):加载视频的路径
3.output_directory(od):保存输出的路径,输出保存的名称为“ output.avi”
转到src文件夹并运行下面命令,其中mp,vp和od是参数名称。
cd srcpython script.py -mp ../models/all_dla34.pth -vp path_to_video -od path_to_save_video
第5步
休息一下,等待模型输出结果。在这段时间中,输出将保存在相应的目录中。

额外事项
我上传了一个名为Experiment.ipynb的iPython文件,您可以在其中调整不同的参数以发挥更多作用。它位于主存储库的src文件夹中。要了解不同参数的调整,请浏览原始存储库。请不要忘记在使用该文件时使用相同的conda环境

参考
1.论文:https://arxiv.org/abs/2004.01888
2.原始仓库:https://github.com/ifzhang/FairMOT
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~