
恕我直言,很多小样本学习的工作就是不切实际的

极市导读
NYU、facebook、CIFAR最新文章表示:以前prompt 的方法也不是真正的小样本学习,真正的小样本学习,训练集验证集都要小! >>加入极市CV技术交流群,走在计算机视觉的最前沿

True Few-Shot Learning with Language Models
http://arxiv-download.xixiaoyao.cn/pdf/2105.11447v1.pdf
https://github.com/ethanjperez/true_few_shot
真正的小样本学习
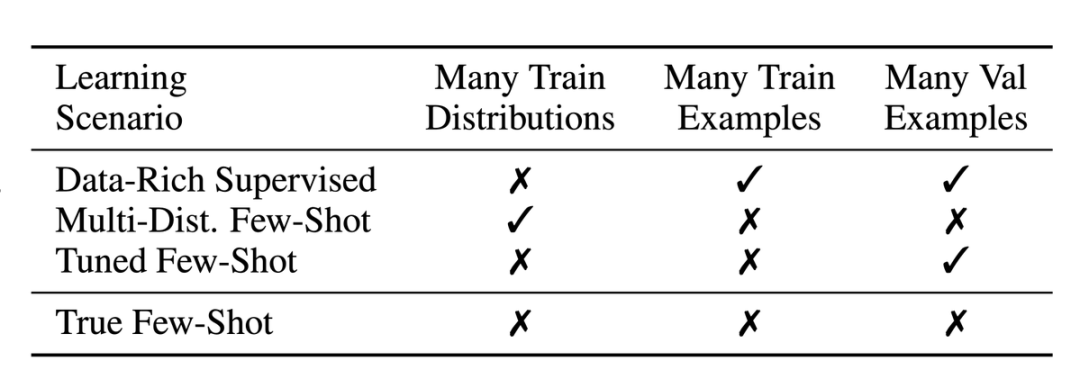
Data-Rich Supervised 表示传统有大量数据的有监督学习。 Multi-Distribution Few-Shot 表示原始的小样本学习情景,即在大量 n-way k-shot 上进行训练。由于每个 task 都包含不同的数据分布,因此这相当于在不同的分布中训练,在新的分布中使用模型。 Tuned Few-Shot 表示从 GPT3 开始的,用 prompt 的方式对预训练模型微调。 True Few-Shot 就是本文提出的啦!
那还能调参嘛?
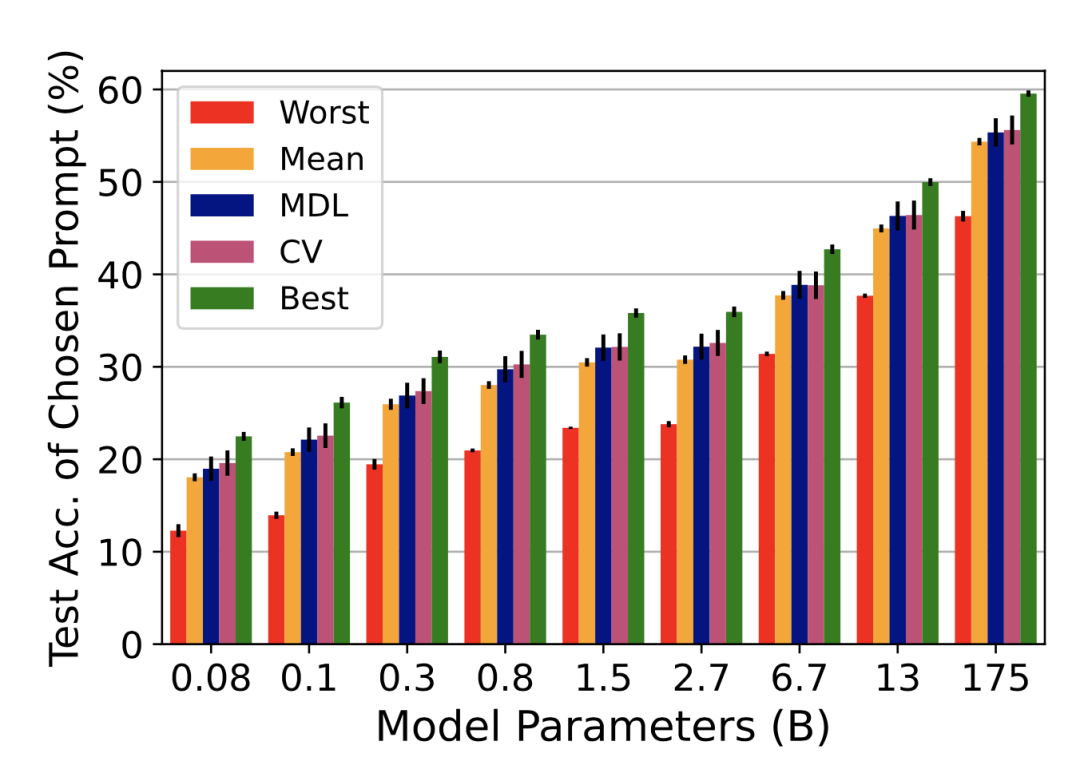
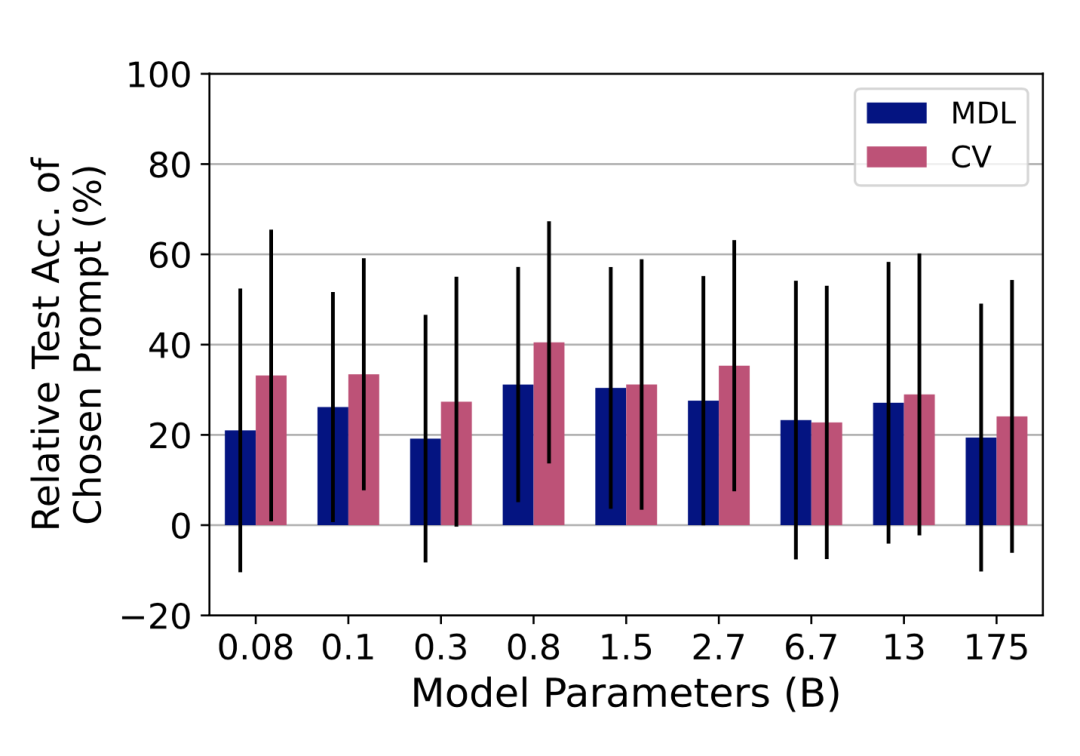
k 折交叉验证:将数据集分为 k 个部分,用其中 k-1 个部分作为训练集,剩下的一个部分作为验证集。在后面的实验中,这种方法被称作 CV(cross validation)。
类似在线学习的交叉验证:将数据集分为 k 个部分,第 1 轮用第 1 部分训练,第 2 部分验证,第 i 轮用前 i 部分训练,第 i+1 部分验证。在后面的实验中,这种方法被称作 MDL(minimum description lengthm),因为其本质上遵循的是最小描述长度准则。
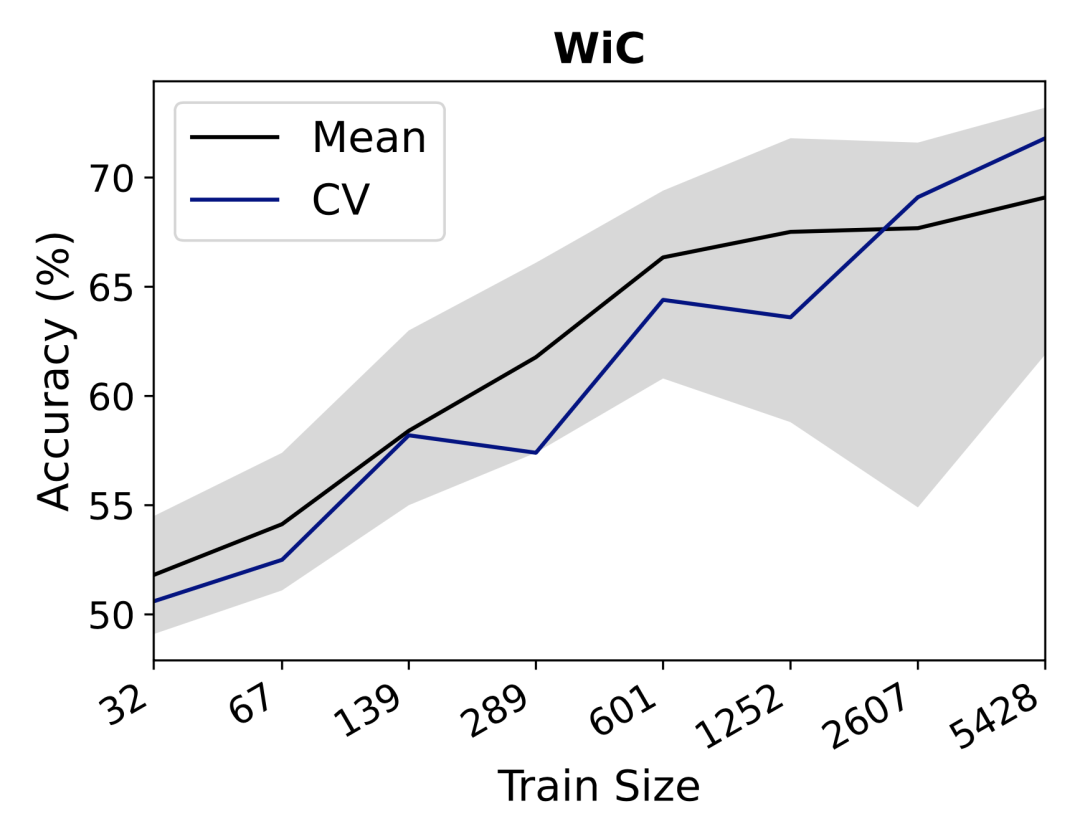
实验和分析

总结
在写文章的时候,同时注明模型选择的原则,以及所有超参数和尝试的 prompts。 将验证集的数量也归入小样本学习的“数据量”里。 当有大量样本作为验证集的时候,先不要用!先在测试集直接得到结果、做消融实验,等所有试验完成后,最后再引入验证集。这样避免实验结果使用验证集大量样本的信息。 不要使用前人工作中的超参数,只在这少量样本中重新调参。
本文亮点总结
在写文章的时候,同时注明模型选择的原则,以及所有超参数和尝试的 prompts。 将验证集的数量也归入小样本学习的“数据量”里。 当有大量样本作为验证集的时候,先不要用!先在测试集直接得到结果、做消融实验,等所有试验完成后,最后再引入验证集。这样避免实验结果使用验证集大量样本的信息。 不要使用前人工作中的超参数,只在这少量样本中重新调参。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“长尾”获取长尾特征学习资源~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论