
【NLP】DataCLUE: 国内首个以数据为中心的AI测评
DataCLUE
以数据为中心的AI测评(含模型和数据分析报告)
DataCLUE: A Chinese Data-centric Language Evaluation Benchmark
Github项目地址:
https://github.com/CLUEbenchmark/DataCLUE
官网:
www.CLUEbenchmarks.com/dataclue.html 或 www.clue.ai
内容导引
| 章节 | 描述 |
|---|---|
| 简介 | 介绍以数据为中心的AI测评(DataCLUE)的背景 |
| 任务描述 | 任务描述 |
| 实验结果 | 针对各种不同方法,在FewCLUE上的实验对比 |
| 实验分析 | 对人类表现、模型能力和任务进行分析 |
| 数据为中心的AI_方法论介绍 | 数据为中心的AI:方法论介绍 |
| DataCLUE有什么特点 | 特点介绍 |
| 基线模型及运行 | 支持多种基线模型 |
| DataCLUE测评及规则 | DataCLUE测评及规则 |
| 数据集介绍 | 介绍数据集及示例 |
| 贡献与参与 | 如何参与项目或反馈问题 |
简介
以数据为中心(Data-centric)的AI,是一种新型的AI探索方向。它的核心问题是如何通过系统化的改造你的数据(无论是输入或者标签)来提高最终效果。传统的AI是以模型为中心(Model-centric)的,主要考虑的问题是如何通过改造或优化模型来提高最终效果,它通常建立在一个比较固定的数据集上。最新的数据显示超过90%的论文都是以模型为中心的,通过模型创新或学习方法改进提高效果,即使不少改进影响可能效果并不是特别明显。有些人认为当前的人工智能领域, 无论是自然语言处理(如BERT) 或计算机视觉(ResNet), 已经存在很多成熟高效模型,并且模型可以很容易从开源网站如github获得;而与此同时,工业界实际落地 过程中可能有80%的时间用于 清洗数据、构建高质量数据集,或在迭代过程中获得更多数据,从而提升模型效果。正是看到了这种巨大的差别,在吴恩达等人的推动下这种 以数据为中心 (Data-centric)的AI进一步的系统化,并成为一个有具有巨大实用价值方法论。
DataCLUE是一个以数据为中心的AI测评。它基于CLUE benchmark,结合Data-centric的AI的典型特征,进一步将Data-centric的AI应用于 NLP领域,融入文本领域的特定并创造性丰富和发展了Data-centric的AI。在原始数据集外,它通过提供额外的高价值的数据和数据和模型分析报告(增值服务)的形式, 使得融入人类的AI迭代过程(Human-in-the-loop AI pipeline)变得更加高效,并能较大幅度的提升最终效果。
任务描述
参与测评者需要改进任务下的数据集来提升任务的最终效果;将使用固定的模型和程序代码(公开)来训练数据集,并得到任务效果的数据。可以对训练集、验证集进行修改或者移动训练集和验证集建的数据,也可以通过非爬虫类手段新增数据来完善数据集。可以通过算法或程序或者结合人工的方式来改进数据集。参与测评者需提交修改后的训练集和验证的压缩包。
任务描述和统计

实验结果
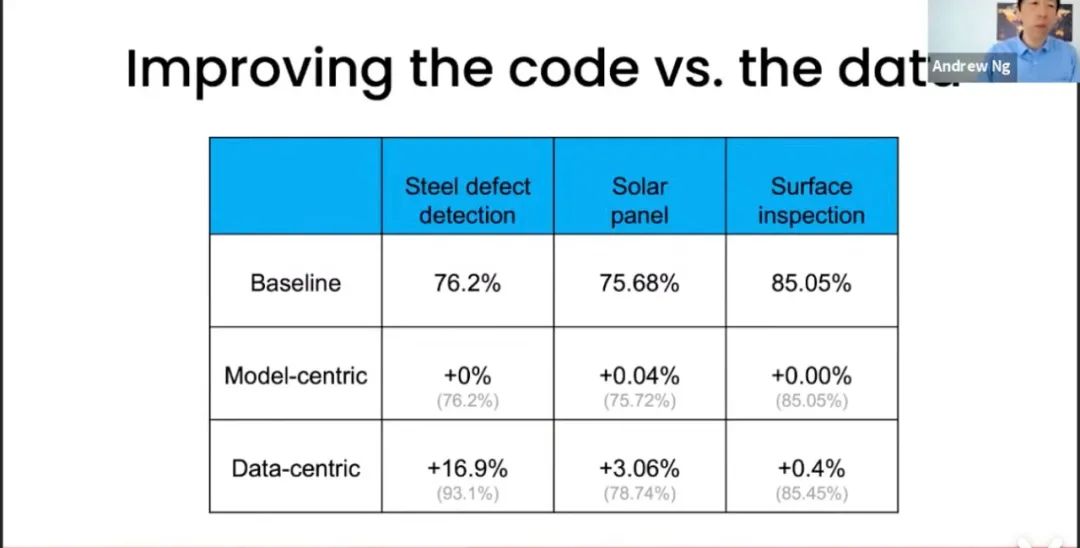
| IFLYTEK(acc) | |
|---|---|
| Human | 80.30 |
| Baseline | 56.42 |
| Model-centric | 59.31 |
| Data-centric | Report on 2021-09-15 |
实验分析
TODO 这里是实验分析 需要结合实验数据做一些说明。以模型为中心、以数据为中心效果是否一样的呢,或者某种方式可以得到更好的效果。
数据为中心的AI-方法论介绍
这里简单介绍一下以数据为中心的AI的方法论。包括一张图介绍一下流程,并做一下说明;可以附加tips。
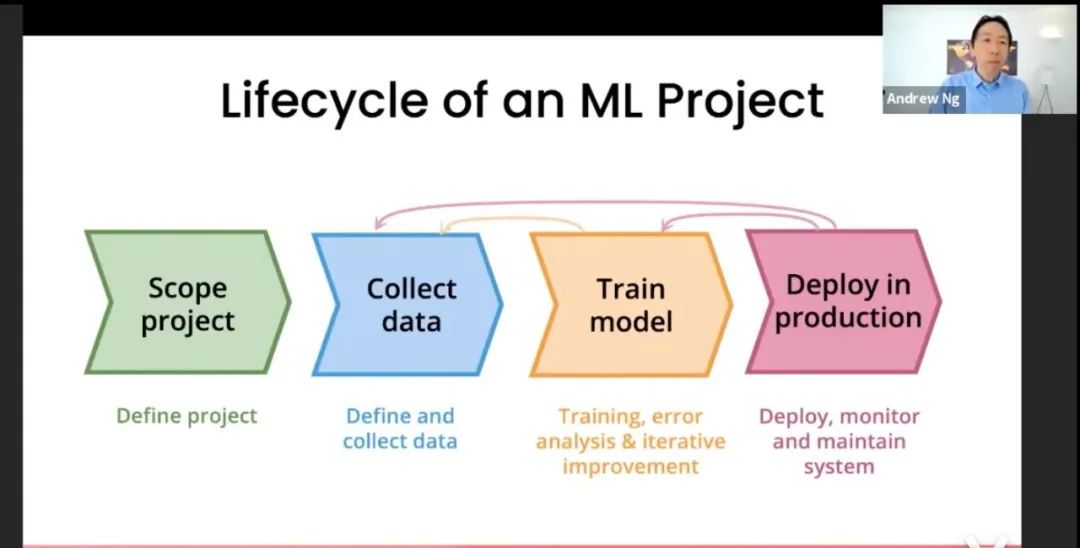
流程图:1.定义任务-->2.收集数据--->3.训练模型-->4.部署模型
系统化方式、通过迭代形式改进数据集:
#1.训练模型;
#2.错误分析:发现算法模型在哪些类型的数据上表现不佳(如:数据过短导致语义没有表达完全、一些类别间概念容易混淆导致标签可能不正确)
#3.改进数据:
1)更多数据:数据增强、数据生成或搜集更多数据--->获得更多的输入数据。
2)更一致的标签定义:当有些类别容易混淆的时候,改进标签的定义--->基于清晰的标签定义,纠正部分数据的标签。
#4.重复#1-#3的步骤。
DataCLUE有什么特点
1、国内首个以数据为中心的AI测评。之前的测评一般是在固定的数据集下使用不同的模型或学习方式来提升效果,而DataCLUE是需要改进数据集。
2、它是中文NLP任务在以数据为中心的思想下的实践。
3、更丰富的信息:除了常规的训练、验证和测试集外,它还额外提供了标签的定义、训练集中进一步标注后的高质量数据。结合这些额外的信息,使得 融入人类的AI迭代闭环(Human-in-the-loop AI pipeline)可以变得更加高效,并且在发挥算法模型在数据迭代过程中可以有更多空间和潜力。
4、增值服务:我们还额外提供模型训练和预测过程中的分析报告,为以数据为中心的AI的迭代过程变得更有方向和系统化。
基线模型及运行
一键运行.基线模型与代码 Baseline with codes
使用方式:
1、克隆项目
git clone https://github.com/CLUEbenchmark/DataCLUE.git
进入到项目目录 cd DataCLUE
2、进入到相应的目录
分类任务
例如:
cd ./baselines/models_pytorch/classifier_pytorch
3、运行对应任务的脚本(GPU方式): 会自动下载模型和任务数据并开始运行。
bash run_classifier_xxx.sh
如运行: bash run_classifier_iflytek.sh 会开始iflytek任务的训练。
训练完后也会得到在验证集上的效果,见 ./output_dir/bert/checkpoint_eval_results.txt
DataCLUE测评及规则
1.测评方式:
修改训练集和验证集,并将压缩包上传到CLUE benchmark
使用如下命令得到压缩包: zip dataclue_<team_name>_<data_string>.zip train.json dev.json 具体格式见:提交样例
2.测评规则:
1.1 可以对训练集、验证集进行修改(输入文本或标签),或者移动训练集和验证集的数据;
1.2 可以通过非爬虫类手段增加数据来完善训练和验证集。增加数据方式,包括但不限于:数据增强、文本生成、结合分析定向生成或添加。
1.3 可以通过算法或程序,或者结合人工的方式来改进数据集;
2.1 鼓励通过结合算法、模型和程序来改进数据集,也同样鼓励算法模型结合人工进行数据改进;但纯人工方式的数据改进,评审环节将不得分。
3.测评时间规划:2021年9月12日---2021年12月12日
1) 报名开始与截止:2021年9月12日--2021年10月25日
2) 初赛:2021年9月12日--2021年10月30日。前80名并超过Data-centric的baseline进入到复赛。初始选手,也将获得数据和模型的分析报告(简称增值服务)
训练集 & 验证集提供:2021年9月12;提交入口开放:2021年9月15日;每天22点更新一次在线成绩。
3) 复赛:2021年11月1日--2021年12月5日。复赛时,将提供额外高质量标注数据。前15名进入到线上评审,进行在线答辩。
4) 线上评审:2021年12月12日(下午2点-5点)。最终成绩:线上得分* 0.65 + 线上方案评审 * 0.35
线上方案评审:方案评审通过考察参赛队伍提交方案的新颖性、实用性和解释答辩表现力来打分,由5位评审老师打分;
每只队伍有10分钟的时间讲解方案,5分钟来回答问题。方案评审将以直播方法进行。
数据集介绍
1、IFLYTEK 长文本分类数据集 Long Text classification 该数据集关于app应用描述的长文本标注数据,包含和日常生活相关的各类应用主题,共119个类别:"打车":0,"地图导航":1,"免费WIFI":2,"租车":3,…. ,"女性":115,"经营":116,"收款":117,"其他":118(分别用0-118表示)。
数量,训练集:12133 ;验证集:2599
例子:
{"label": "110", "label_des": "社区超市", "sentence": "朴朴快送超市创立于2016年,专注于打造移动端30分钟即时配送一站式购物平台,商品品类包含水果、蔬菜、肉禽蛋奶、海鲜水产、粮油调味、酒水饮料、休闲食品、日用品、外卖等。朴朴公司希望能以全新的商业模式,更高效快捷的仓储配送模式,致力于成为更快、更好、更多、更省的在线零售平台,带给消费者更好的消费体验,同时推动中国食品安全进程,成为一家让社会尊敬的互联网公司。,朴朴一下,又好又快,1.配送时间提示更加清晰友好2.保障用户隐私的一些优化3.其他提高使用体验的调整4.修复了一些已知bug"}
每一条数据有三个属性,从前往后分别是 类别ID,类别名称,文本内容。学习资料
1、吴恩达新课:从以模型为中心到以数据为中心的AI(1小时)
贡献与参与
往期精彩回顾 本站qq群851320808,加入微信群请扫码: