
迁移学习理论与实践
↑ 点击蓝字 关注极市平台

极市导读
随着越来越多的机器学习应用场景的出现,而现有表现比较好的监督学习需要大量的标注数据,标注数据是一项枯燥无味且花费巨大的任务,所以迁移学习受到越来越多的关注。本文阐述了迁移学习的理论知识、基于ResNet的迁移学习实验以及基于resnet50的迁移学习模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
迁移学习:深度学习未来五年的驱动力?

迁移学习的使用场景
深度卷积网络的可迁移性

迁移学习的使用方法
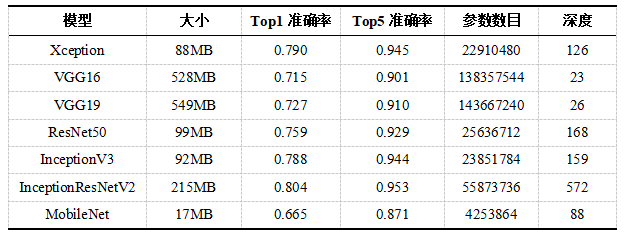
基于ResNet的迁移学习实验
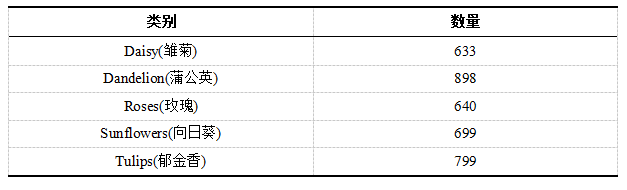
# 导入相关模块import osimport pandas as pdimport numpy as npimport cv2import matplotlib.pyplot as pltfrom PIL import Imagefrom sklearn.preprocessing import LabelEncoderfrom sklearn.model_selection import train_test_splitimport kerasfrom keras.models import Modelfrom keras.layers import Dense, Activation, Flatten, Dropoutfrom keras.utils import np_utilsfrom keras.applications.resnet50 import ResNet50from tqdm import tqdm
提取数据标签
def generate_csv(path):labels = pd.DataFrame()# 目录下每一类别文件夹items = [f for f in os.listdir(path)]# 遍历每一类别文件夹for i in tqdm(items):# 生成图片完整路径images = [path + I + '/' + img for img in os.listdir(path+i)]# 生成两列:图像路径和对应标签labels_data = pd.DataFrame({'images': images, ‘labels’: i})# 逐条记录合并labels = pd.concat((labels, labels_data))# 打乱顺序labels = labels.sample(frac=1, random_state=42)return labels# 生成标签并查看前5行labels = generate_csv('./flowers/')labels.head()
图片预处理

# resize缩放img = cv2.resize(img, (224, 224))# 转换成RGB色彩显示img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)plt.imshow(img)plt.xticks([])plt.yticks([])
 图9.6 缩放后的效果
图9.6 缩放后的效果# 定义批量读取并缩放def read_images(df, resize_dim):total = 0images_array = []# 遍历标签文件中的图像路径for i in tqdm(df.images):# 读取并resizeimg = cv2.imread(i)img_resized = cv2.resize(img, resize_dim)total += 1# 存入图像数组中images_array.append(img_resized)'iamges have resized.')return images_array# 批量读取images_array = read_images(labels, (224, 224))
准备数据
# 转化为图像数组X = np.array(images_array)# 标签编码lbl = LabelEncoder().fit(list(labels['labels'].values))labels['code_labels']=pd.DataFrame(lbl.transform(list(labels['labels'].values)))# 分类标签转换y = np_utils.to_categorical(labels.code_labels.values, 5)
# 划分为训练和验证集X_train, X_valid, y_train, y_valid =train_test_split(X,y,test_size=0.2, random_state=42)
# 训练集生成器,中间做一些数据增强train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.4,height_shift_range=0.4,shear_range=0.2,zoom_range=0.3,horizontal_flip=True)# 验证集生成器,无需做数据增强val_datagen = ImageDataGenerator(rescale=1./255)# 按批次导入训练数据train_generator = train_datagen.flow(X_train,y_train,batch_size=32)# 按批次导入验证数据val_generator = val_datagen.flow(X_valid,y_valid,batch_size=32)
基于resnet50的迁移学习模型
# 定义模型构建函数def flower_model():base_model=ResNet50(include_top=False,weights='imagenet', input_shape=(224, 224, 3))# 冻结base_model的层,不参与训练for layers in base_model.layers:layers.trainable = False# base_model的输出并展平model = Flatten()(base_model.output)# 添加批归一化层model = BatchNormalization()(model)# 全连接层model=Dense(2048,activation='relu', kernel_initializer=he_normal(seed=42))(model)# 添加批归一化层model = BatchNormalization()(model)# 全连接层model=Dense(1024,activation='relu', kernel_initializer=he_normal(seed=42))(model)# 添加批归一化层model = BatchNormalization()(model)# 全连接层并指定分类数和softmax激活函数model = Dense(5, activation='softmax')(model)model = Model(inputs=base_model.input, outputs=model)# 指定损失函数、优化器、性能度量标准并编译model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])return model
# 调用模型model = flower_model()# 使用fit_generator方法执行训练flower_model.fit_generator(generator=train_generator,steps_per_epoch=len(train_data)/32,epochs=30,validation_steps=len(val_data)/32,validation_data=val_generator,verbose=2)

推荐阅读


评论