
迁移学习理论与实践
Author:louwill
From:深度学习笔记
在深度学习模型日益庞大的今天,并非所有人都能满足从头开始训练一个模型的软硬件条件,稀缺的数据和昂贵的计算资源都是我们需要面对的难题。迁移学习(Transfer Learning)可以帮助我们缓解在数据和计算资源上的尴尬。作为当前深度学习领域中最重要的方法论之一,迁移学习有着自己自身的理论依据和实际效果验证。
迁移学习:深度学习未来五年的驱动力?
作为一门实验性学科,深度学习通常需要反复的实验和结果论证。在现在和将来,是否有海量的数据资源和强大的计算资源,这是决定学界和业界深度学习和人工智能发展的关键因素。通常情况下,获取海量的数据资源对于企业而言并非易事,尤其是对于像医疗等特定领域,要想做一个基于深度学习的医学影像的辅助诊断系统,大量且高质量的打标数据非常关键。但通常而言,不要说高质量,就是想获取大量的医疗数据就已困难重重。

图9.1 吴恩达说迁移学习
那怎么办呢?是不是获取不了海量的数据研究就一定进行不下去了?当然不是。因为我们有迁移学习。那究竟什么是迁移学习?顾名思义,迁移学习就是利用数据、任务或模型之间的相似性,将在旧的领域学习过或训练好的模型,应用于新的领域这样的一个过程。从这段定义里面,我们可以窥见迁移学习的关键点所在,即新的任务与旧的任务在数据、任务和模型之间的相似性。
在很多没有充分数据量的特定应用上,迁移学习会是一个极佳的研究方向。正如图9.1中吴恩达所说,迁移学习会是机器学习在未来五年内的下一个驱动力量。
迁移学习的使用场景
迁移学习到底在什么情况下使用呢?是不是我模型训练不好就可以用迁移学习进行改进?当然不是。如前文所言,使用迁移学习的主要原因在于数据资源的可获得性和训练任务的成本。当我们有海量的数据资源时,自然不需要迁移学习,机器学习系统很容易从海量数据中学习到一个很稳健的模型。但通常情况下,我们需要研究的领域可获得的数据极为有限,仅靠有限的数据量进行学习,所习得的模型必然是不稳健、效果差的,通常情况下很容易造成过拟合,在少量的训练样本上精度极高,但是泛化效果极差。另一个原因在于训练成本,即所依赖的计算资源和耗费的训练时间。通常情况下,很少有人从头开始训练一整个深度卷积网络,一个是上面提到的数据量的问题,另一个就是时间成本和计算资源的问题,从头开始训练一个卷积网络通常需要较长时间且依赖于强大的GPU计算资源,对于一门实验性极强的领域而言,花费好几天乃至一周的时间去训练一个深度神经网络通常是代价巨大的。
所以,迁移学习的使用场景如下:假设有两个任务系统A和B,任务A拥有海量的数据资源且已训练好,但并不是我们的目标任务,任务B是我们的目标任务,但数据量少且极为珍贵,这种场景便是典型的迁移学习的应用场景。那究竟什么时候使用迁移学习是有效的呢?对此我们不敢武断地下结论。但必须如前文所言,新的任务系统和旧的任务系统必须在数据、任务和模型等方面存在一定的相似性,你将一个训练好的语音识别系统迁移到放射科的图像识别系统上,恐怕结果不会太妙。所以,要判断一个迁移学习应用是否有效,最基本的原则还是要遵守,即任务A和任务B在输入上有一定的相似性,即两个任务的输入属于同一性质,要么同是图像、要么同是语音或其他,这便是前文所说到的任务系统的相似性的含义之一。
深度卷积网络的可迁移性
还有一个值得探讨的问题在于,深度卷积网络的可迁移性在于什么?为什么说两个任务具有同等性质的输入旧具备可迁移性?一切都还得从卷积神经网络的基本原理说起。由之前的学习我们知道,卷积神经网络具备良好的层次结构,通常而言,普通的卷积神经网络都具备卷积-池化-卷积-池化-全连接这样的层次结构,在深度可观时,卷积神经网络可以提取图像各个level的特征。如图9.2所示,当我们要从图像中识别一张人脸的时候,通常在一开始我们会检测到图像的横的、竖的等边缘特征,然后会检测到脸部的一些曲线特征,再进一步会检测到脸部的鼻子、眼睛和嘴巴等具备明显识别要素的特征。

图9.2 CNN人脸特征的逐层提取
这便揭示了深度卷积网络可迁移性的基本原理和卷积网络训练过程的基本事实。具备良好层次的深度卷积网络通常都是在最初的前几层学习到图像的通用特征(General Feature),但随着网络层次的加深,卷积网络便逐渐开始检测到图像的特定的特征,两个任务系统的输入越相近,深度卷积网络检测到的通用特征越多,迁移学习的效果越好。
迁移学习的使用方法
通常而言,迁移学习有两种使用方式。第一种便是常说的Finetune,即微调,简单而言就是将别人训练好的网络拿来进行简单修改用于自己的学习任务。在实际操作中,通常用预训练的网络权值对自己网络的权值进行初始化,以代替原先的随机初始化。第二种称为 Fixed Feature Extractor,即将预训练的网络作为新任务的特征提取器,在实际操作中通常将网络的前几层进行冻结,只训练最后的全连接层,这时候预训练网络便是一个特征提取器。
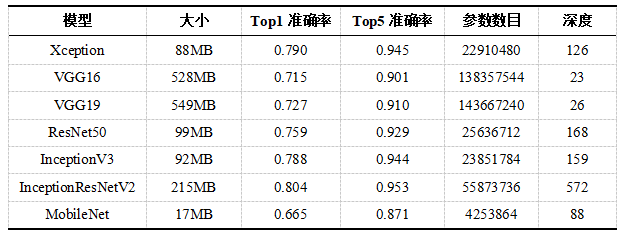
Keras为我们提供了经典网络在ImageNet上为我们训练好的预训练模型,预训练模型的基本信息如表1所示。
表1 Keras主要预训练模型
以上是迁移学习的基本理论和方法简介,下面来看一个简单的示例,来看看迁移学习的实际使用方法。
基于ResNet的迁移学习实验
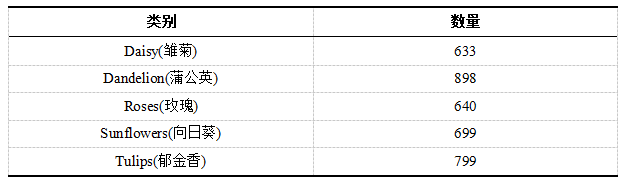
我们以一组包含五种类别花朵数据为例,使用ResNet50预训练模型进行迁移学习尝试。数据地址为https://www.kaggle.com/fleanend/flowers-classification-with-transfer-learning/#data。下载数据后解压可见共有5个文件夹,每个文件夹是一种花类,具体信息如下表2所示。
5种花型加起来不过是3669张图片,数据量不算小样本但也绝对算不上多。所以我们采取迁移学习的策略来搭建花朵识别系统。花型图片大致如图所示。
图 flowers数据集示例
需要导入的package,如代码9.1所示。
# 导入相关模块import osimport pandas as pdimport numpy as npimport cv2import matplotlib.pyplot as pltfrom PIL import Imagefrom sklearn.preprocessing import LabelEncoderfrom sklearn.model_selection import train_test_splitimport kerasfrom keras.models import Modelfrom keras.layers import Dense, Activation, Flatten, Dropoutfrom keras.utils import np_utilsfrom keras.applications.resnet50 import ResNet50from tqdm import tqdm
提取数据标签
数据没有单独给出标签文件,需要我们自行通过文件夹提取每张图片的标签,建立标签csv文件,如代码所示。
def generate_csv(path):labels = pd.DataFrame()# 目录下每一类别文件夹items = [f for f in os.listdir(path)]# 遍历每一类别文件夹for i in tqdm(items):# 生成图片完整路径images = [path + I + '/' + img for img in os.listdir(path+i)]# 生成两列:图像路径和对应标签labels_data = pd.DataFrame({'images': images, ‘labels’: i})# 逐条记录合并labels = pd.concat((labels, labels_data))# 打乱顺序labels = labels.sample(frac=1, random_state=42)return labels# 生成标签并查看前5行labels = generate_csv('./flowers/')labels.head()
标签提取结果示例如图9.4所示。
图9.4 提取标签结果
图片预处理
通过试验可知每张图片像素大小并不一致,所以在搭建模型之前,我们需要对图片进行整体缩放为统一尺寸。我们借助opencv的Python库cv2可以轻松实现图片缩放,因为后面我们的迁移学习策略采用的是ResNet50作为预训练模型,所以我们这里将图片缩放大小为 224*224*3。单张图片的resize示例如下。图9.5所示是一张玫瑰的原图展示。

图9.5 缩放前的原图
缩放如代码所示。缩放后的效果和尺寸如图9.6所示。
# resize缩放img = cv2.resize(img, (224, 224))# 转换成RGB色彩显示img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)plt.imshow(img)plt.xticks([])plt.yticks([])

图9.6 缩放后的效果
批量读取缩放如代码所示。
# 定义批量读取并缩放def read_images(df, resize_dim):total = 0images_array = []# 遍历标签文件中的图像路径for i in tqdm(df.images):# 读取并resizeimg = cv2.imread(i)img_resized = cv2.resize(img, resize_dim)total += 1# 存入图像数组中images_array.append(img_resized)'iamges have resized.')return images_array# 批量读取images_array = read_images(labels, (224, 224))
原始图片并不复杂,所以除了对其进行缩放处理之外基本无需多做处理。下一步我们需要准备训练和验证数据。
准备数据
处理好的图片无法直接拿来训练,我们需要将其转化为Numpy数组的形式,另外,标签也需要进一步的处理,如代码所示。
# 转化为图像数组X = np.array(images_array)# 标签编码lbl = LabelEncoder().fit(list(labels['labels'].values))labels['code_labels']=pd.DataFrame(lbl.transform(list(labels['labels'].values)))# 分类标签转换y = np_utils.to_categorical(labels.code_labels.values, 5)
转化后的图像数组大小为 3669*224*224*3,标签维度为3669*5,跟我们的实际数据一致。数据的准备好后,可以用Sklearn划分一下数据集:
# 划分为训练和验证集X_train, X_valid, y_train, y_valid =train_test_split(X,y,test_size=0.2, random_state=42)
然后可以用Keras的ImageDataGenerator模块来按批次生成训练数据,并对训练集做一些简单的数据增强,如下代码所示。
# 训练集生成器,中间做一些数据增强train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.4,height_shift_range=0.4,shear_range=0.2,zoom_range=0.3,horizontal_flip=True)# 验证集生成器,无需做数据增强val_datagen = ImageDataGenerator(rescale=1./255)# 按批次导入训练数据train_generator = train_datagen.flow(X_train,y_train,batch_size=32)# 按批次导入验证数据val_generator = val_datagen.flow(X_valid,y_valid,batch_size=32)
训练和验证数据划分完毕,现在我们可以利用迁移学习模型进行训练了。
基于resnet50的迁移学习模型
试验模型的基本策略就是使用预训练模型的权重作为特征提取器,将预训练的权重进行冻结,只训练全连接层。构建模型如下代码所示。
# 定义模型构建函数def flower_model():base_model=ResNet50(include_top=False,weights='imagenet', input_shape=(224, 224, 3))# 冻结base_model的层,不参与训练for layers in base_model.layers:layers.trainable = False# base_model的输出并展平model = Flatten()(base_model.output)# 添加批归一化层model = BatchNormalization()(model)# 全连接层model=Dense(2048,activation='relu', kernel_initializer=he_normal(seed=42))(model)# 添加批归一化层model = BatchNormalization()(model)# 全连接层model=Dense(1024,activation='relu', kernel_initializer=he_normal(seed=42))(model)# 添加批归一化层model = BatchNormalization()(model)# 全连接层并指定分类数和softmax激活函数model = Dense(5, activation='softmax')(model)model = Model(inputs=base_model.input, outputs=model)# 指定损失函数、优化器、性能度量标准并编译model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])return model
最后执行训练:
# 调用模型model = flower_model()# 使用fit_generator方法执行训练flower_model.fit_generator(generator=train_generator,steps_per_epoch=len(train_data)/32,epochs=30,validation_steps=len(val_data)/32,validation_data=val_generator,verbose=2)
训练过程如图9.7所示。

图9.7 迁移学习训练过程
经过20个epoch训练之后,验证集准确率会达到90%以上,读者朋友们可自行尝试一些模型改进方案来达到更高的精度。各位读者可以尝试分别使用VGG16、Inception v3和Xception来测试本讲的花朵识别实验。
往期精彩:

喜欢您就点个在看!
