
【NLP】四万字全面详解 | 深度学习中的注意力机制(四,完结篇)
作者 | 蘑菇先生
知乎 | 蘑菇先生学习记
深度学习Attention小综述系列:
本部分介绍Attention机制的各种变体。包括但不限于:
「基于强化学习的注意力机制」:选择性的Attend输入的某个部分 「全局&局部注意力机制」:其中,局部注意力机制可以选择性的Attend输入的某些部分 「多维度注意力机制」:捕获不同特征空间中的Attention特征。 「多源注意力机制」:Attend到多种源语言语句 「层次化注意力机制」:word->sentence->document 「注意力之上嵌一个注意力」:和层次化Attention有点像。 「多跳注意力机制」:和前面两种有点像,但是做法不太一样。且借助残差连接等机制,可以使用更深的网络构造多跳Attention。使得模型在得到下一个注意力时,能够考虑到之前的已经注意过的词。 「使用拷贝机制的注意力机制」:在生成式Attention基础上,添加具备拷贝输入源语句某部分子序列的能力。 「基于记忆的注意力机制」:把Attention抽象成Query,Key,Value三者之间的交互;引入先验构造记忆库。 「自注意力机制」:自己和自己做attention,使得每个位置的词都有全局的语义信息,有利于建立长依赖关系。
Memory-based Attention
ICLR 2015:Memory Networks[1] NIPS2015:End-To-End Memory Networks[2] ACL2016:Key-Value Memory Networks for Directly Reading Documents[3] ICML2016:Ask Me Anything:Dynamic Memory Networks for Natural Language Processing[4]
基于记忆的Attention机制将注意力分数的计算过程重新解释为根据查询/问题 进行soft memory addressing的过程,将编码视为从基于attention分值的memory中查询注意力分支的过程。
从重用性的角度上,这种注意力机制能够通过迭代memory更新(也称为多跳)来模拟时间推理过程,逐步将注意力引导到正确的答案位置,对于答案和问题没有「直接关系」的复杂问答效果较好(需要多步推理)。 从灵活性角度看,可以人工设计key的嵌入以更好的匹配问题,人工设计value的嵌入来更好的匹配答案。这种解耦的模块化设计,能够在不同组件中注入领域知识,使模块之间的通信更有效,并将模型推广到传统问答之外的更广泛的任务。
形式化来说,memory中存储的是key-value pairs,,给定一个查询 。定义上下文向量获取3步骤:
(address memory) (normalize) (read contents)
实际上memory存储的就是输入序列(更准确的说是外部记忆,输入序列是一种外部记忆,也可以引入其他领域先验知识,如知识库来构造外部记忆库),只不过可以设计key和value;如果key和value相等,那么上述就退化成了Basic Attention的操作了。
Memory Network
首先是ICLR2015文章"Memory Network"。该模型的出发点在于,传统的深度学习模型(RNN、LSTM、GRU等)使用hidden states或者Attention机制作为他们的记忆功能(实际上是短期的内部记忆),但是这种方法产生的记忆太小了,无法精确记录一段话中所表达的全部内容,也就是在将输入编码成dense vectors的时候丢失了很多信息。所以本文就提出了一种可读写的「外部记忆模块」(external memory),并将其和inference组件联合训练,最终得到一个可以被灵活操作的记忆模块。
这篇文章的贡献在于提出了一种普适性的模型架构memory networks。其核心组件包括4部分:
简单来说,就是输入的文本经过Input模块编码成向量,然后将其作为Generalization模块的输入,该模块根据输入的向量对memory进行读写操作,即对记忆进行更新(最基本的更新就是将memory划分为slots,以slot为单位进行读写,更新的时候,最简单的方法就是 ,即新根据输入x进行Hash索引,然后替换掉某个Slot为最新的input的内部特征表示)。然后Output模块会根据Question(也会进过Input模块进行编码)对memory的内容进行权重处理(Question会触发对memory的Attention),将记忆按照与Question的相关程度进行组合得到输出向量,最终Response模块根据输出向量编码生成一个自然语言的答案出来。
End-To-End Memory Networks
接着是NIPS2015的文章“End-To-End Memory Networks”。作者的应用场景是问答系统(比较复杂的问答推理),包括3要素,input-question-answer。
首先介绍下语句表示组件(对应上篇论文的I组件)。语句表示组件的作用是将语句 表示成一个向量。作者在bag-of-words(BoW)基础上添加位置序列信息。令某个语句为为 。则语句向量化表示为:
其中, 看做是每个单词的embedding表示, 是根据「位置」计算的权重向量,称作position encoding。
是语句长度, 是单词序号, 代表 的第 个元素, 是Embedding的维度数( 维度数)。
此外,语句之间也存在时序关系,作者对语句之间的时序也进行了encoding,但是一笔带过。坐在在计算 和 时加了一个额外的叫做 temporal encoding的模型,。 是个矩阵,编码了时序信息,也是需要学习。当然,Position encoding和Temporal Encoding可以同时考虑。
下面要介绍的模型的memory input/output, question都需要利用该组件进行向量化表示,只不过Embedding矩阵不同。
首先给出模型架构图: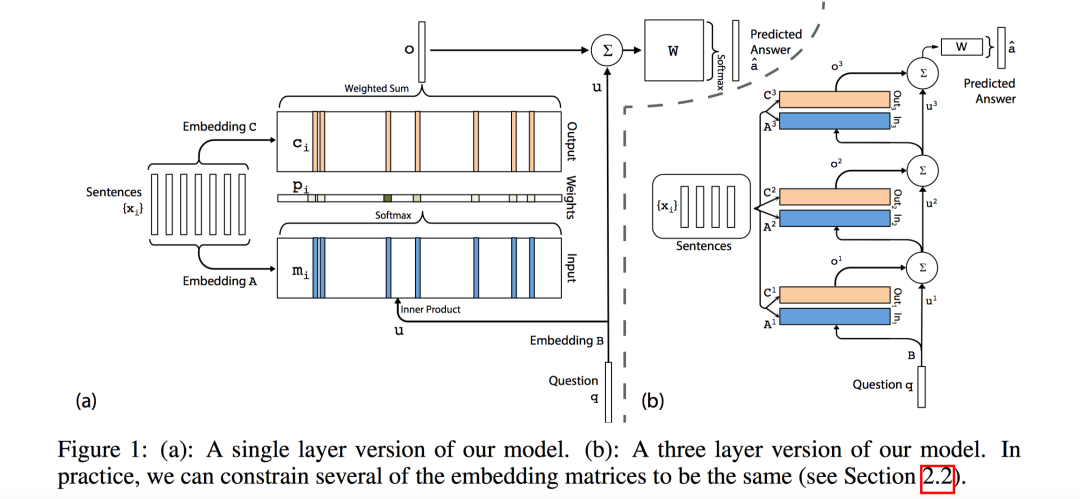
上图左侧(a)是单层的网络结构。最左边的就是memory,里面存储着输入集合 ,每个 代表一个句子。memory的输入和输出不同,按照我的理解memory的输入是key,输出是value。输入key用于计算和查询的相似性,输出value用于计算上下文向量。
对于输入记忆(可以理解为Key memory,记忆的一种表现形式),即图中下半部分蓝色线条,使用上述语句表示组件(Embedding A)将每个语句 转成向量表示 作为memory的输入(可以理解为 存储在memory中,不断写入memory直到fixed buffer size),即key,memory input用于得到memory不同语句的attention得分向量。首先将问题语句 也使用语句表示组件(Embedding B)转成向量化表示 ,即query,然后根据key和query和计算 ,这是address memory+normalize操作。
对于输出记忆(可以理解为Value memory,记忆的另一种表现形式),即图中上半部分黄色线条,首先根据语句表示组件(Embedding C)将语句转成 作为memory的输出,即value,然后利用该输出以及 ,加权得到attentional上下文向量,即:, 这是read contents操作。
最后预测的时候,将问题表示 和上下文向量 相加,经过Softmax全连接层预测答案的概率分布(文中似乎只针对单个单词的答案。对于多个单词的答案,会把答案句子看成一个整体,从多个候选的答案句子中选择其中一个),,其中,。 是词汇表所有词的概率,使用交叉熵损失进行训练。
上述是单层网络,作者将多个单层网络stack在一块,来解决多跳(Multi-Hop)操作(我的理解是每一跳都要和memory交互,形成更有用的记忆上下文向量 ,并不断更新查询语句表示 ,将注意力引导向正确的答案(查询表示向量基础上加上记忆上下文向量进行Transition,来引导到最佳答案位置),如上图(b)所示。
从图中可以看出,每经过一层都要和memory交互,且后一层的问题语句表示为,。为了减少参数量,作者对 ,, 矩阵做了限制,比如后一层的 为前一层的 ;最后的 是最后一层的 。
对于这里面memory的理解,我个人认为memory会使用所有的问答系统的输入语句经过语句表示模块后提取的特征表示来初始化。后面训练的时候,如果遇到的输入语句已经在memory中了,那么就直接替换其旧值来更新memory(embedding A矩阵训练过程中在更新,因此 也会相应的更新,同理memoy的输出 也可以更新)。如果memory的容量有限,那么先随机初始化满,后面训练的时候遇到不在memory的语句,再根据一定策略替换掉某个值(例如使用Hash策略或FIFO策略,文章没细说)。
Key-Value Memory Networks
接着是ACL2016文章,"Key-Value Memory Networks for Directly Reading Documents"。这篇文章在key和value上进一步解耦,并引入先验知识分别来设计key embedding和value embedding,也就是人工设计key的嵌入以更好的匹配问题,人工设计value的嵌入来更好的匹配答案。模型结构如下: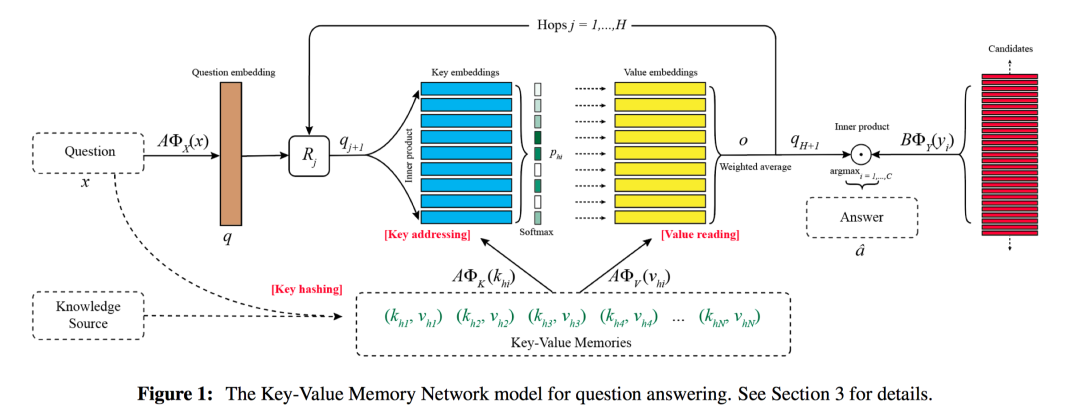
几乎一样,这里的Key Addressing就是Input Memory Addressing,Value Reading就是Output Memory Reading。核心的创新之处在于,
可以使用不同方式来映射不同的语句。Key, Value,Question,Answer,对应图中不同的 。最简单的映射方式就是Bag-of-words,作者对Question,Answer的处理就是用BoW。而对Key和Value的处理不同。 使用Knowledge base引入先验,来构建记忆;作者使用知识库的结构化三元组,subject relation object,即主谓宾。然后可以使用主语和谓语作为Key,宾语作为Value。作者把三元组写成被动语句,这样一条三元组有2种形式的(key, value)。举个例子:Blade Runner directed_by Ridley Scott / Ridley Scott !directed_by Blade Runner,对于前者Key是Blade Runner directed_by,Value是Ridley Scott;对于后者Key是Ridley Scott !directed_by,Value是Blade Runner。 Window-Level: 将文档切分成若干个windows,作者只保留中心位置是名词的windows,每个window由若干个词语构成。可以将整个window当做key来匹配问题,把中心位置名词当做value来匹配。
还有一个有趣的地方,之前的模型会限制记忆的大小,主要是因为不能保留所有的语句。这里为了解决大型记忆库的计算效率,提出了Key Hashing的概念。对于每个Question,Key Addressing过程中作者引入了Key Hashing,即可以从大型的记忆库中使用Hash索引检索出部分记忆,例如对应key里头至少有1个单词和Question相同的记忆,再根据部分记忆Address+Read。
Dynamic Memory Networks
最后是ICML2016的文章,“Ask Me Anything:Dynamic Memory Networks for Natural Language Processing“,采取了更复杂的动态记忆网络。前面两篇文章,都是使用Bag-of-Words提取语句向量化表示,这篇文章使用RNN来提取语句向量化表示。并且前面文章预测的答案一般只有1个单词,这里可以多个单词。
模型细分为Input Module,Question Module, Episodic Memory Module和Answer Module。模型结构如下: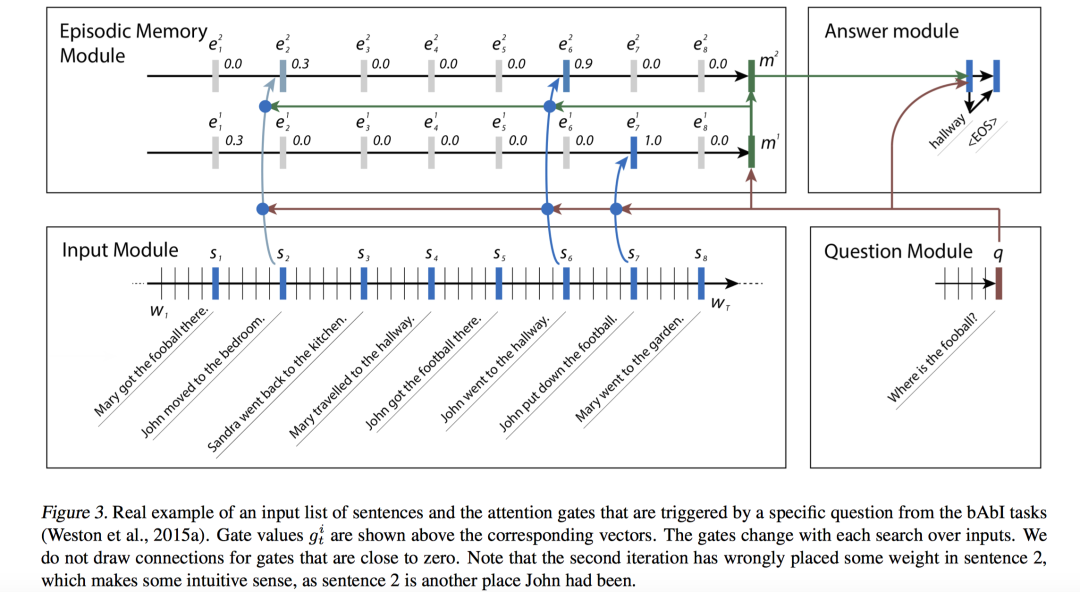
Input Module:对输入(语句,故事,文章,Wiki百科)使用GRU提取隐状态表示 。如果输入是一句话,那么提取到的隐状态个数等于单词个数(每个单词对应一个);如果输入是多个语句,那么提取的隐状态等于语句数(每个语句对应一个,训练时将所有语句concat在一起,语句之间添加特殊分割token,经过GRU后,保留每个token处提取到的隐状态表示,如图 , )。
Question Module:对问题使用GRU提取隐状态,不同的是只保留问题最后一个时刻得到的隐状态 。
Episodic Memory Module:本模块和Input Module是「对齐」的,对齐的目的是要计算Input不同Token的Attention Score值。该模块主要包含Attention机制、Memory更新机制两部分组成,每次迭代都会通过Attention机制对输入向量进行权重计算,然后生成新的记忆。第 次迭代过程中,
Episodic Memory Module场景向量 用于压缩和抽象输入序列,相当于将输入序列状态集合压缩并抽象成一个场景描述向量 ,这个场景描述向量是和「具体问题」以及「具体输入」都是相关的。为了计算场景向量,该模块维护了自己的隐状态 ,根据融合了Attention机制的第一个公式来计算;第二个公式表明,最后一个时刻得到的隐状态作为提取到的新场景 ;第三个公式再根据提取到的新场景和前一次迭代得到的记忆「更新记忆」。
上述过程,一般会经过多次迭代(可以理解为多跳),将最后一次迭代得到的强化的记忆作为下一个Answer Module的输入。
计算Attention Score。attention mechanism使用一个门控函数作为Attention。为了计算输入序列某个时刻的attention score,门控函数的输入是该时刻的输入序列提取的表示 ,前一次迭代的记忆 和问题 ,门控函数最终输出输入序列每个token(这里是每个句子)和该问题的相似性Attention score值 ,所有时刻的score构成Attention向量,记做 。 更新记忆(先计算新场景Episode,再计算新记忆Memory): Answer Module:采用GRU。将上述提取到的最后一次迭代的记忆 作为初始隐状态,问题 和前一时刻预测的输出 作为输入,得到当前时刻的隐状态 ,接一个softmax全连接层得到该时刻输出词的概率分布。
这篇文章的动态性我个人理解为,每输入一句话,记忆就会产生和更新,且这种记忆是Input-Level的,有点像短期的记忆(和Attention比较像,Attention也是Input-Level的短期内部记忆)。而之前3篇文章的工作,记忆库是初始的一次性读取所有输入并产生memory库,这个记忆库是Task-Level的,跟这个任务相关的数据都能用于构造该记忆库,只不过受限于容量,记忆库也需要辞旧迎新。不管如何,二者的记忆表示都需要在训练过程中不断更新。
另外,这篇文章的优点就是将Memory机制更好的应用到了Seq2Seq模型。前面的3篇工作都不是标准的Seq2Seq模型,都只是利用简单的Bag-of-Words来处理序列,预测的时候,答案要么是单个单词;要么是看成一个整体的句子。而本文则用GRU在Answer Module建模答案序列。
Self Attention
NIPS2017: Attention Is All You Need[5]
Google Brain团队在2017年提出了一种新的神经网络架构,称作Transformer。该架构只使用了attention机制(+MLPs),不需要RNN、CNN等复杂的神经网络架构,并行度高。
文章创新点包括:
提出了**(Multi-Head Attention)机制**,可以看成attention的ensemble版本,不同head学习不同位置不同的表示子空间的不同语义。 提出了「Self-Attention」,自己和自己做attention,使得每个位置的词都有全局的语义信息,有利于建立长依赖关系。这是因为Self-Attention是每个词和所有词都要计算 Attention,所以不管他们中间有多大距离,最大的路径长度也都只是 1,因此可以捕获长距离依赖关系。 Attention的「抽象」(应该也不算第一次在这篇文章中做的抽象):文章将Attention抽象成q(query)、k(key)、v(value)三者的函数。即,首先根据q和k计算attention分配情况,然后根据分配的权重,对v进行加权,最后得到上下文向量。做个类比,q就是Decoder端 时刻的隐状态,k就是Encoder端 时刻的隐状态,v也是Encoder端s时刻的隐状态,但是这里的k和v只需要一一对应即可,不需要完全相等,因此一种变体的话,v可以是 (加了个residual connection)
1. Encoder
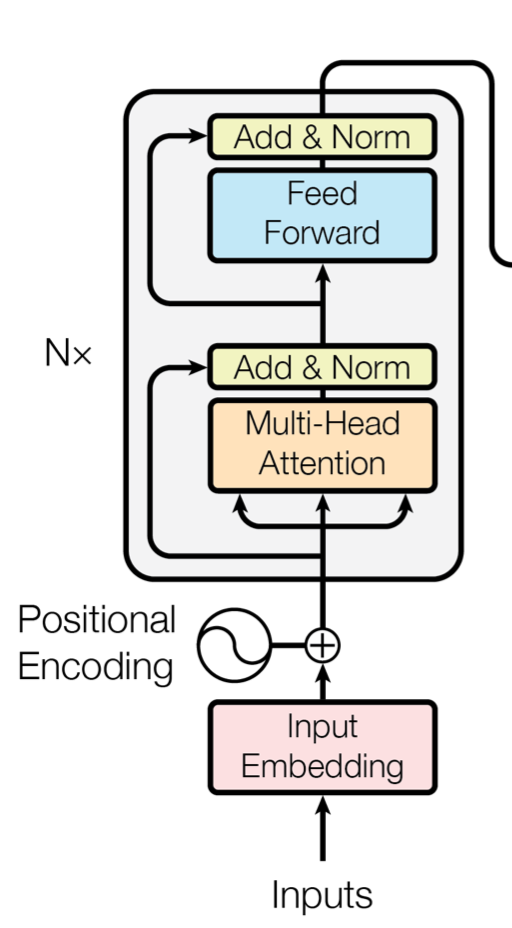
输入层:word embedding + position embedding。
word embedding是常规操作。这里的position embedding是因为不使用RNN的话,位置信息就不能间接利用了,因此需要显示的对position进行embedding表示,即给每个位置一个向量化表达。作者使用正弦和余弦函数,使得位置编码具有周期性,并且有很好的表示相对位置的关系的特性(对于任意的偏移量 , 可以由 线性表示),同时模型可以拓展到那些比训练集中最大长度还大的未知句子的position表示(关于pos的函数)。
其中,pos是位置编号, 为embedding的第 维。记:,其中, 是输入词的word embedding, 是输入词的position embedding, 是接下来Attention的输入。输入的序列长度是 ,embedding维度是 ,所以输入是 的矩阵 。
Attention层:N=6,6个重复一样的结构(可以看出这里也是使用了多跳),每种结构由两个子层组成:
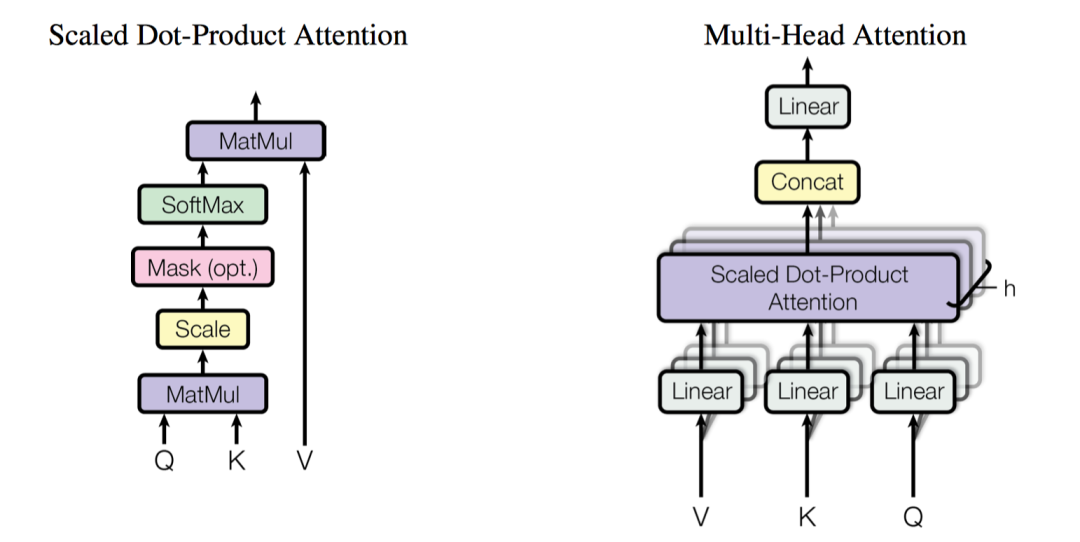
每个Head获取一种子空间的语义,多个Head可以看做是ensemble,且可以并行计算。对于一个Head,
a)首先,原始的 、、 先经过全连接进行线性变换映射成 。
b) 接着,将映射后的 输入到Scaled Dot-Product Attention,得到中间Attention值,记做,。对于 函数,先计算 和 点乘相似性,并使用 缩放,然后经过softmax激活后得到权重分布,最后再对 加权,即:
c) 然后,将所有的中间Attention值concat在一起 ,
d) 最后,再经过一个线性映射 ,得到最终输出的Multi-Head Attention值,,其捕获了不同表示子空间的语义。
综合起来,即:
子层1:「Multi-Head self-attention」
源语句的self attention。Multi-Head Attention如下图右边所示,每个Multi-Head Attention包含了 个Scaled Dot-Product Attention组件,也就是每个Head就是一个Scaled Dot-Product Attention组件,如下图左边所示。
子层1的输出:,此时 。
子层2:
position-wise 前馈神经网络。即上述输出的矩阵每一行代表相应位置的单词经过attention后的表示,每个位置的向量 经过两层的前馈神经网络(中间接RELU激活)得到一个输出FFN。
上述参数所有位置共享,。
子层2的输出:
2. Decoder
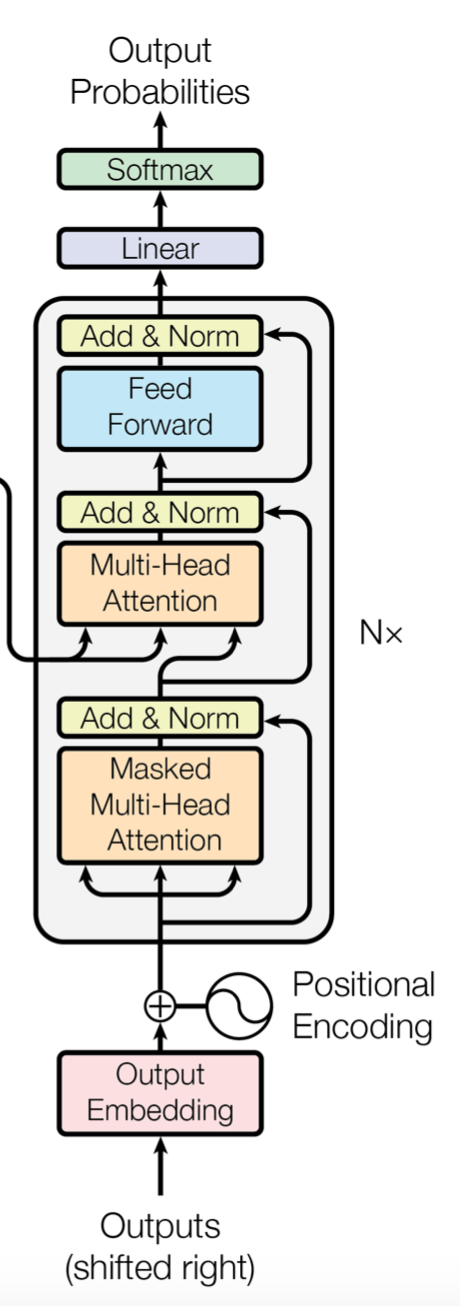
输入层:
「已经翻译出的」目标词word embedding+position embedding。结构同encoder中的输入层,每个单词embedding维度为 ,假设已经翻译了 个词,则输入为矩阵 。
Attention层:共6个。
子层1:Masked Multi-Head Self-Attention
目标语句的self-attention,加了掩码的multi-head attention,防止目标语句中前面的单词attend到后面的单词,来维护自回归的性质。这和Encoder中不同,Encoder中没有加该限制。具体实现时,只需要在scaled dot-product Attention中,将softmax的输入中不合法的attend连接设置成无穷小即可(这样经过softmax后这些权重为0)。
该层的输出同样采取Add和LayerNorm。
子层2:Multi-Head Attention
前面两次用到的Multi-Head Attention都是源语句或目标语句各自内部的Attention。而该子层2是目标语句和源语句之间的Attention。此时, 是Decoder端的单词表示,即上述Masked Multi-Head Self-Attention得到的输出,, 是Encoder端的输出,即前文所述的 。
该子层允许目标语句每个词都能attend到源语句不同的单词上,且每个目标单词都能计算一个对应的上下文向量。该子层的输出 。
子层3:Position wise 前馈神经网络
和Encoder中的一致。输出 。
输出层:
将上述依次经过6个Attention层的输出经过一个全连接层并softmax激活后得到下一个预测的单词的概率分布。
另外,Transformer比较好的文章可以参考以下两篇文章:
一个是Jay Alammar可视化地介绍Transformer的博客文章The Illustrated Transformer[6] ,非常容易理解整个机制; 然后可以参考哈佛大学NLP研究组写的“The Annotated Transformer[7] ”,代码原理双管齐下,很细致。
总之,这篇文章中提出的Transformer本质上是个叠加的自注意力机制够成的深度网络,是非常强大的「特征提取器」,尤其是在NLP领域。Transformer近几年也一跃成为踢开RNN和CNN传统特征提取器,荣升头牌,大红大紫。很多后续的NLP先进的研究工作都会基于Transformer展开。例如,词预训练工作上,18年OpenAI工作:Improving Language Understanding by Generative Pre-Training[8](GPT)和 18年Google AI Language工作:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[9] (BERT),这两个重要工作都是基于Transformer特征提取器做的,其提出的两阶段训练方式(pre-training+fine-tuning)做迁移学习几乎刷爆了所有的NLP任务。
Summary
本文主要对基本的Attention机制以及Attention的变体方面的工作进行了梳理。我们不难发现Attention机制简单,优雅,效果好,沟通了输入和输出之间的联系,易于推广和应用到多种多样的任务和场景中,如计算机视觉,NLP,推荐系统,搜索引擎等等。
除此之外,我们可以回顾下早期的一些奠基性的工作,注意力机制的好处在于很容易融入到其他早期的一些工作当中,来进一步提升早期成果,例如,将注意力机制引入到早期词预训练过程中,作为特征提取器,来提升预训练的效果,这在今年NLP工作中尤为突出(e.g.,BERT)。还比如,可以将注意力机制用于模型融合;或者将注意力机制引入到门限函数的设计中(e.g.,GRU中代替遗忘门等)。
总之,Attention机制的易用性和有效性,使得很容易引入到现有的很多工作中,也很容易的应用到各种各样的实际业务或场景当中。另外Attention的改进工作包括了,覆盖率(解决重复或丢失信息的问题),引入马尔科夫性质(前一时刻Attention会影响下一时刻的Attention,实际上多跳注意力能够解决该问题),引入监督学习(例如手动对齐或引入预训练好的强有力的对齐模型来解决Attention未对齐问题)等等。
本文参考资料
ICLR 2015:Memory Networks: https://arxiv.org/pdf/1410.3916.pdf
[2]NIPS2015:End-To-End Memory Networks: https://arxiv.org/pdf/1503.08895.pdf
[3]ACL2016:Key-Value Memory Networks for Directly Reading Documents: https://arxiv.org/pdf/1606.03126.pdf
[4]ICML2016:Ask Me Anything:Dynamic Memory Networks for Natural Language Processing: https://arxiv.org/pdf/1506.07285.pdf
[5]NIPS2017: Attention Is All You Need: https://arxiv.org/pdf/1706.03762.pdf
[6]The Illustrated Transformer: https://jalammar.github.io/illustrated-transformer/
[7]The Annotated Transformer: http://nlp.seas.harvard.edu/2018/04/03/attention.html
[8]Improving Language Understanding by Generative Pre-Training: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
[9]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding: https://arxiv.org/pdf/1810.04805.pdf
- END -

往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: