
ICCV 2021 | 简而优:用分类器变换器进行小样本语义分割
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者 | 卢治合
编辑 | 王晔
本文是对发表于计算机视觉领域的顶级会议 ICCV 2021的论文“Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer(简而优:用分类器变换器进行小样本语义分割)”的解读。
该论文由英国萨里大学Centre for Vision, Speech and Signal Processing (CVSSP)发表,针对小样本语义分割问题,提出一种更加简洁的元学习范式,即只对分类器进行元学习,对特征编码解码器采用常规分割模型训练方式。元学习训练后的Classifier Weight Transformer使分类器可以动态地适应测试样本,从而提高分割准确率。
论文:https://arxiv.org/pdf/2108.03032.pdf
背景
得益于大型的标签数据和深度学习算法的发展,语义分割方法近几年取得了很大的进步。但这些方法有两个局限:
1)过度依赖带标签数据,而这些数据的获得通常消耗大量人力物力;
2)训练好的模型并不能处理训练过程中未见的新类别。
面对这些局限,小样本语义分割被提出来,它的目的是通过对少量样本的学习来分割新类别。一般来说,小样本语义分割方法是通过用训练数据模拟测试环境进行元学习使得训练的模型有很好的泛化能力,从而在测试时可以仅仅利用几个样本的信息来迭代模型完成对新类别的分割。具体地,小样本分割模型是在大量的模拟任务上进行训练,每个模拟任务有两个数据组:Support set and Query set。Support set 是有标签的K-shot样本,而Query set只在训练的时候有标签。这样的模拟任务可以有效地模拟测试环境。
方法
一个小样本分类系统一般由三部分构成:编码器,解码器和分类器。其中,前两个模块模型比较复杂,最后一个分类器结构简单。我们发现现存的小样本分类方法通常在元学习的过程中更新所有模块或者除编码器外的模块,而所利用更新模块的数据仅仅有几个样本。在这样的情况下,我们认为模型更新的参数量相比于数据提供的信息量过多,从而不足以优化模型参数。基于此分析,我们提出了一个全新的元学习训练范式,即只对分类器进行元学习。为了方便读者更好的理解,我们给出了两种方式的对比,如图1。
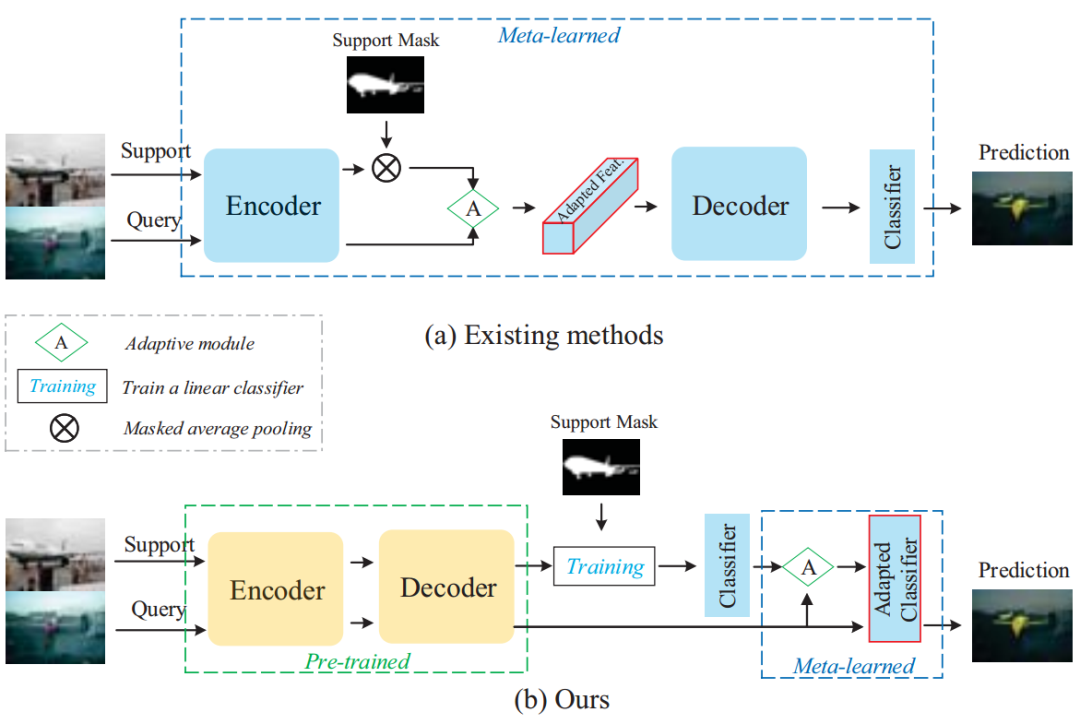
具体地,我们采用常规的分割方法对编码器和解码器进行训练,训练后在元学习的过程中不在更新。这是基于我们的假设:在大量标签数据训练下的模型可以提取有辨别性的特征,对一些新类别也有效,这也可以解释很多方法直接使用ImageNet预训练的模型进行特征提取。在分析数据的时候,我们发现Support set和Query set的数据有时有较大的类内差异,如图2。同样的类别,不同的角度即可产生很大的区别。这就使得利用Support set迭代的模型不能很好地作用在Query set上。

为了解决这个问题,我们提出了Classifier Weight Transformer来动态地利用Query set的特征信息来进一步更新分类器模块,从而提升分割任务性能。我们的模型框架如图3。
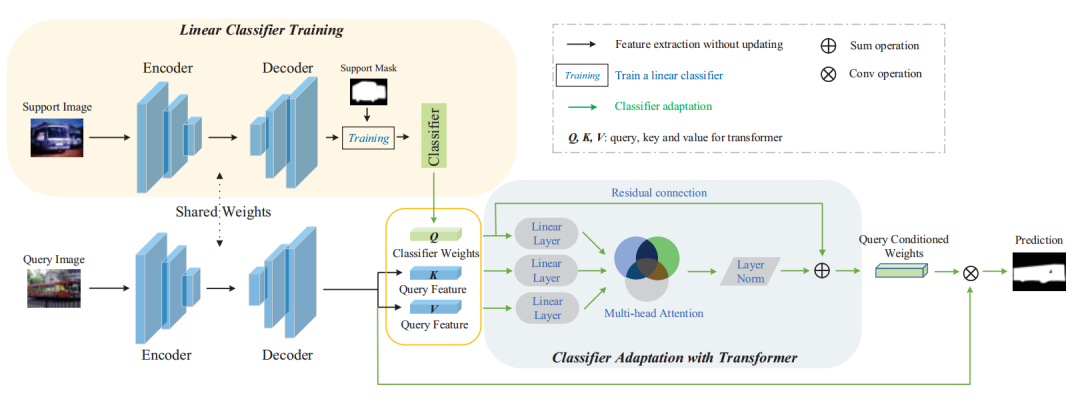
具体的算法细节请参考原文。
实验
在两个标准小样本分割数据集PASCAL和COCO上,我们的方法在大多数情况下取得了最优的结果。
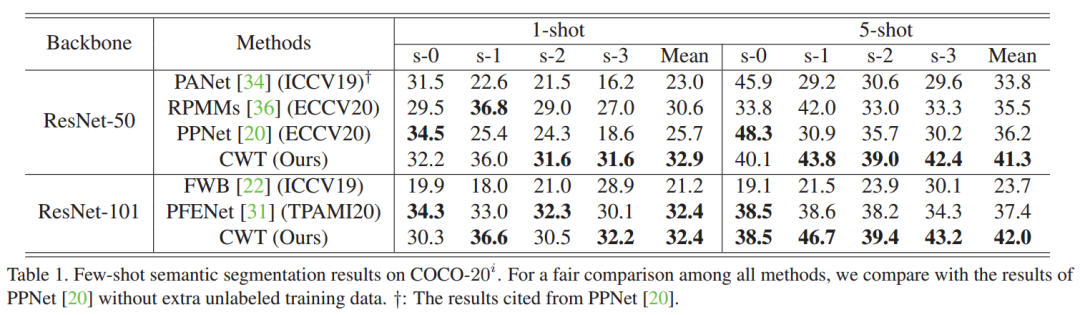
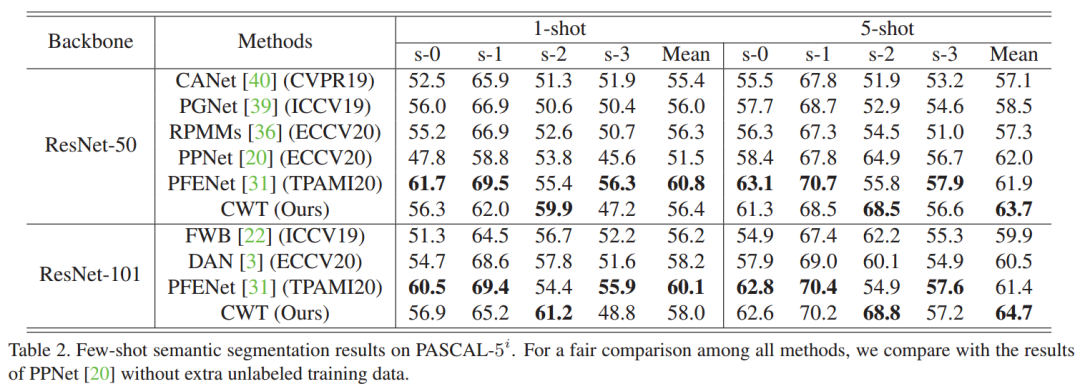
此外,我们在一种跨数据集的情景下测试了我们模型的性能,可以看出我们的方法展示了很好的鲁棒性。

可视化结果也进一步支持我们的实验结果。

更多的对比结果请参考文章。
结语
我们提出了一种新的元学习训练范式来解决小样本语义分割问题。相比于现有的方法,这种方法更加简洁有效,只对分类器进行元学习。为了解决类内差异问题,我们提出Classifier Weight Transformer来利用Query特征信息来迭代分类器,从而获得更加鲁棒的分割效果。通过大量的实验,我们证明了方法的有效性。

点个在看 paper不断!