
收藏:大规模RDMA技术实践
近期打算提纲挈领地整理一下工业界已经使用起来或有潜力使用起来的大规模RDMA相关技术,供大家参考,也为自己梳理一下脉络。里面每一章甚至每一节的内容都可以单独写成一篇文章,待后续点赞情况和评论情况再进行更新,也欢迎学界和业界的各位同行朋友批评指正,多提宝贵意见。注:此技术杂谈面向有一定网络和系统基础的同学。
作者简介:

2.1 RDMA拥塞控制算法
DCQCN算法:目前Mellanox网卡支持的主要拥塞控制算法,由微软和Mellanox联合研发,在交换机上以ECN为拥塞标记信号,发送者在主机网卡侧根据ECN标记情况来推测网络拥塞情况,实现了一种基于速率(rate-based)的调速方法,是目前Mellanox RDMA网卡商业上直接可用、使用最为广泛的拥塞控制算法。算法主要思想参考Congestion Control for Large-Scale RDMA Deployments,SIGCOMM 2015
TIMELY和Swift算法:Google数据中心中使用的拥塞控制算法,交换机不需要做额外的支持,发送者在主机网卡上对端到端往返延迟(RTT)进行测量,基于RTT的变化进行梯度计算,进而根据梯度实现了基于速率(rate-based)的调速方法。目前主要是在Google内部使用,依赖于Google的自研网卡。算法思想参考TIMELY: RTT-based Congestion Control for the Datacenter,SIGCOMM 2016和Swift: Delay is Simple and Effective for Congestion Control in the Datacenter,SIGCOMM 2020 HPCC算法:阿里网络研究团队研发出的拥塞控制算法,使用INT携带网络拥塞情况,发送者在主机网卡侧实现了一种基于窗口(window-based)的调速方法。受限于INT的精度、网卡实现的复杂性和对可编程交换机的依赖,HPCC目前应该只是停留在论文阶段,未有大规模部署。算法思想参考HPCC: High Precision Congestion Control,SIGCOMM 2019 其他网卡的算法:Broadcom RDMA网卡上拥塞控制算法采取了类似于DCTCP算法的变种,算法具体可以参考Data Center TCP (DCTCP),SIGCOMM,这里不再详细描述。
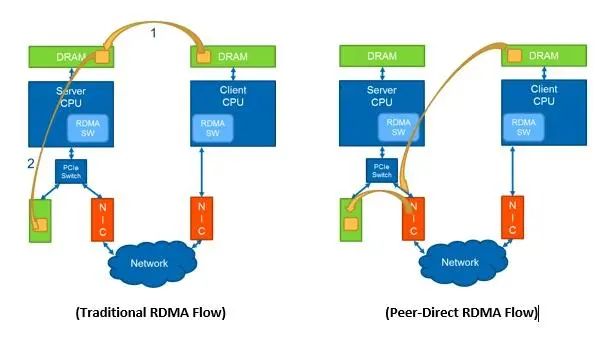
2.2 无损网络(Lossless)到有损网络(Lossy)的演进
2.3 RDMA多路径传输
采取Multi-path RDMA的思路,即以数据包为粒度把一个流分散到多个等价路径上,再在网卡硬件上实现大部分的Multi-path传输层逻辑,如拥塞感知的流量切分、解决接收端乱序等问题。具体思想参考微软亚研院的工作Multi-Path Transport for RDMA in Datacenters,NSDI 2018 仍然是采用把一个流分散到多个等价路径上,形成多个subflow(e.g., flowlet, flowcell),来实现更好的均衡性进而提高多链路的利用率。但是,这里不再在接收端的硬件网卡上解决乱序(out-of-order)问题,而是把这一功能放到软件层,如网卡驱动或者通讯库里面,具体思想参考亚马逊的SRD。 根据业务场景特性和流量模型特性,进行智能路由选路。如在AI训练的场景中,由于流量模型具有所有流大小相同、同时发起同时结束的属性,可以采用类似阿里ACCL的思路,进行基于源端口的有序规划,实现基于探测的拥塞感知的路由控制算法。
4.1 RDMA在机器学习训练领域的应用
Google:github.com/google/nccl- Microsoft:github.com/microsoft/ms facebook:github.com/facebookincu AWS:github.com/aws/aws-ofi- 华为:HCCL - Atlas Data Center Solution V100R020C00 中心训练解决方案概述 01 - 华为 阿里巴巴:ACCL
4.2 RDMA在存储领域的应用
4.3 在AI、存储等业务场景充分发挥RDMA潜力的小tips
Using RDMA Efficiently for Key-Value Services,SIGCOMM 2014,如何根据key-value store的特性更加合理地使用RDMA原语,让其在RDMA网络上能降低延迟和提高吞吐 FaRM: Fast Remote Memory,NSDI 2014 Fast In-memory Transaction Processing using RDMA and HTM,SOSP 2015 未完待补充...
5.1 RDMA性能优化
网卡承载了RDMA功能里面最复杂的部分,包括RDMA verbs、rkey校验、地址映射、RDMA传输层协议(go-back-N,congestion control);而交换机的功能则相对简单(PFC、ECN) 网卡上的资源非常受限,需要使用服务器的DRAM来存储它的数据结构,而只是用自己的本地DRAM作为cache;而cache管理非常复杂,经常会引入性能问题(e.g.,cache换入换出引发slow-receiver symptom)
5.2 RDMA监控和运维
7.1 微软的RDMA部署经验
7.2 阿里巴巴的RDMA在存储业务上的部署经验
下载链接:
来源:全栈云技术架构,加入全栈云技术知识星球下载全部资料。
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。

评论