
vivo大规模 Kubernetes 集群自动化运维实践
作者:vivo 互联网服务器团队-Zhang Rong
一、背景
随着vivo业务迁移到k8s的增长,我们需要将k8s部署到多个数据中心。如何高效、可靠的在数据中心管理多个大规模的k8s集群是我们面临的关键挑战。kubernetes的节点需要对os、docker、etcd、k8s、cni和网络插件的安装和配置,维护这些依赖关系繁琐又容易出错。
以前集群的部署和扩缩容主要通过ansible编排任务,黑屏化操作、配置集群的inventory和vars执行ansible playbook。集群运维的主要困难点如下:
需要人工黑屏化集群运维操作,存在操作失误和集群配置差异。
部署脚本工具没有具体的版本控制,不利于集群的升级和配置变更。
部署脚本上线需要花费大量的时间验证,没有具体的测试用例和CI验证。
ansible任务没有拆分为模块化安装,应该化整为零。具体到k8s、etcd、addons的等角色的模块化管理,可以单独执行ansible任务。
主要是通过二进制部署,需要自己维护一套集群管理体系。部署流程繁琐,效率较低。
组件的参数管理比较混乱,通过命令行指定参数。k8s的组件最多有100以上的参数配置。每个大版本的迭代都在变化。
本文将分享我们开发的Kubernetes-Operator,采用K8s的声明式API设计,可以让集群管理员和Kubernetes-Operator的CR资源进行交互,以简化、降低任务风险性。只需要一个集群管理员就可以维护成千上万个k8s节点。
二、集群部署实践
2.1 集群部署介绍
主要基于ansible定义的OS、docker、etcd、k8s和addons等集群部署任务。
主要流程如下:
Bootstrap OS
Preinstall step
Install Docker
Install etcd
Install Kubernetes Master
Install Kubernetes node
Configure network plugin
Install Addons
Postinstall setup
上面看到是集群一键部署关键流程。当在多个数据中心部署完k8s集群后,比如集群组件的安全漏洞、新功能的上线、组件的升级等对线上集群进行变更时,需要小心谨慎的去处理。我们做到了化整为零,对单个模块去处理。避免全量的去执行ansible脚本,增加维护的难度。针对如docker、etcd、k8s、network-plugin和addons的模块化管理和运维,需提供单独的ansible脚本入口,更加精细的运维操作,覆盖到集群大部分的生命周期管理。同时kubernetes-operator的api设计的时候可以方便选择对应操作yml去执行操作。
集群部署优化操作如下:
(1)k8s的组件参数管理通过
ConmponentConfig[1]提供的API去标识配置文件。
【可维护性】当组件参数超过50个以上时配置变得难以管理。
【可升级性】对于升级,版本化配置的参数更容易管理。因为社区一个大版本的参数没有变化。
【可编程性】可以对组件(JSON/YAML)对象的模板进行修补。如果你启用动态kubelet配置选项,修改参数会自动生效,不需要重启服务。
【可配置性】许多类型的配置不能表示为key-value形式。
(2)计划切换到kubeadm部署
使用kubeadm对k8s集群的生命周期管理,减少自身维护集群的成本。
使用kubeadm的证书管理,如证书上传到secret里减少证书在主机拷贝的时间消耗和重新生成证书功能等。
使用kubeadm的kubeconfig生成admin kubeconfig文件。
kubeadm其它功能如image管理、配置中心upload-config、自动给控制节点打标签和污点等。
安装coredns和kube-proxy addons。
(3)ansible使用规范
使用ansible自带模块处理部署逻辑。
避免使用hostvars。
避免使用delegate_to。
启用–limit 模式。
等等。
2.2 CI 矩阵测试
部署出来的集群,需要进行大量的场景测试和模拟。保证线上环境变更的可靠性和稳定性。
CI矩阵部分测试案例如下。
(1)语法测试:
ansible-lint
shellcheck
yamllint
syntax-check
pep8
(2)集群部署测试:
部署集群
扩缩容控制节点、计算节点、etcd
升级集群
etcd、docker、k8s和addons参数变更等
(3)性能和功能测试:
检查kube-apiserver是否正常工作
检查节点之间网络是否正常
检查计算节点是否正常
k8s e2e测试
k8s conformance 测试
其他测试
这里利用了GitLab、gitlab-runner[2]、ansible和kubevirt[3]等开源软件构建了CI流程。
详细的部署步骤如下:
在k8s集群部署gitlab-runner,并对接GitLab仓库。
在k8s集群部署Containerized-Data-Importer (CDI)[4]组件,用于创建pvc的存储虚拟机的映像文件。
在k8s集群部署kubevirt,用于创建虚拟机。
在代码仓库编写gitlab-ci.yaml[5], 规划集群测试矩阵。
如上图所示,当开发人员在GitLab提交PR时会触发一系列操作。这里主要展示了创建虚拟机和集群部署。其实在我们的集群还部署了语法检查和性能测试gitlab-runner,通过这些gitlab-runner创建CI的job去执行CI流程。
具体CI流程如下:
开发人员提交PR。
触发CI自动进行ansible语法检查。
执行ansible脚本去创建namespace,pvc和kubevirt的虚拟机模板,最终虚拟机在k8s上运行。这里主要用到ansible的k8s模块[6]去管理这些资源的创建和销毁。
调用ansible脚本去部署k8s集群。
集群部署完进行功能验证和性能测试等。
销毁kubevirt、pvc等资源。即删除虚拟机,释放资源。
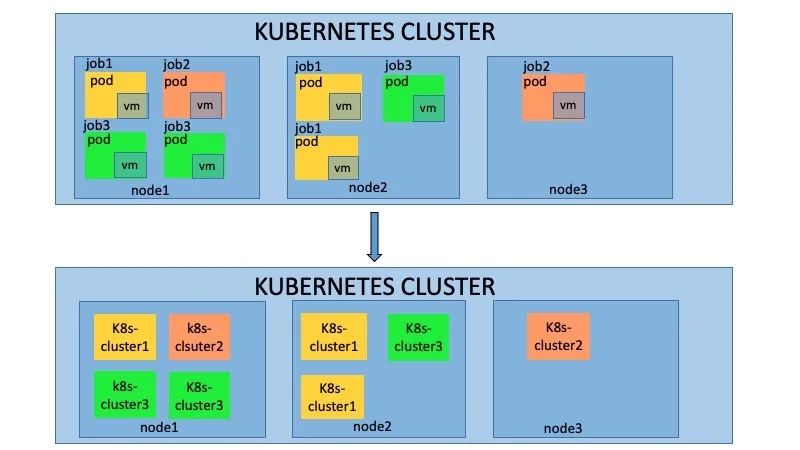
如上图所示,当开发人员提交多个PR时,会在k8s集群中创建多个job,每个job都会执行上述的CI测试,互相不会产生影响。这种主要使用kubevirt的能力,实现了k8s on k8s的架构。
kubevirt主要能力如下:
提供标准的K8s API,通过ansible的k8s模块就可以管理这些资源的生命周期。
复用了k8s的调度能力,对资源进行了管控。
复用了k8s的网络能力,以namespace隔离,每个集群网络互相不影响。
三、Kubernetes-Operator 实践
3.1 Operator 介绍
Operator是一种用于特定应用的控制器,可以扩展 K8s API的功能,来代表k8s的用户创建、配置和管理复杂应用的实例。基于k8s的资源和控制器概念构建,又涵盖了特定领域或应用本身的知识。用于实现其所管理的应用生命周期的自动化。
总结 Operator功能如下:
kubernetes controller
部署或者管理一个应用,如数据库、etcd等
用户自定义的应用生命周期管理
部署
升级
扩缩容
备份
自我修复
等等
3.2 Kubernetes-Operator CR 介绍
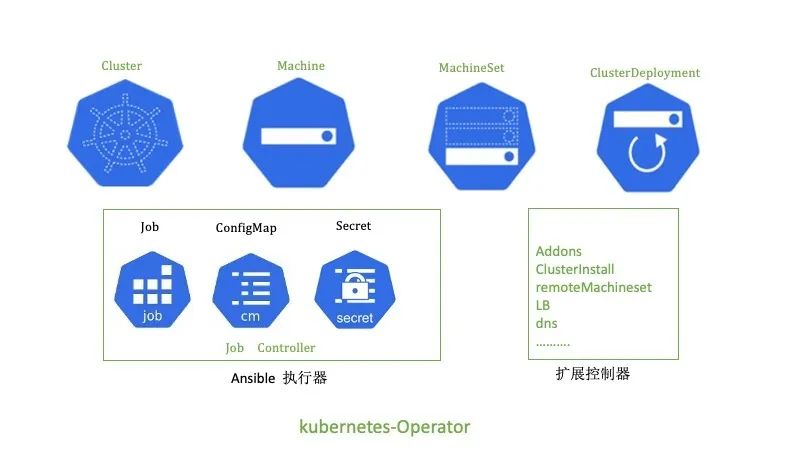
kubernetes-operator的使用很多自定义的CR资源和控制器,这里简单的介绍功能和作用。
【ClusterDeployment】: 管理员配置的唯一的CR,其中MachineSet、Machine和Cluster它的子资源或者关联资源。ClusterDeployment是所有的配置参数入口,定义了如etcd、k8s、lb、集群版本、网路和addons等所有配置。
【MachineSet】:集群角色的集合包括控制节点、计算节点和etcd的配置和执行状态。
【Machine】:每台机器的具体信息,包括所属的角色、节点本身信息和执行的状态。
【Cluster】:和ClusterDeployment对应,它的status定义为subresource,减少
clusterDeployment的触发压力。主要用于存储ansible执行器执行脚本的状态。
【ansible执行器】:主要包括k8s自身的job、configMap、Secret和自研的job控制器。其中job主要用来执行ansible的脚本,因为k8s的job的状态有成功和失败,这样job 控制器很好观察到ansible执行的成功或者失败,同时也可以通过job对应pod日志去查看ansible的执行详细流程。configmap主要用于存储ansible执行时依赖的inventory和变量,挂在到job上。secret主要存储登陆主机的密钥,也是挂载到job上。
【扩展控制器】:主要用于扩展集群管理的功能的附加控制器,在部署kubernetes-operator我们做了定制,可以选择自己需要的扩展控制器。比如addons控制器主要负责addon插件的安装和管理。clusterinstall主要生成ansible执行器。remoteMachineSet用于多集群管理,同步元数据集群和业务集群的machine状态。还有其它的如对接公有云、dns、lb等控制器。
3.3 Kubernetes-Operator 架构
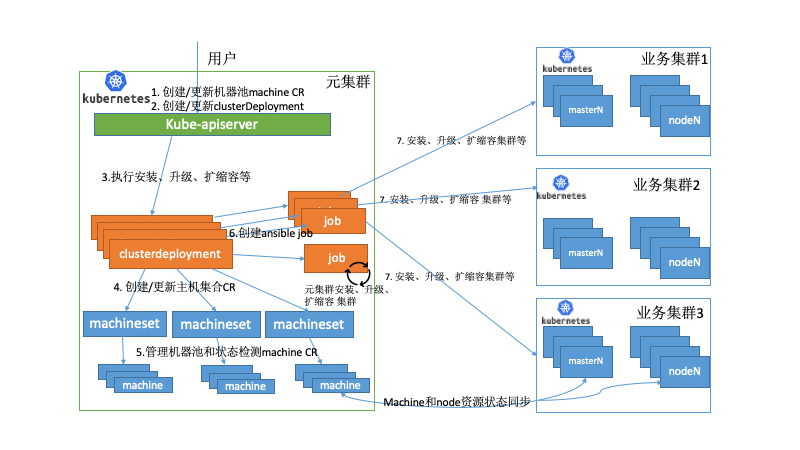
vivo的应用分布在数据中心的多个k8s集群上,提供了具有集中式多云管理、统一调度、高可用性、故障恢复等关键特性。主要搭建了一个元数据集群的pass平台去管理多个业务k8s集群。在众多关键组件中,其中kubernetes-operator就部署在元数据集群中,同时单独运行了machine控制器去管理物理资源。
下面举例部分场景如下:
场景一:
当大量应用迁移到kubernets上,管理员评估需要扩容集群。首先需要审批物理资源并通过pass平台生成对应machine的CR资源,此时的物理机处于备机池里,machine CR的状态为空闲状态。当管理员创建ClusterDeploment时所属的MachineSet会去关联空闲状态的machine,拿到空闲的machine资源,我们就可以观测到当前需要操作机器的IP地址生成对应的inventory和变量,并创建configmap并挂载给job。执行扩容的ansible脚本,如果job成功执行完会去更新machine的状态为deployed。同时跨集群同步node的控制器会检查当前的扩容的node是否为ready,如果为ready,会更新当前的machine为Ready状态,才完成整个扩容流程。
场景二:
当其中一个业务集群出现故障,无法提供服务,触发故障恢复流程,走统一资源调度。同时业务的策略是分配在多个业务集群,同时配置了一个备用集群,并没有在备用集群上分配实例,备用集群并不实际存在。
有如下2种情况:
其它的业务集群可以承载故障集群的业务,kubernetes-operator不需要执行任何操作。
如果其他业务集群不能承载故障集群的业务。容器平台开始预估资源,调用kubernetes-operator创建集群,即创建
clusterDeployment从备机池里选择物理机器,观测到当前需要操作机器的IP地址生成对应的inventory和变量,创建configmap并挂载给job。执行集群安装的ansible脚本, 集群正常部署完成后开始业务的迁移。
3.4 Kubernetes-Operator 执行流程
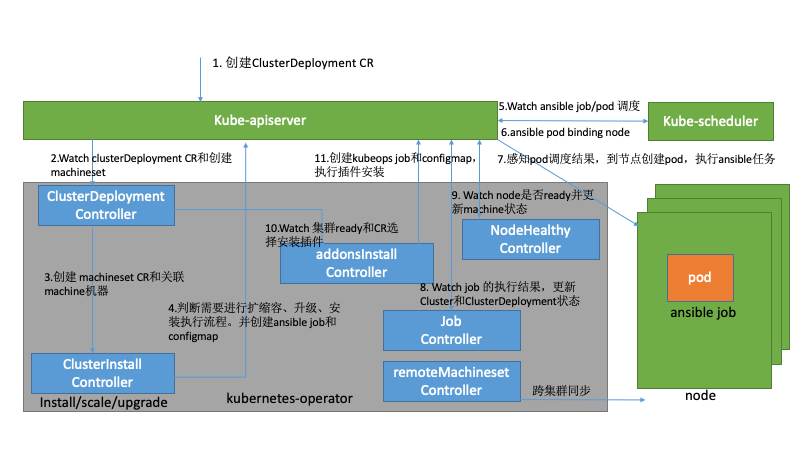
集群管理员或者容器平台触发创建ClusterDeployment的CR,去定义当前集群的操作。
ClusterDeployment控制器感知到变化进入控制器。
开始创建machineSet和关联machine 资源。
ClusterInstall 控制器感知ClusterDeployment和Machineset的变化,开始统计machine资源,创建configmap和job,参数指定操作的ansible yml入口,执行扩缩容、升级和安装等操作。
调度器感知到job创建的pod资源,进行调度。
调度器调用k8s客户端更新pod的binding资源。
kubelet感知到pod的调度结果,创建pod开始执行ansible playbook。
job controller感知job的执行状态,更新ClusterDeployment状态。一般策略下job controller会去清理configmap和job资源。
NodeHealthy感知k8s的node是否为ready,并同步machine的状态。
addons 控制器感知集群是否ready,如果为ready去执行相关的addons插件的安装和升级。
四、总结
vivo大规模的K8s集群运维实践中,从底层的集群部署工具的优化,到大量的CI矩阵测试保证了我们线上集群运维的安全和稳定性。采用了K8s托管K8s的方式来自动化管理集群(K8s as a service),当operator检测当前的集群状态,判断是否与目标一致,出现不一致时,operator会发起具体的操作流程,驱动整个集群达到目标状态。
当前vivo的应用主要分布在自建的数据中心的多个K8s集群中,随着应用的不断的增长和复杂的业务场景,需要提供跨自建机房和云的多个K8s集群去运行原云生的应用程序。就需要Kubernetes-Operator提供对接公有云基础设施、apiserver的负载均衡、网络、dns和Cloud Provider 等。需要后续不断完善,降低K8s集群的运维难度。