
CVPR2021 | SETR: 使用 Transformer 从序列到序列的角度重新思考语义分割
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
前言 本文介绍了一篇CVPR2021的语义分割论文,论文将语义分割视为序列到序列的预测任务,基于transformer作为编码器,介绍了三种解码器方式,选择其中效果最好的解码器方式与transformer编码器组成了一个新的SOTA模型--SETR。
论文:Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
代码:https://fudan-zvg.github.io/SETR
创新思路
现有的语义分割模型基本都基于FCN,FCN是由编码器和解码器组成的架构。编码器用于特征表示学习,而解码器用于对编码器产生的特征表示进行像素级分类。在这两者中,特征表示学习(即编码器)可以说是最重要的模型组件。与大多数其他为图像理解而设计的 CNN 一样,编码器由堆叠的卷积层组成。由于对计算成本的关注,特征图的分辨率逐渐降低,因此编码器能够学习更多抽象/语义视觉概念,感受野逐渐增加。
然而,编码器有一个基本限制,即学习远程依赖信息对于无约束场景图像中的语义分割至关重要,由于仍然有限的感受野而变得具有挑战性。
为了克服上述限制,最近引入了许多方法。一种方法是直接操纵卷积操作。这包括大内核大小、多孔卷积和图像/特征金字塔。另一种方法是将注意力模块集成到 FCN 架构中。这样的模块旨在对特征图中所有像素的全局交互进行建模。当应用于语义分割时,一个常见的设计是将注意力模块与 FCN 架构相结合,注意力层位于顶部。无论采用哪种方法,标准编码器解码器 FCN 模型架构都保持不变。最近,已经尝试完全摆脱卷积并部署注意力模型。
最近,一些SOTA方法表明将 FCN 与注意力机制相结合是学习远程上下文信息的更有效策略。这些方法将注意力学习限制在更小的输入尺寸的更高层,因为它的复杂度是特征张量的像素数的平方。这意味着缺乏对较低级别特征张量的依赖学习,导致次优表示学习。
为了克服这个限制,论文旨在重新思考语义分割模型设计并贡献一个替代方案,用纯transformer代替基于堆叠卷积层的编码器,逐渐降低空间分辨率,从而产生一种新的分割模型,称为 SEgmentation TRansformer (SETR)。这种单独的transformer编码器将输入图像视为由学习的补丁嵌入表示的图像补丁序列,并使用全局自注意力模型转换该序列以进行判别特征表示学习。
Methods
Segmentation transformers (SETR)
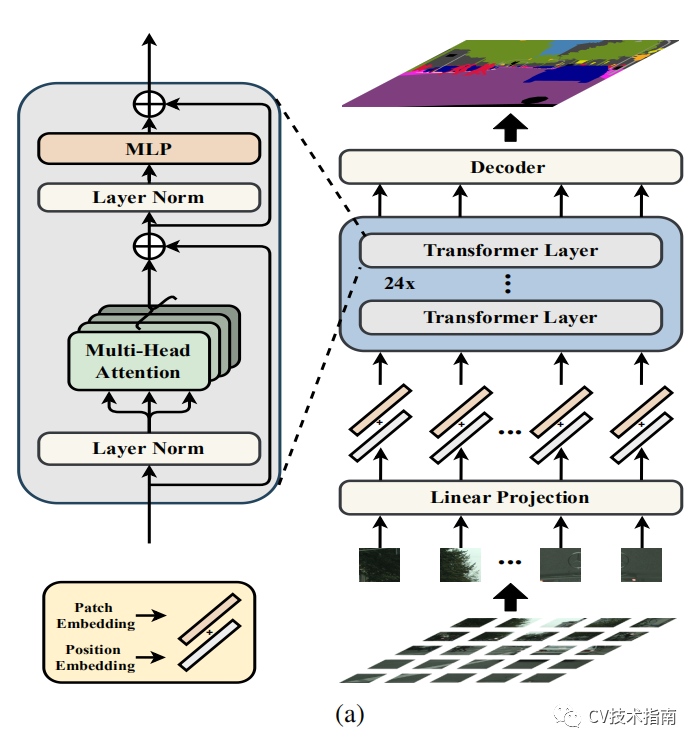
首先将图像分解为固定大小的补丁网格,形成补丁序列。将线性嵌入层应用于每个补丁的扁平像素向量,然后获得一系列特征嵌入向量作为transformer的输入。给定从编码器transformer学习的特征,然后使用解码器来恢复原始图像分辨率。至关重要的是,编码器transformer的每一层都没有空间分辨率的下采样,而是全局上下文建模,从而为语义分割问题提供了一个全新的视角。
Image to sequence
此处没什么创新,将图像分成16块,每块通过flatten操作变成向量,向量的长度为HW/16,分块的目的是为了缩小向量的长度,否则计算量太大。为了学习到像素之间的空间信息,将对每个像素进行位置编码,再与向量相加。
transformer encoder
此处没什么创新,与原始transformer一样,由multi-head self-attention (MSA) 和 Multilayer Perceptron(MLP) 块组成。MSA与MLP是transformer的基本部分,此处对于MSA与MLP的介绍略过。重点介绍下面论文的创新部分。
Decoder designer
为了评估编码器部分的特征表示,论文设计了三种解码器方式。在此之前需要将编码器的输出Z从向量reshape成H/16 x W/16 x C的形状。
1. 原始上采样 (Naive unsampling)
解码器将编码器输出的特征映射到类别空间,做法是采用了一个简单的 2 层网络将通道数变为类别数量。其架构为:1 × 1 conv + 同步BatchNorm(w/ ReLU)+ 1 × 1 conv。之后,简单地将输出双线性上采样到完整的图像分辨率,然后是具有像素级交叉熵损失的分类层。当使用这个解码器时,这种模型表示为 SETR-Naive。
2. Progressive UPsampling (PUP)
论文考虑一种渐进式上采样策略,而不是可能会引入嘈杂预测的一步上采样策略,该策略交替使用 conv 层和上采样操作。为了最大限度地减轻对抗效应,我们将上采样限制为 2 倍。因此,总共需要 4 次操作才能从 H/ 16 × W /16 转换到图像原分辨率。这个过程的更多细节在图 1(b) 中给出。使用此解码器时,将模型表示为 SETR-PUP。
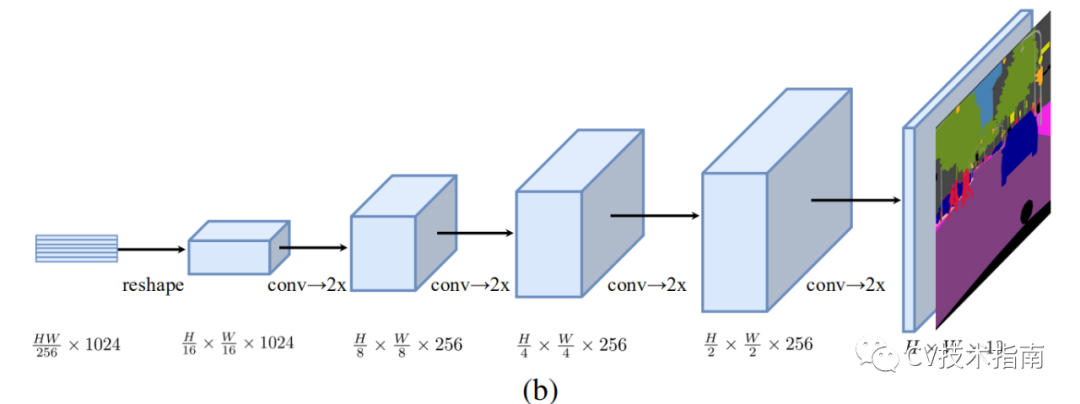
3. Multi-Level feature Aggregation (MLA)
第三种设计的特点是多级特征聚合(图 c)与特征金字塔网络类似。然而,我们的解码器根本不同,因为每个 SETR 层的特征表示 Zl共享相同的分辨率,没有金字塔形状。

具体来说,我们将来自 M 层的特征表示 {Zm} (m ∈ { Le /M , 2 Le/ M , · · · , M Le /M }) 作为输入,这些特征表示从 M 层均匀分布在具有步骤长为 Le /M 。然后部署 M 个流,每个流都专注于一个特定的选定层。
在每个流中,我们首先将编码器的特征 Zl 从 HW /256 × C 的 2D 形状reshape为 3D 特征图 H/ 16 × W/ 16 × C。一个 3 层(kernel大小为 1 × 1、3 × 3 和 3 × 3) 网络,第一层和第三层的特征通道分别减半,第三层后通过双线性操作将空间分辨率提升4倍。
为了增强不同流之间的交互,我们在第一层之后通过逐元素添加引入了自上而下的聚合设计。在逐元素添加功能之后应用额外的 3 × 3 conv。在第三层之后,我们通过通道级连接从所有流中获得融合特征,然后将其双线性上采样 4 倍至全分辨率。使用此解码器时,将模型表示为 SETR-MLA。
Conclusion
三种解码器方式之间的结果对比,结果表明SETR-PUP方式最好。
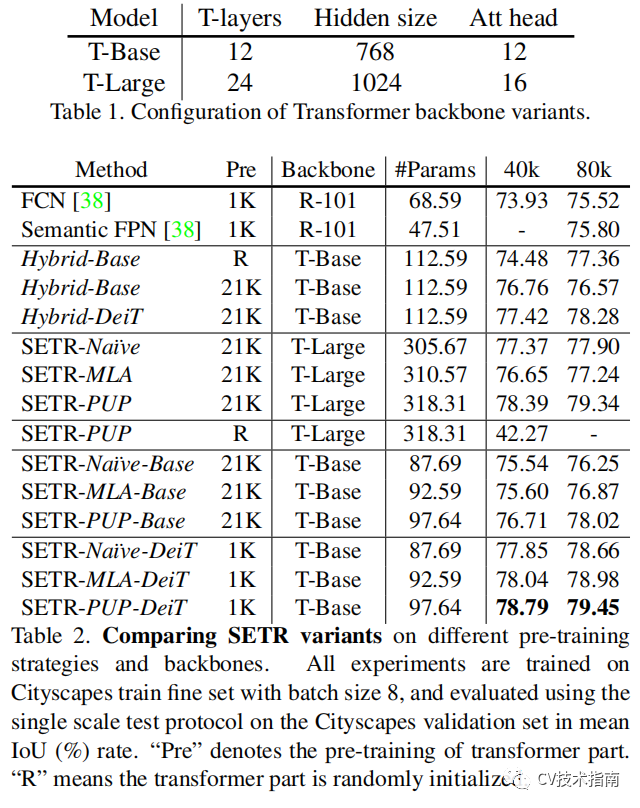
与其它SOTA模型的对比。SETR 在 ADE20K (50.28% mIoU)、Pascal Context (55.83% mIoU) 和 Cityscapes 上的竞争结果上取得了最新SOTA结果。特别是,在提交当天就在竞争激烈的ADE20K测试服务器排行榜中获得了第一名。

效果可视化

交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
