
2021机器学习研究风向是啥?MLP→CNN→Transformer→MLP!
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
来源:机器之心
就在2月份,Transformer还横扫CV和NLP各种task。但到了5月份,似乎一切变了。近来,谷歌、清华、Facebook相继发表了关于多层感知机(MLP)的工作,MLP→CNN→Transformer→MLP似乎已经成为一种大势所趋。我们来看下最新的几篇代表性论文。

12月:“图像识别也是Transformer最强(ViT)”
2月:“Transformer is All you Need”
3月:“Attention is not All you Need”
5月:“在MLP上的ViT并(MLPmixer)”
5月:“Convolution比Transformer强”
5月:“在MLP上加个门,跨越Transformer (Pay Attention to MLPs)”

谷歌大脑首席科学家、AutoML鼻祖Quoc Le研究团队将gMLP用于图像分类任务,并在ImageNet数据集上取得了非常不错的结果。在类似的训练设置下,gMLP实现了与DeiT(一种改进了正则化的ViT模型)相当的性能。不仅如此,在参数减少66%的情况下,gMLP的准确率比MLP-Mixer高出3%。这一系列的实验结果对ViT模型中自注意力层的必要性提出了质疑。
他们还将gMLP应用于BERT的掩码语言建模(MLM)任务,发现gMLP在预训练阶段最小化困惑度的效果与Transformer一样好。该研究的实验表明,困惑度仅与模型的容量有关,对注意力的存在并不敏感。随着容量的增加,研究者观察到,gMLP的预训练和微调表现的提升与Transformer一样快。
gMLP的有效性,视觉任务上自注意力和NLP中注意力机制的case-dependent不再具有优势,所有这些都令研究者对多个领域中注意力的必要性提出了质疑。
总的来说,该研究的实验结果表明,自注意力并不是扩展ML模型的必要因素。随着数据和算力的增加,gMLP等具有简单空间交互机制的模型具备媲美Transformer的强大性能,并且可以移除自注意力或大幅减弱它的作用。
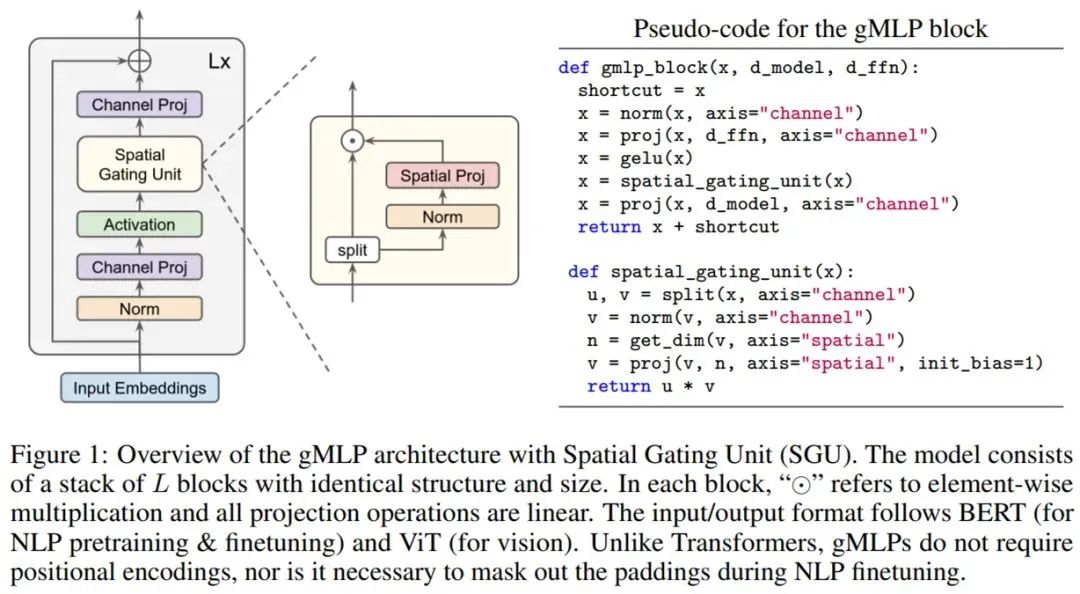
整个模型具有空间门控单元(Spatial Gating Unit, SGU)的gMLP架构示意图如下所示,该模型由堆叠的 L块(具有相同的结构和大小)组成。

谷歌原ViT团队提出了一种不使用卷积或自注意力的MLP-Mixer架构,并且在设计上非常简单,在 ImageNet 数据集上也实现了媲美CNN和ViT的性能。
卷积神经网络(CNNs)是计算机视觉的主流模型,近年来,基于注意力的网络,如vision transformer也得到了广泛的应用。2021年3月4日,谷歌人工智能研究院Ilya Tolstikhin, Neil Houlsby等人研究员提出一种基于多层感知机结构的MLP-Mixer并在顶会“Computer Vision and Pattern Recognition(CVPR)”上发表一篇题为“MLP-Mixer: An all-MLP Architecture for Vision”的文章。MLP-Mixer包含两种类型的MLP层:一种是独立应用于图像patches的MLP(即“混合”每个位置特征),另一种是跨patches应用的MLP(即“混合”空间信息)。当在大数据集上训练时,或使用正则化训练方案时,MLP-Mixer在图像分类基准上获得有竞争力的分数,并且预训练和推理成本与最先进的模型相当。作者希望这些结果能激发出更深入的研究,超越成熟的CNN和transformer领域。
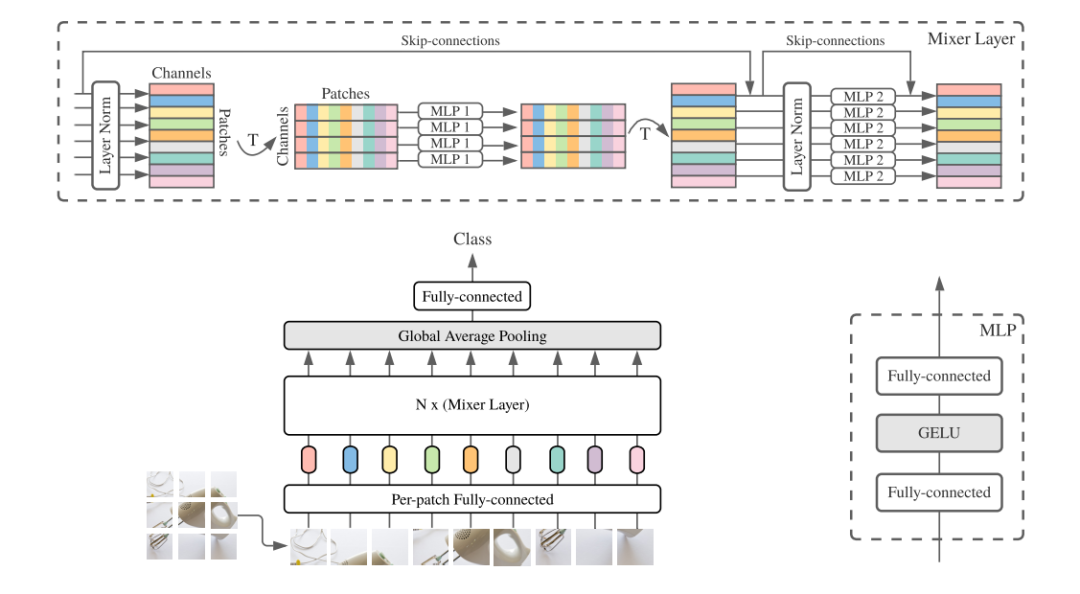
MLP-Mixer的网络结构图
作者提出一种基于多层感知机结构的MLP-Mixer,这是一种不使用注意力机制和卷积的网络。MLP-Mixer的体系结构完全基于多层感知机,将图像的空间位置或特征通道上进行重复应用。MLP-Mixer仅依赖于基础矩阵乘操作、数据排布变换(比如reshape、transposition)以及非线性层。
上图给出了MLP-Mixer的网络结构图。首先跟Vision Transformer的patch image过程一样,将输入尺寸为H×W×C的图像变为N×D的向量,其中P×P为图像块的大小,N=HW÷P2,N是图像块的数量,D是将图像块reshape为固定长度的大小,为了避免由于图像块设置大小不同,造成模型无法固定训练的问题。然后由多个Mixer layer组成,其中Mixer layer使用两种类型的MLP层:信道混合MLP和空间混合MLP。信道混合MLP允许不同信道之间的通信;它们独立地对每个空间位置进行操作。空间混合MLP允许不同空间位置之间的通信;它们独立地对每个通道上进行操作。在Mixer layer里面也应用到跳跃连接。最后通过LayerNorm和全连接层进行输出。

本文的工作主要将MLP作为卷积网络的一种通用组件实现多种任务性能提升(例如,将ResNet50中的3x3卷积替换成只有一半通道数量的RepMLP,可以实现同等精度下超过一半速度提升),不追求抛弃卷积的纯MLP(本文只试验了CIFAR上的纯MLP,只取得了接近卷积网络的效果);恰恰相反,本文利用了卷积去强化FC,使其具备局部性,因而更适用于视觉任务。
本文的方法可以在ImageNet、语义分割、人脸识别等数据集和相应任务上实现涨点,这些任务输入分辨率各不相同,有的具有平移不变性而有的不具备(本文认为FC和卷积主要的区别就在于是否平移不变);而谷歌的论文只做了几个固定分辨率输入的图像分类实验。
本文提出了一种多层感知机(MLP)模式的图像识别神经网络构造块RepMLP,它由一系列全连接层(FC)组成。
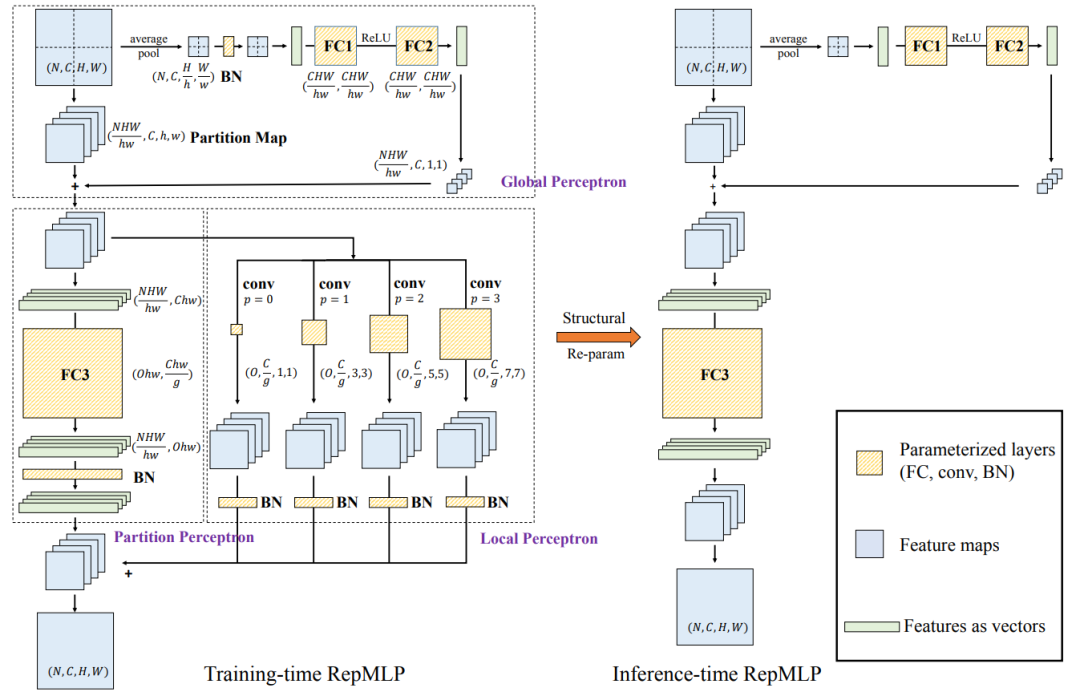
图注:RepMLP的架构图
与卷积层相比,FC层效率更高,更适合于建模长程(long-range)依赖关系和位置模式,但不适合捕获局部结构,因此通常不太适合用于图像识别。而本文提出了一种结构重新参数化技术,可以将局部先验加入到全连接层(FC)中,使其具有强大的图像识别能力。

Facebook也于近日提出了一种用于图像分类的纯MLP架构,该架构受 ViT 的启发,但更加简单:不采用任何形式的注意力机制,仅仅包含线性层与GELU非线性激活函数。
https://www.zhuanzhi.ai/paper/906513635482cdda897acaf1860abef4
本文第一作者就是DeiT 一作Hugo Touvron博士。他曾经针对视觉Transformer模型ViT需要大量数据集训练的难题提出了DeiT模型,通过一组优秀的超参数和蒸馏操作实现了仅仅使用ImageNet数据集就能达到很强的性能,详见下面链接。现在他又按照这个思路写了一篇,针对视觉MLP模型MLP-Mixer需要大量数据集训练的难题提出了ResMLP模型,通过残差结构和蒸馏操作实现了仅仅使用ImageNet数据集就能达到很强的性能。
参考链接:
https://mp.weixin.qq.com/s/6mUdc2N1jAlh0pW8QIknoA
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
—THE END—