
2021年,机器学习研究风向要变了?
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
在机器学习领域里有一句俗话:「Attention is all you need」,通过注意力机制,谷歌提出的 Transformer 模型引领了 NLP 领域的大幅度进化,进而影响了 CV 领域,甚至连论文标题本身也变成了一个梗,被其后的研究者们不断重新演绎。



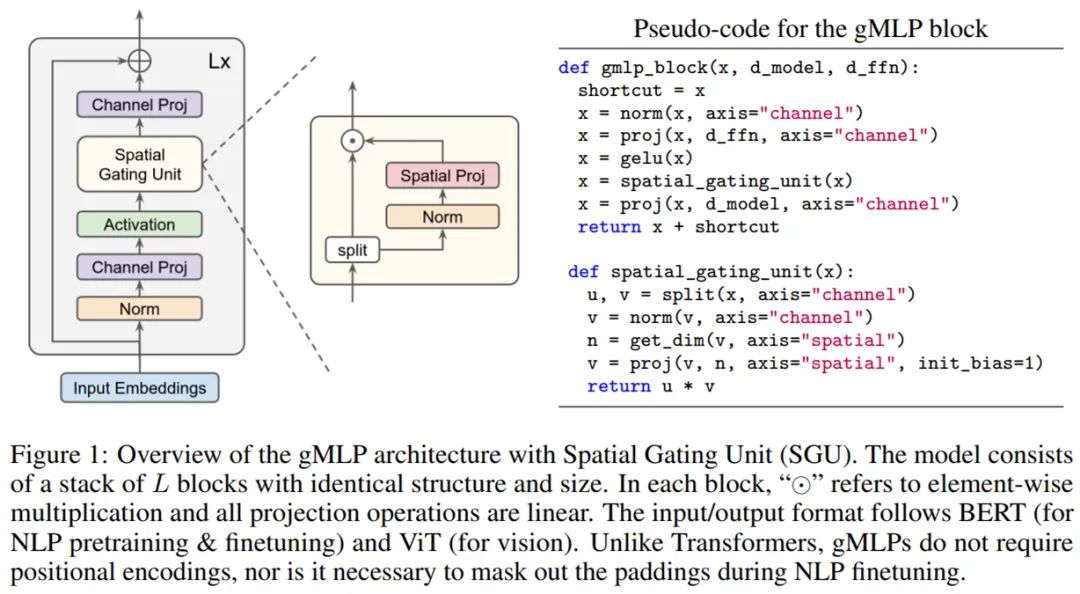




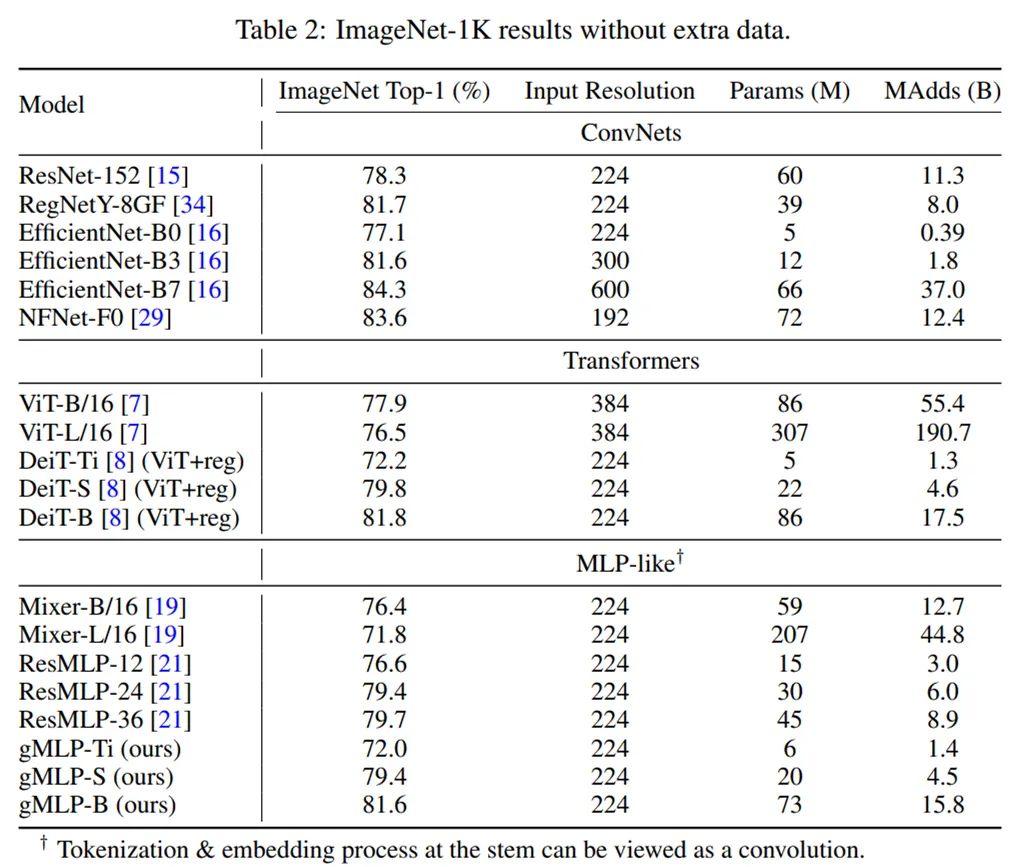
具有 Transformer 架构和可学得绝对位置嵌入的 BERT;
具有 Transformer 架构和 T5-style 可学得相对位置偏差的 BERT;
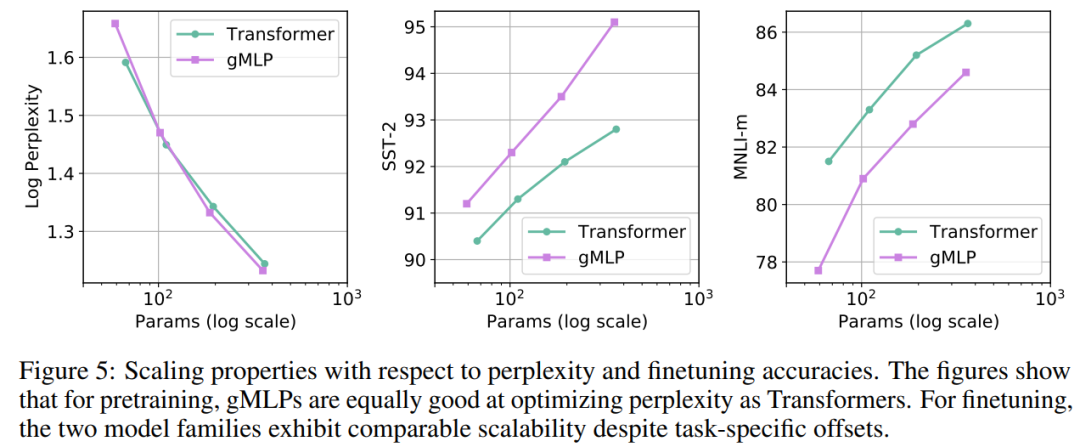
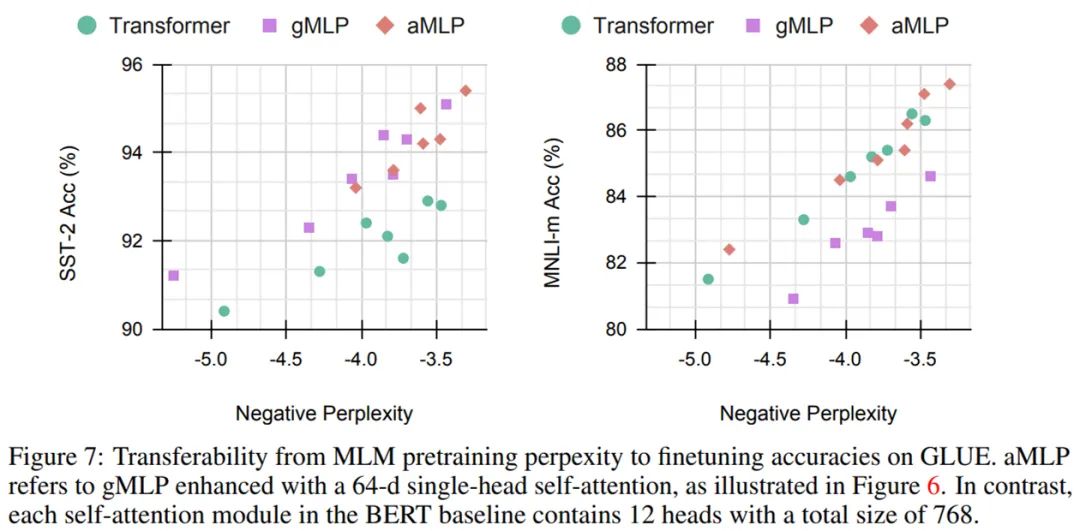
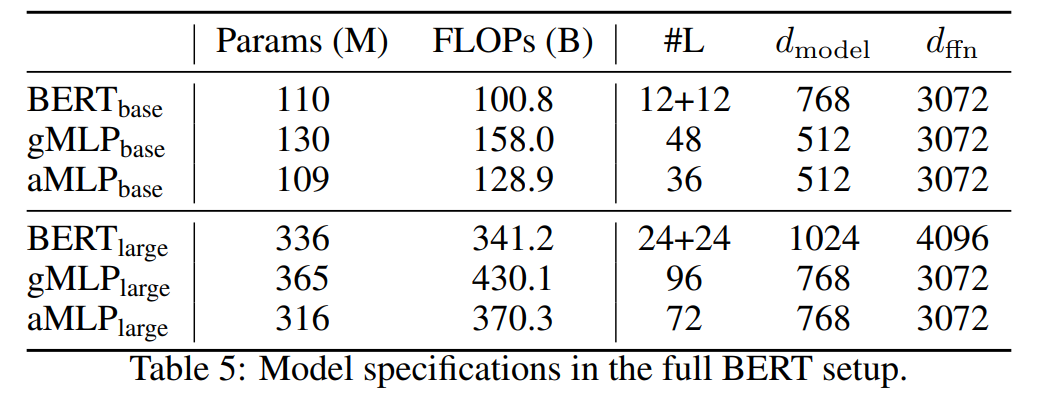
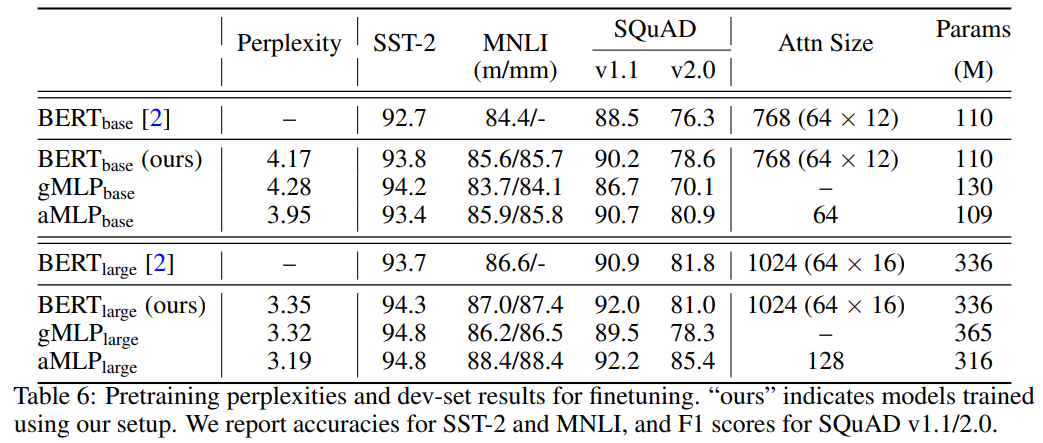
同上,但在 softmax 内部移除了所有与内容有关的项,并仅保留相对位置偏差。

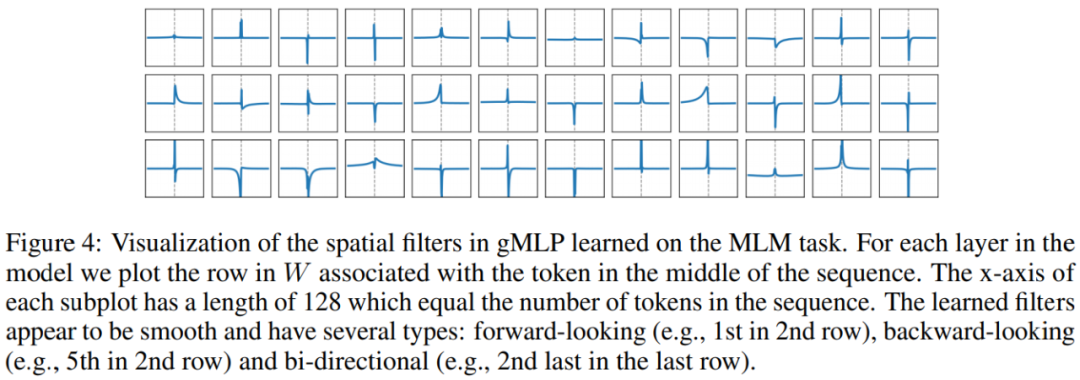
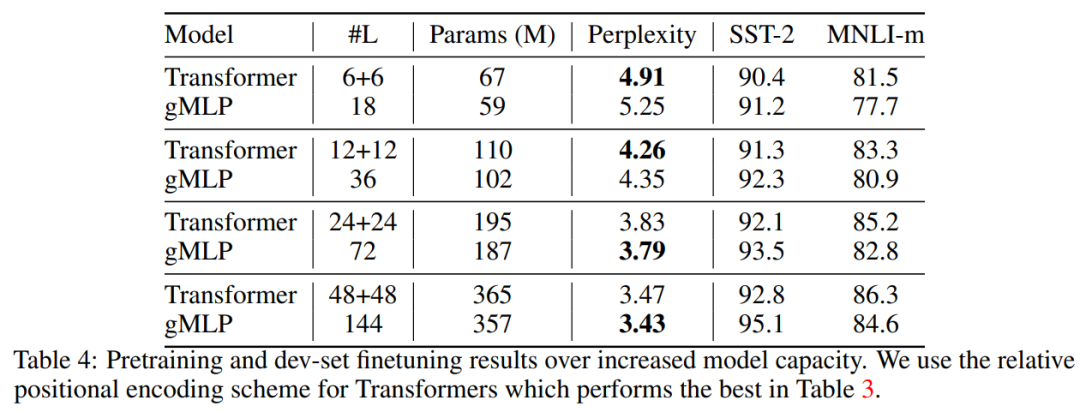


也可以加一下老胡的微信 围观朋友圈~~~
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论