
深度!图解神经网络的数学原理
如今,熟练使用像 Keras、TensorFlow 或 PyTorch 之类的专用框架和高级程序库后,我们不用再经常费心考虑神经网络模型的大小,或者记住激活函数和导数的公式什么的。有了这些库和框架,我们创建一个神经网络,哪怕是架构很复杂的网络,往往也只是需要几个导入和几行代码而已。如下示例:
使用框架搭建神经网络
首先,我会展示一种热门神经网络框架 -- Keras用来搭建神经网络模型。
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(4, input_dim=2,activation='relu'))
model.add(Dense(6, activation='relu'))
model.add(Dense(6, activation='relu'))
model.add(Dense(4, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=50, verbose=0)
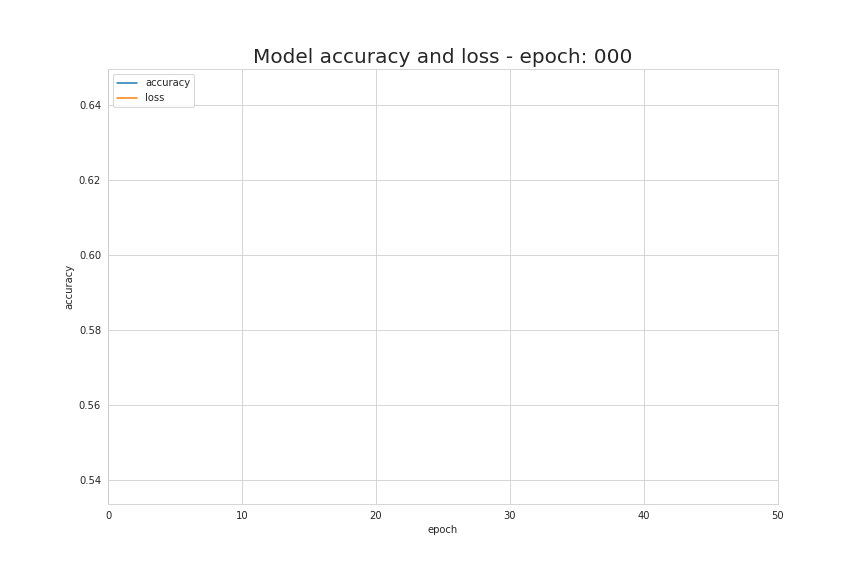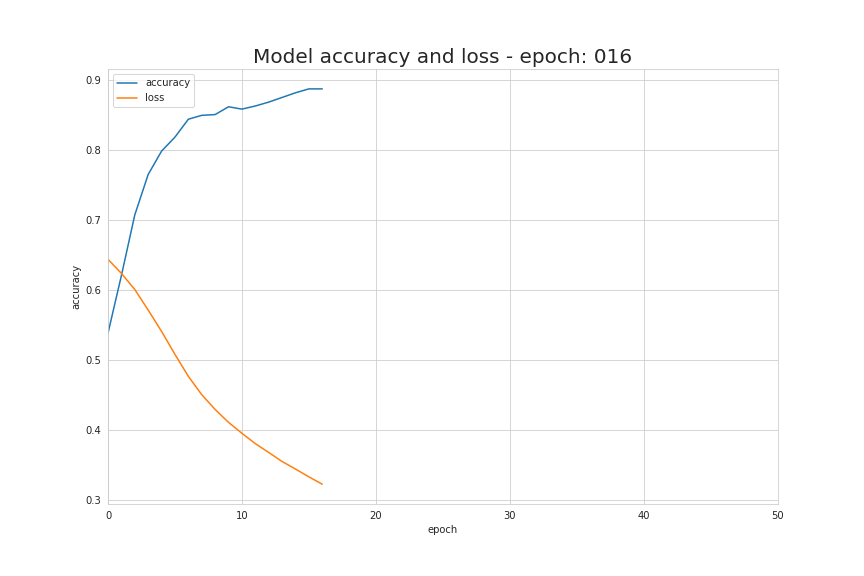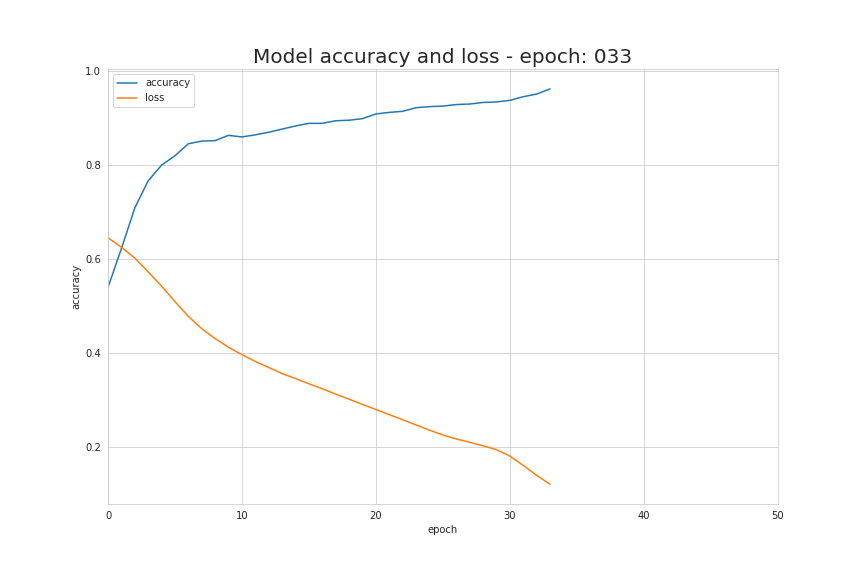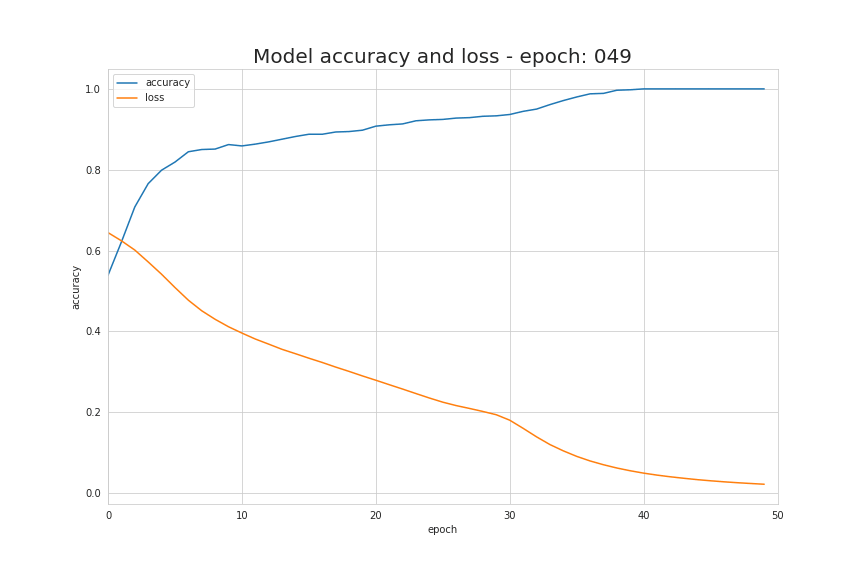
如前面说过,只需几个导入、几行代码就能创建和训练一个模型,拿来解决分类问题几乎能达到 100% 的准确率。我们的工作归纳起来就是根据选择的模型结构,为模型提供超参数,比如网络层的数量、每层的神经元数量、激活函数和训练周期数量等等。下面我们来看看训练的过程发生了什么,可以看到随着训练过程中,数据被正确地区分开了!
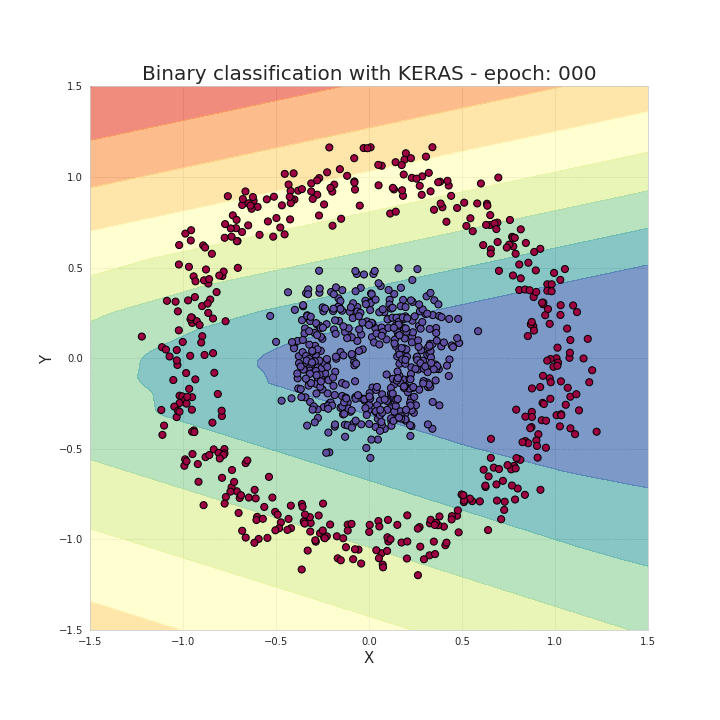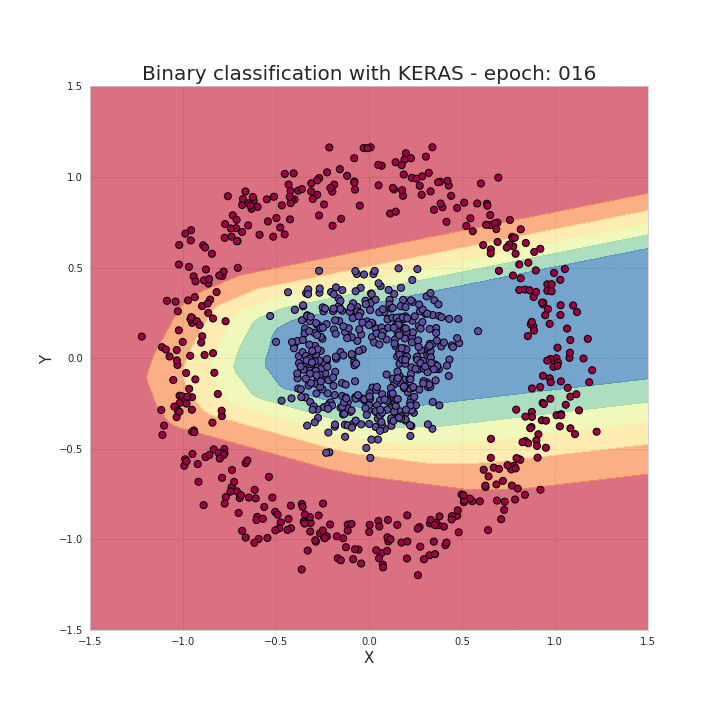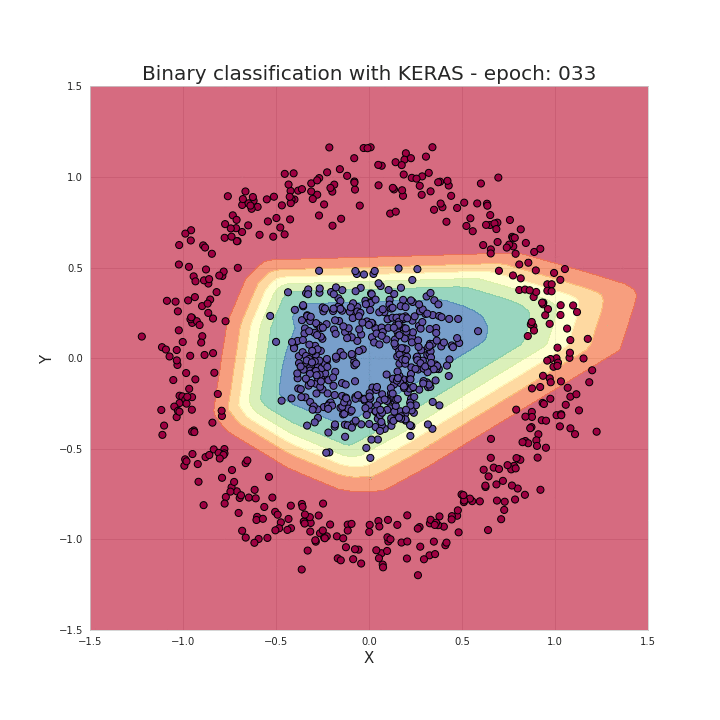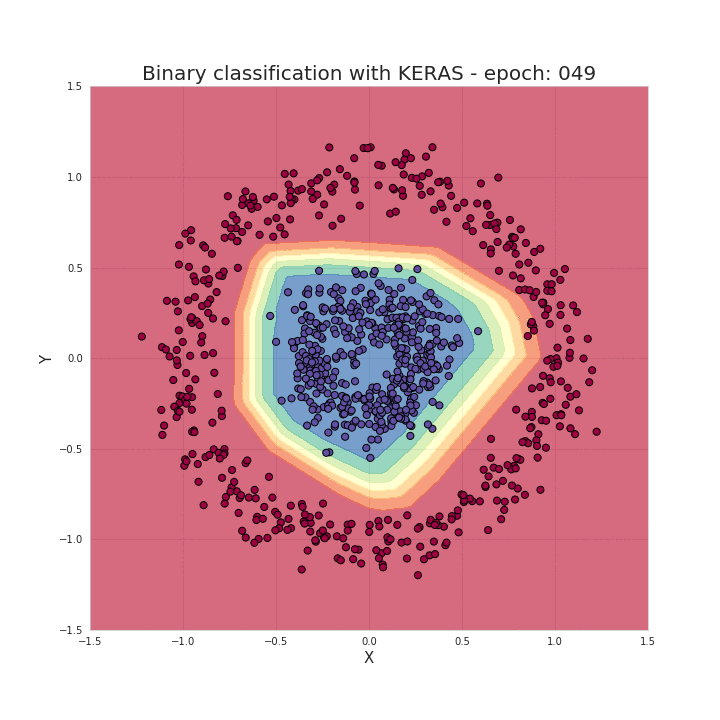
有了这些框架,这的确为我们节省了大量写bugs(...) 的时间,让我们的工作也更加流程化。然而,熟知神经网络背后的工作原理,对于我们选择模型架构、调参或优化模型都有莫大的帮助。
神经网络原理
为了更深入的理解神经网络的工作原理,本文将帮助大家理解一些在学习过程中可能会感到困惑的概念。我会尽量让那些对代数和微积分不感冒的朋友读着不那么痛苦,但是正如文章题目所示,本文主要讲数学原理,所以会谈论大量的数学,在这里先提个醒。
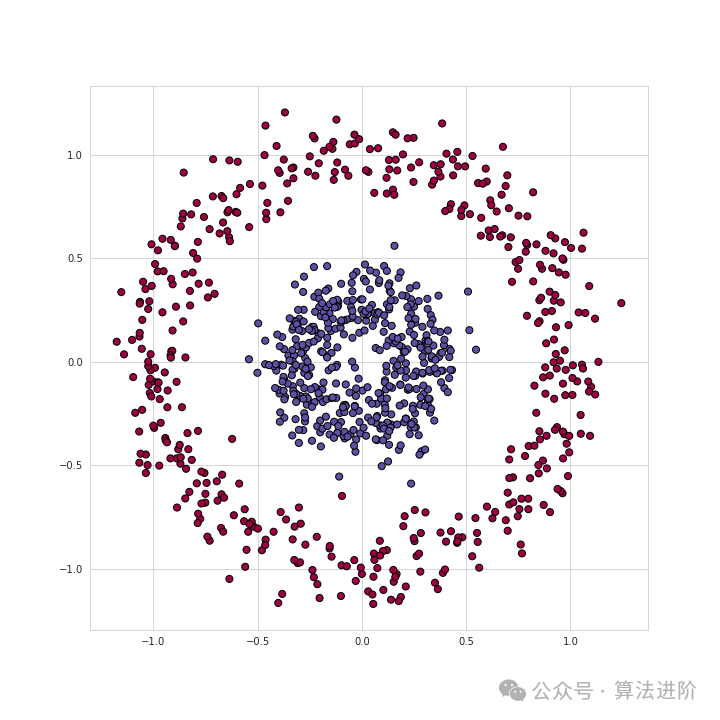
举个例子,我们要解决一个数据集的二元分类问题,数据集如上所示。
数据点组成了两个类别的圆圈状,要区分这个数据,对很多传统的机器学习算法来说都非常麻烦,但神经网络可以很好地处理这个非线性分类问题。
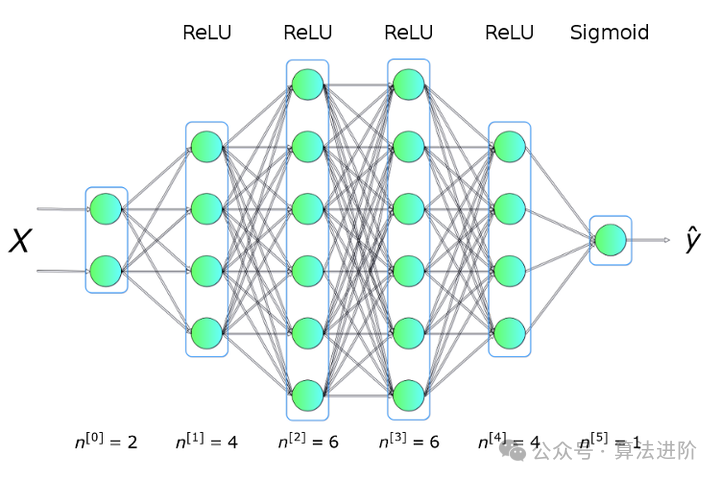
为了解决这个问题,我们会使用如下图所示结构的神经网络,它有 5 个全连接层,每层有不同数量的神经元。对于隐藏层,我们会使用 ReLU 作为激活函数,在输出层中使用 S 型函数。这是个相当简单的结构,但也足够解决我们的难题了。
什么是神经网络?
我们首先来回答这个关键的问题:什么是神经网络?它是一种在生物学启发下创建的计算机程序,能够学习知识,独立发现数据中的关系。如图 2 所示,神经网络就是一系列的神经元排列在网络层中,网络层以某种方式连接在一起,从而相互之间实现沟通。
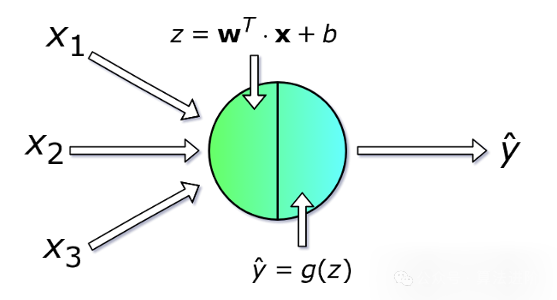
单个神经元
每个神经元会接受一系列的 x 值(从 1 到 n 的数字)作为输入,计算预测的 y-hat 值。向量 x 实际上包含了训练集中 m 个样本中一个样本的特征值。而且每个神经元会有它自己的一套参数,通常引用为 w(权重的列向量)和 b(偏差),在学习过程中偏差会不断变化。在每次迭代中,神经元会根据向量 x 的当前权向量 x 计算它的加权平均值,再和偏差相加。最后,计算的结果会传入一个非线性或函数 g 中。我在下面会提及一些最常见的激活函数。
单个网络层
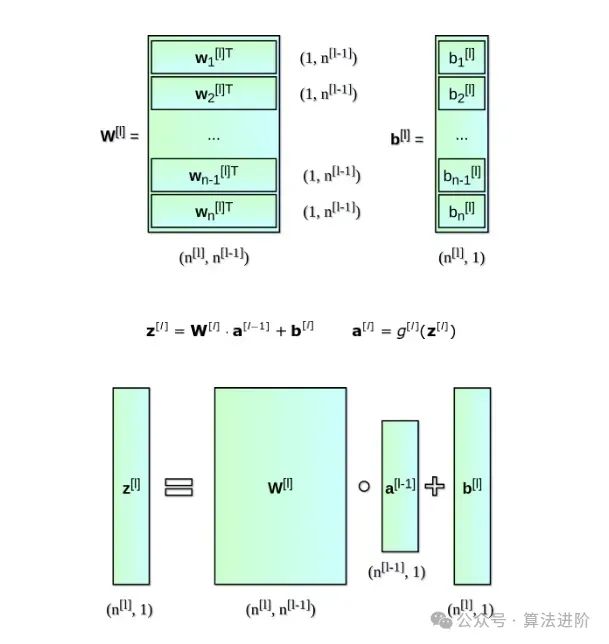
现在,我们把范围缩小一点,思考一下神经网络的整个网络层是怎么进行数学运算的。我们会利用单个神经元的计算知识,在整个层中进行向量化,将这些计算融合进矩阵方程中。为了让数学符号一致,这些方程会写给选定的网络层。另外,下标的 i 符号标记了这一层的神经元顺序。

还有一件重要的事:在我们为单个神经元写方程时,我们使用 x 和 y-hat,它们分别表示特征列向量和预测值。当换成网络层的通用符号时,我们使用向量 a —— 意指对应网络层的激活。因此 x 向量是网络层 0(输入层)的激活。网络层中的每个神经元都按照如下方程式执行相同的运算:
让大家更清晰的看看,我们把第 2 层的公式写下来:
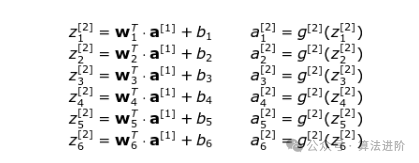
你可以看到,对每个网络层,我们必须执行一系列非常相似的运算。在这里使用 for 循环并不是非常高效,所以我们换成向量化来加快计算速度。首先,将权重 w 的水平向量堆放在一起,我们创建矩阵 W。同样地,我们将网络层中每个神经元的偏差堆放在一起,创建垂直向量 b。现在,我们可以顺利地创建一个矩阵方程式了,从而一次性计算该网络层的所有神经元。我们同样写下来用过的矩阵和向量的维度。
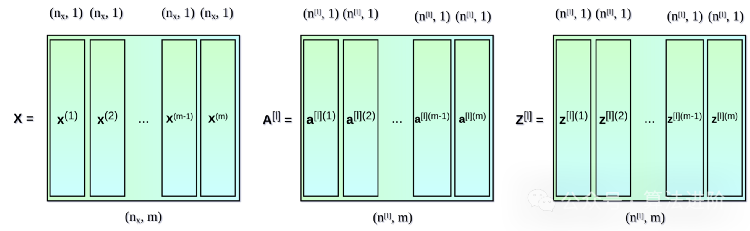
多个例子中的向量化
我们迄今所用的方程式只涉及了一个例子。在神经网络的学习过程中,你通常要处理大量的数据,最高可达数百万条。所以下一步就是在多个例子中实现向量化。假设我们的数据集有 m 个条目,每个有 nx 个特征。首先,我们将每一层的垂直向量 x,a 和 z 放在一起,分别创建矩阵 X,A 和 Z。然后,我们根据新创建的矩阵,重新编写之前列出的方程式。
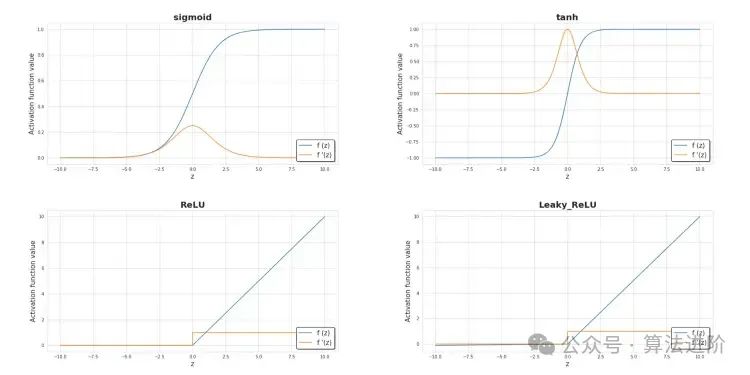
什么是激活函数?我们为何需要它?
激活函数是神经网络中最重要的部分之一。没有激活函数,我们的神经网络就只是一些线性函数的组合,那样无非就是个线性函数而已。如果是这样,模型的扩展性就很有限了,比逻辑回归也强不到哪去。非线性部分能让模型有更大的灵活性,在学习过程中也能创建复杂的函数。
此外,激活函数对模型的学习速度也有重大影响,而学习速度是选择模型的主要标准之一。下图显示了一些常用的激活函数。当前,隐藏层中最常用的激活函数应该是 ReLU。在处理二元分类问题时,特别是想让模型返回在 0 到 1 之间的值时,我们有时也会使用 S 型函数,特别是在输出层中。
损失函数
学习过程中基本信息源就是损失函数的值。通常来讲,使用损失函数的目的就是展示我们离“理想”情况的差距。在我们这个例子中,我们使用了二元交叉熵,但根据我们处理的具体问题,可以使用不同的函数。我们所用的函数用如下公式表示,在学习过程中它的值的变化情况可视化动图如下。它显示了每次迭代中,损失函数的值在不断下降,准确度的值也不断增加。
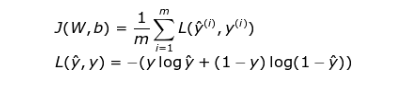
神经网络是怎么学习的?
学习过程就是不断改变 W 和 b 参数的值,让损失函数实现最小化。为了能实现这个目标,我们会借助微积分,使用梯度下降法来找到函数最小值。在每次迭代中,我们会计算损失函数偏导数相对于每个神经网络参数的值。对于不太熟悉这种计算类型的人,我这里提示一下,导数能够描述函数的斜率。正因如此,我们能够知道该如何操作变量,从而在图中向下移动。为了能让大家直观感受梯度下降的工作原理,我预备了一点小小的可视化,如下图所示。你可以看到,随着训练批次增加,我们越来越靠近最小值。在我们的神经网络中,也是同样的工作方式——每次迭代计算出的梯度为我们显示了应该向哪个方向移动。主要的不同之处是在我们的神经网络中,我们有更多的参数可以调整。那么怎么计算如此复杂的导数呢?
反向传播
反向传播是一种算法,能让我们计算非常复杂的梯度,比如我们这个例子中需要的梯度。神经网络的参数按照如下公式进行调整。
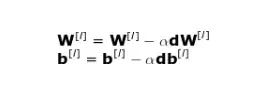
在上面的方程式中,α 表示学习率——该超参数能让我们控制调整幅度的大小。选择学习率很关键,如果设置的太低,神经网络会学习的非常慢;如果设置的太高,我们就无法达到损失的最小值。使用链式法则以及损失函数对于 W 和 b 的偏导数来计算出 dW 和 db,这二者的大小分别等于 W 和 b。下面第二张图展示了神经网络中的操作顺序。我们可以清楚地看到正向传播和反向传播共同工作,优化损失函数。
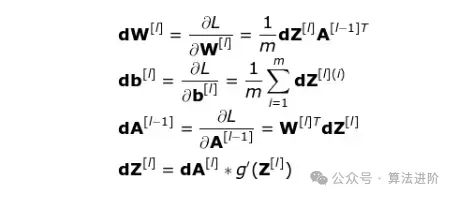
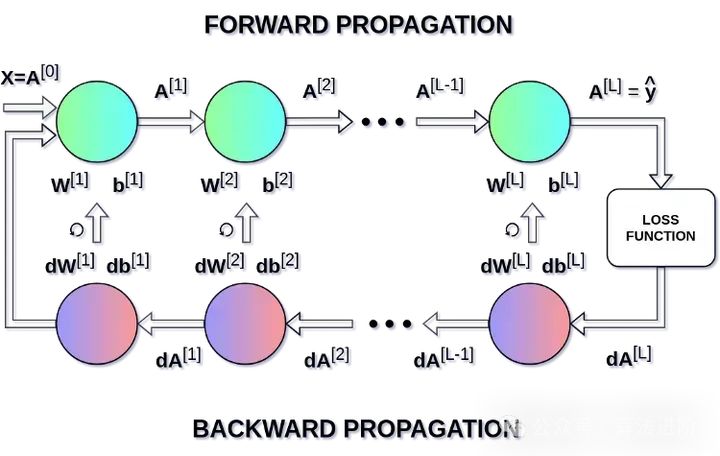
结语
希望本文能帮助你理解一些神经网络背后的数学原理,掌握其中的数学基础知识对于你使用神经网络会大有帮助。虽然本文列出了一些重要内容,但它们也只是冰山一角。强烈建议你自己试着用一些简单的框架写一个小型的神经网络,不要借助很高级的框架,这样能加深你对机器学习的理解。
