
从字符串到常量池,一文看懂String类
从一道面试题开始
看到这个标题,你肯定以为我又要讲这道面试题了
// 这行代码创建了几个对象?
String s3 = new String("1");
是的,没错,我确实要从这里开始

这道题就算你没做过也肯定看到,总所周知,它创建了两个对象,一个位于堆上,一个位于常量池中。
这个答案粗看起来是没有任何问题的,但是仔细思考确经不起推敲。
如果你觉得我说的不对的话,那么可以思考下面这两个问题
你说它创建了两个对象,那么这两个对象分别是怎样创建的呢?我们回顾下 Java 创建对象的方式,一共就这么几种
你说它创建了两个对象,那你告诉我除了 new 出来那个对象外,另外一个对象怎么创建出来的?
使用 new 关键字创建对象 使用反射创建对象(包括 Class 类的 newInstance方法,以及 Constructor 类的newInstance方法)使用 clone 复制一个对象 反序列化得到一个对象 堆跟常量池到底什么关系?不是说在
JDK1.7之后(含 1.7 版本)常量池已经移到了堆中了吗?如果说常量池本身就位于堆中的话,那么这种一个对象在堆中,一个对象在常量池的说法还准确吗?
如果你也产生过这些疑问的话,那么请耐心看完这篇文章!要解释上面的问题首先我们得对常量池有个准确的认知。

通常来说,我们提到的常量池分为三种
class 文件中的常量池 运行时常量池 字符串常量池
对于这三种常量池,我们需要搞懂下面几个问题?
这个常量池在哪里? 这个常量池用来干什么呢? 这三者有什么关系?
接下来,我们带着这些问题往下看

class文件常量池
位置在哪?
顾名思义,class 文件中的常量池当然是位于 class 文件中,而class 文件又是位于磁盘上。
用来干什么的?
在学习 class 文件中的常量池前,我们首选需要对 class 文件的结构有一定了解
Class 文件是一组以 8 个字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在文
件之中,中间没有添加任何分隔符,这使得整个 Class 文件中存储的内容几乎全部是程序运行的必要数
据,没有空隙存在。
------------《深入理解 Java 虚拟机》
整个 class 文件的组成可以用下图来表示
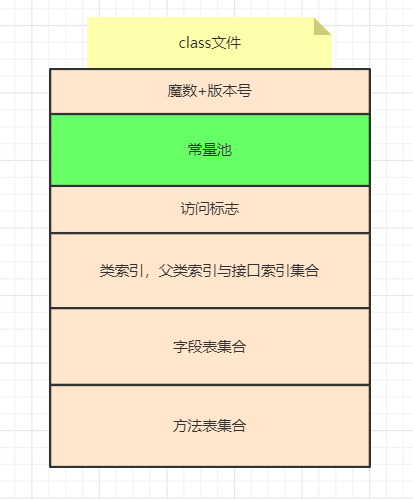
对本文而言,我们只关注其中的常量池部分,常量池可以理解为 class 文件中资源仓库,它是 class 文件结构中与其它项目关联最多的数据类型,主要用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。字面量就是我们所说的常量概念,如文本字符串、被声明为 final 的常量值等。符号引用是一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可(它与直接引用区分一下,直接引用一般是指向方法区的本地指针,相对偏移量或是一个能间接定位到目标的句柄)。一般包括下面三类常量:
类和接口的全限定名 字段的名称和描述符 方法的名称和描述符
现在我们知道了 class 文件中常量池的作用:存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。很多时候知道了一个东西的概念并不能说你会了,对于程序员而言,如果你说你已经会了,那么最好的证明是你能够通过代码将其描述出来,所以,接下来,我想以一种直观的方式让大家感受到常量池的存在。通过分析一段简单代码的字节码,让大家能更好感知常量池的作用。
talk is cheap ,show me code
我们以下面这段代码为例,通过javap来查看 class 文件中的具体内容,代码如下:
/**
* @author 程序员DMZ
* @Date Create in 22:59 2020/6/15
* @公众号 微信搜索:程序员DMZ
*/
public class Main {
public static void main(String[] args) {
String name = "dmz";
}
}
进入Main.java文件所在目录,执行命令:javac Main.java,那么此时会在当前目录下生成对应的Main.class文件。再执行命令:javap -v -c Main.class,此时会得到如下的解析后的字节码信息
public class com.dmz.jvm.Main
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
// 这里就是常量池了
Constant pool:
#1 = Methodref #4.#20 // java/lang/Object."":()V
#2 = String #21 // dmz
#3 = Class #22 // com/dmz/jvm/Main
#4 = Class #23 // java/lang/Object
#5 = Utf8
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Utf8 LineNumberTable
#9 = Utf8 LocalVariableTable
#10 = Utf8 this
#11 = Utf8 Lcom/dmz/jvm/Main;
#12 = Utf8 main
#13 = Utf8 ([Ljava/lang/String;)V
#14 = Utf8 args
#15 = Utf8 [Ljava/lang/String;
#16 = Utf8 name
#17 = Utf8 Ljava/lang/String;
#18 = Utf8 SourceFile
#19 = Utf8 Main.java
#20 = NameAndType #5:#6 // "":()V
#21 = Utf8 dmz
#22 = Utf8 com/dmz/jvm/Main
#23 = Utf8 java/lang/Object
// 下面是方法表
{
public com.dmz.jvm.Main();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return
LineNumberTable:
line 7: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/dmz/jvm/Main;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=2, args_size=1
// 可以看到方法表中的指令引用了常量池中的常量,这也是为什么说常量池是资源仓库的原因
// 因为它会被class文件中的其它结构引用
0: ldc #2 // String dmz
2: astore_1
3: return
LineNumberTable:
line 9: 0
line 10: 3
LocalVariableTable:
Start Length Slot Name Signature
0 4 0 args [Ljava/lang/String;
3 1 1 name Ljava/lang/String;
}
SourceFile: "Main.java"
在上面的字节码中,我们暂且关注常量池中的内容即可。主要看这两行
#2 = String #14 // dmz
#14 = Utf8 dmz
如果要看懂这两行代码,我们需要对常量池中 String 类型常量的结构有一定了解,其结构如下:
| CONSTANT_String_info | tag | 标志常量类型的标签 |
|---|---|---|
| index | 指向字符串字面量的索引 |
对应到我们上面的字节码中,tag=String,index=#14,所以我们可以知道,#2是一个字面量为#14的字符串类型常量。而#14对应的字面量信息(一个Utf8类型的常量)就是dmz。
常量池作为资源仓库,最大的用处在于被 class 文件中的其它结构所引用,这个时候我们再将注意力放到 main 方法上来,对应的就是这三条指令
0: ldc #2 // String dmz
2: astore_1
3: return
ldc:这个指令的作用是将对应的常量的引用压入操作数栈,在执行ldc指令时会触发对它的符号引用进行解析,在上面例子中对应的符号引用就是#2,也就是常量池中的第二个元素(这里就能看出方法表中就引用了常量池中的资源)
astore_1:将操作数栈底元素弹出,存储到局部变量表中的 1 号元素
return:方法返回值为 void,标志方法执行完成,将方法对应栈帧从栈中弹出
下面我用画图的方式来画出整个流程,主要分为四步
解析
ldc指令的符号引用(#2)将
#2对应的常量的引用压入到操作数栈顶将操作数栈的元素弹出并存储到局部变量表中
执行
return指令,方法执行结束,弹出栈区该方法对应的栈帧
第一步:
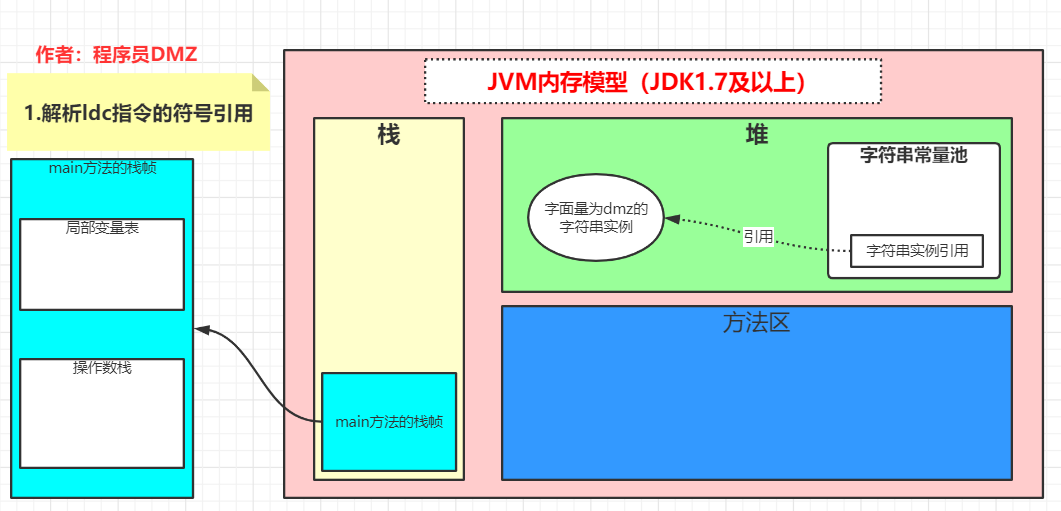
在解析#2这个符号引用时,会先到字符串常量池中查找是否存在对应字符串实例的引用,如果有的话,那么直接返回这个字符串实例的引用,如果没有的话,会创建一个字符串实例,那么将其添加到字符串常量池中(实际上是将其引用放入到一个哈希表中),之后再返回这个字符串实例对象的引用。
到这里也能回答我们之前提出的那个问题了,一个对象是 new 出来的,另外一个是在解析常量池的时候 JVM 自动创建的
第二步:
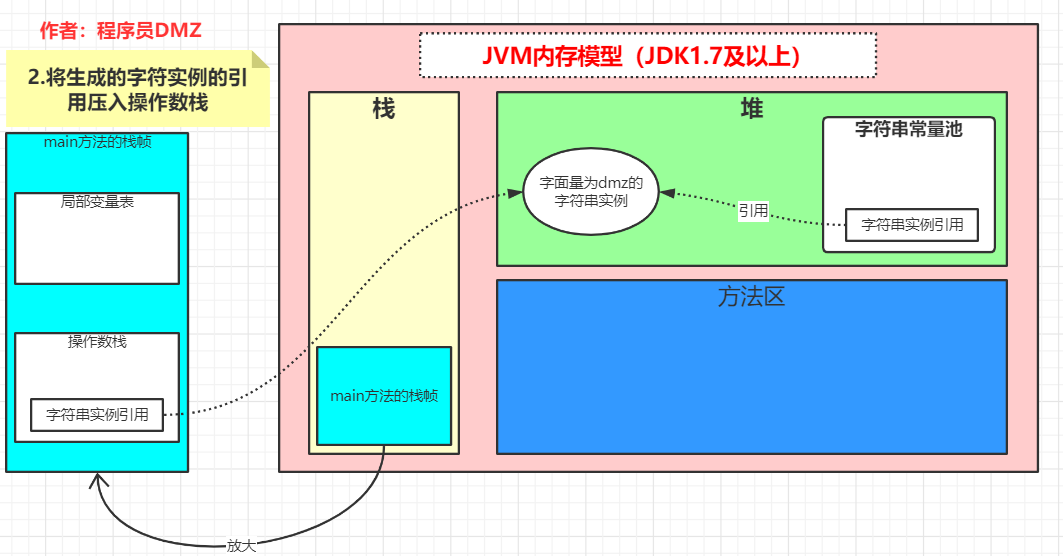
将第一步得到的引用压入到操作数栈,此时这个字符串实例同时被操作数栈以及字符串常量池引用。
第三步:
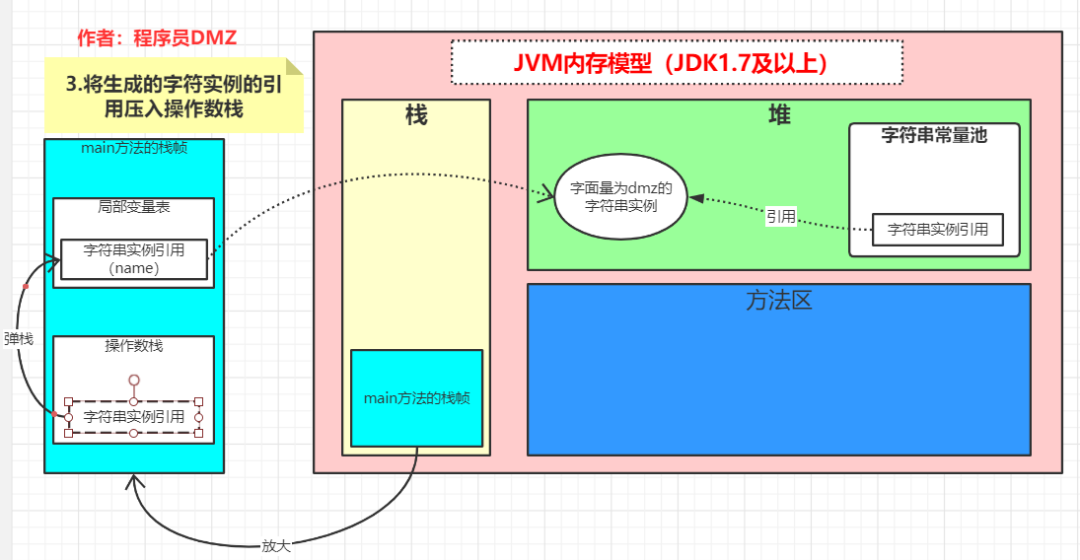
操作数栈中的引用弹出,并赋值给局部变量表中的 1 号位置元素,到这一步其实执行完了String name = "dmz"这行代码。此时局部变量表中储存着一个指向堆中字符串实例的引用,并且这个字符串实例同时也被字符串常量池引用。
第四步:
这一步我就不画图了,就是方法执行完成,栈帧弹出,非常简单。
在上文中,我多次提到了字符串常量池,它到底是个什么东西呢?我们还是分为两部分讨论
位置在哪? 用来干什么的?
字符串常量池
位置在哪?
字符串常量池比较特殊,在JDK1.7之前,其存在于永久代中,到JDK1.7及之后,已经中永久代移到了堆中。当然,如果你非要说永久代也是堆的一部分那我也没办法。
另外还要说明一点,经常有同学会将方法区,元空间,永久代(permgen space)的概念混淆。请注意
方法区是JVM在内存分配时需要遵守的规范,是一个理论,具体的实现可以因人而异永久代是hotspot的jdk1.8以前对方法区的实现,使用jdk1.7的老司机肯定以前经常遇到过java.lang.OutOfMemoryError: PremGen space异常。这里的PermGen space其实指的就是方法区。不过方法区和PermGen space又有着本质的区别。前者是JVM的规范,而后者则是JVM规范的一种实现,并且只有HotSpot才有PermGen space。元空间是jdk1.8对方法区的实现,jdk1.8彻底移除了永久代,其实,移除永久代的工作从JDK 1.7就开始了。JDK 1.7中,存储在永久代的部分数据就已经转移到 Java Heap 或者 Native Heap。但永久代仍存在于JDK 1.7中,并没有完全移除,譬如符号引用(Symbols)转移到了 native heap;字面量(interned strings)转移到了 Java heap;类的静态变量(class statics)转移到了 Java heap。到jdk1.8彻底移除了永久代,将 JDK7 中还剩余的永久代信息全部移到元空间,元空间相比对永久代最大的差别是,元空间使用的是本地内存(Native Memory)。
用来干什么的?
字符串常量池,顾名思义,肯定就是用来存储字符串的嘛,准确来说存储的是字符串实例对象的引用。我查阅了很多博客、资料,它们都会说,字符串常量池中存储的就是字符串对象。其实我们可以类比下面这段代码:
HashSet persons = new HashSet;
在persons这个集合中,存储的是Person对象还是Person对象对应的引用呢?
所以,请大声跟我念三遍
字符串常量池存储的是字符串实例对象的引用!
字符串常量池存储的是字符串实例对象的引用!
字符串常量池存储的是字符串实例对象的引用!
下面我们来看 R 大博文下评论的一段话:
简单来说,HotSpot VM 里 StringTable 是个哈希表,里面存的是驻留字符串的引用(而不是驻留字符串实例自身)。也就是说某些普通的字符串实例被这个 StringTable 引用之后就等同被赋予了“驻留字符串”的身份。这个 StringTable 在每个 HotSpot VM 的实例里只有一份,被所有的类共享。类的运行时常量池里的 CONSTANT_String 类型的常量,经过解析(resolve)之后,同样存的是字符串的引用;解析的过程会去查询 StringTable,以保证运行时常量池所引用的字符串与 StringTable 所引用的是一致的。
------R 大博客
从上面我们可以知道
字符串常量池本质就是一个哈希表 字符串常量池中存储的是字符串实例的引用 字符串常量池在被整个 JVM 共享 在解析运行时常量池中的符号引用时,会去查询字符串常量池,确保运行时常量池中解析后的直接引用跟字符串常量池中的引用是一致的
为了更好理解上面的内容,我们需要去分析 String 中的一个方法-----intern()
intern 方法分析
/**
* Returns a canonical representation for the string object.
*
* A pool of strings, initially empty, is maintained privately by the
* class String.
*
* When the intern method is invoked, if the pool already contains a
* string equal to this String object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this String object is added to the
* pool and a reference to this String object is returned.
*
* It follows that for any two strings s and t,
* s.intern() == t.intern() is true
* if and only if s.equals(t) is true.
*
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* The Java™ Language Specification.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
String#intern方法中看到,这个方法是一个 native 的方法,但注释写的非常明了。“如果常量池中存在当前字符串, 就会直接返回当前字符串. 如果常量池中没有此字符串, 会将此字符串放入常量池中后, 再返回”。
关于其详细的分析可以参考:美团:深入解析 String#intern[1]
珠玉在前,所以本文着重就分析下 intern 方法在JDK不同版本下的差异,首先我们要知道引起差异的原因是因为JDK1.7及之后将字符串常量池从永久代挪到了堆中。
我这里就以美团文章中的示例代码来进行分析,代码如下:
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
打印结果是
jdk6 下 false falsejdk7 下 false true
在美团的文章中已经对这个结果做了详细的解释,接下来我就用我的图解方式再分析一波这个过程
jdk6 执行流程
第一步:执行String s = new String("1"),要清楚这行代码的执行过程,我们还是得从字节码入手,这行代码对应的字节码如下:
public static void main(java.lang.String[]);
Code:
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String 1
6: invokespecial #4 // Method java/lang/String."":(Ljava/lang/String;)V
9: astore_1
10: return
new :创建了一个类的实例(还没有调用构造器函数),并将其引用压入操作数栈顶
dup:复制栈顶数值并将复制值压入栈顶,这是因为invokespecial跟astore_1各需要消耗一个引用
ldc:解析常量池符号引用,将实际的直接引用压入操作数栈顶
invokespecial:弹出此时栈顶的常量引用及对象引用,执行invokespecial指令,调用构造函数
astore_1:将此时操作数栈顶的元素弹出,赋值给局部变量表中 1 号元素(0 号元素存的是 main 函数的参数)
我们可以将上面整个过程分为两个阶段
解析常量 调用构造函数创建对象并返回引用
在解析常量的过程中,因为该字符串常量是第一次解析,所以会先在永久代中创建一个字符串实例对象,并将其引用添加到字符串常量池中。此时内存状态如下:
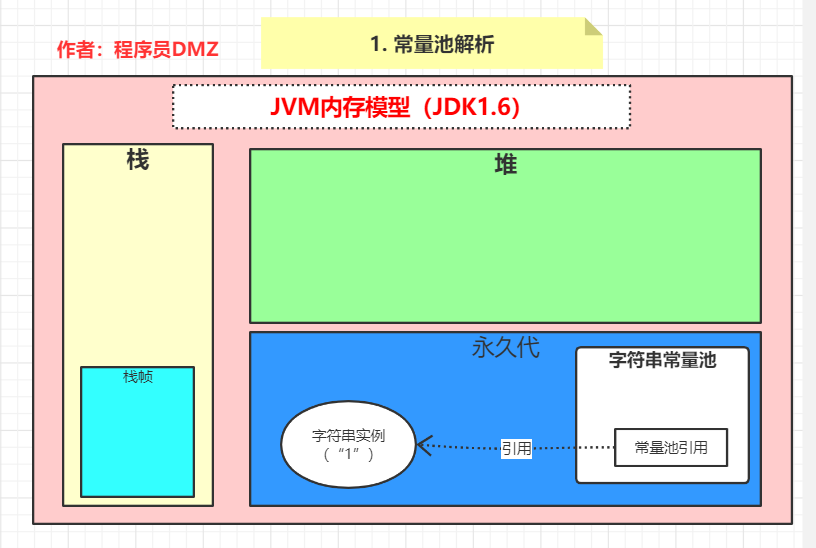
当真正通过 new 方式创建对象完成后,对应的内存状态如下,因为在分析class文件中的常量池的时候已经对栈区做了详细的分析,所以这里就省略一些细节了,在执行完这行代码后,栈区存在一个引用,指向 了堆区的一个字符串实例内存状态对应如下:
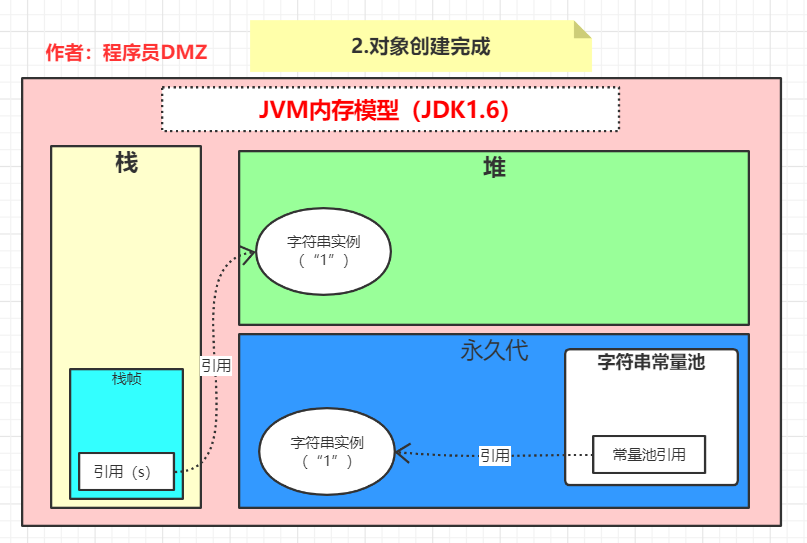
第二步:紧接着,我们调用了 s 的 intern 方法,对应代码就是s.intern()
当 intern 方法执行时,因为此时字符串常量池中已经存在了一个字面量信息跟 s 相同的字符串的引用,所以此时内存状态不会发生任何改变。
第三步:执行String s2 = "1",此时因为常量池中已经存在了字面量 1 的对应字符串实例的引用,所以,这里就直接返回了这个引用并且赋值给了局部变量 s2。对应的内存状态如下:
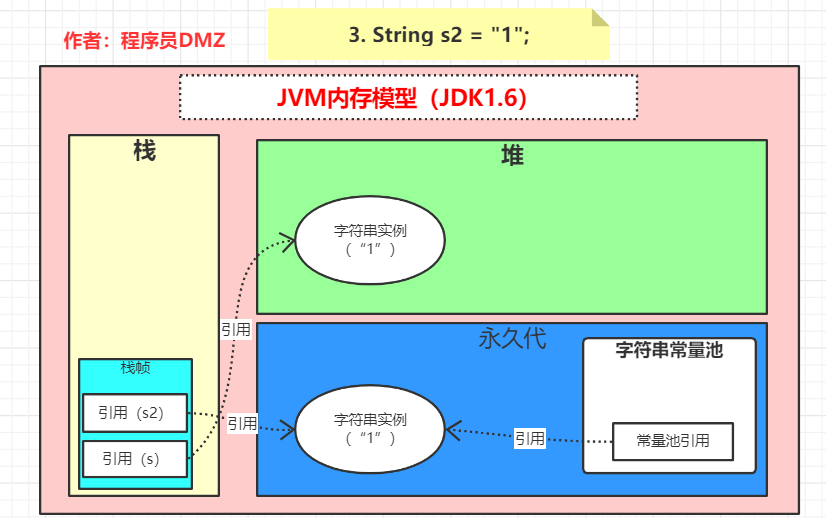
到这里就很清晰了,s 跟 s2 指向两个不同的对象,所以 s==s2 肯定是 false 嘛~
如果看过美团那篇文章的同学可能会有些疑惑,我在图中对常量池的描述跟美团文章图中略有差异,在美团那篇文章中,直接将具体的字符串实例放到了字符串常量池中,而在我上面的图中,字符串常量池存的永远时引用,它的图是这样画的
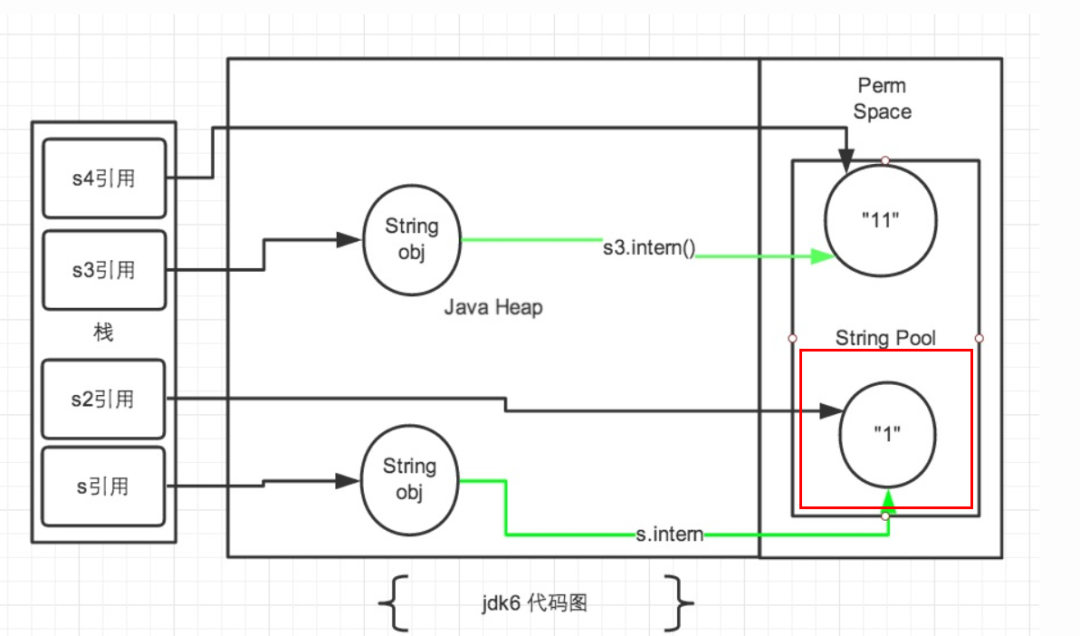
就我查阅的资料而言,我个人不赞同这种说法,常量池中应该保存的仅仅是引用。关于这个问题,我已经向美团的团队进行了留言,也请大佬出来纠错!
接着我们分析 s3 跟 s4,对应的就是这几行代码:
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
我们一行行分析,看看执行完后,内存的状态是什么样的
第一步:String s3 = new String("1") + new String("1"),执行完成后,堆区多了两个匿名对象,这个我们不用多关注,另外堆区还多了一个字面量为 11 的字符串实例,并且栈中存在一个引用指向这个实例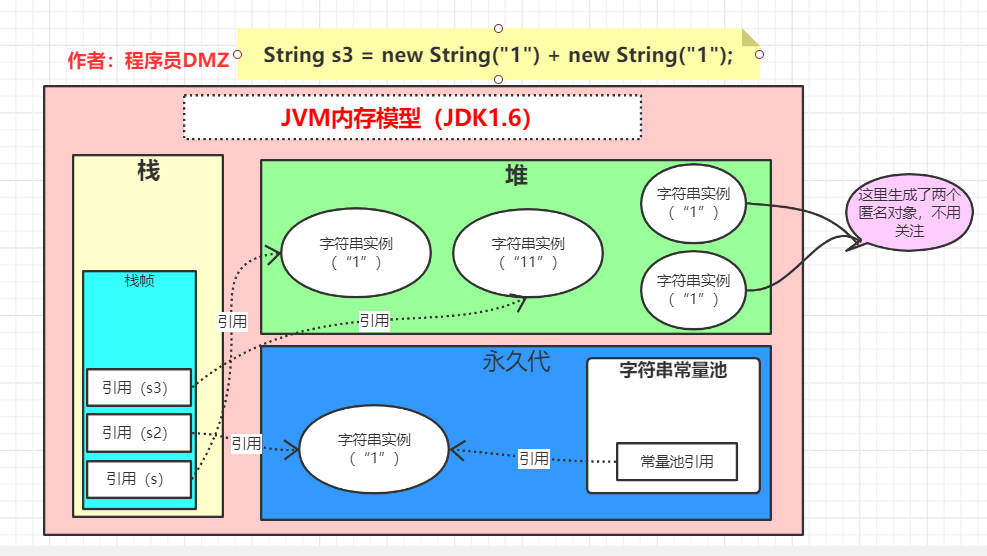 实际上上图中还少了一个匿名的
实际上上图中还少了一个匿名的StringBuilder的对象,这是因为当我们在进行字符串拼接时,编译器默认会创建一个StringBuilder对象并调用其append方法来进行拼接,最后再调用其toString方法来转换成一个字符串,StringBuilder的toString方法其实就是 new 一个字符串
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
这也是为什么在图中会说在堆上多了一个字面量为 11 的字符串实例的原因,因为实际上就是 new 出来的嘛!
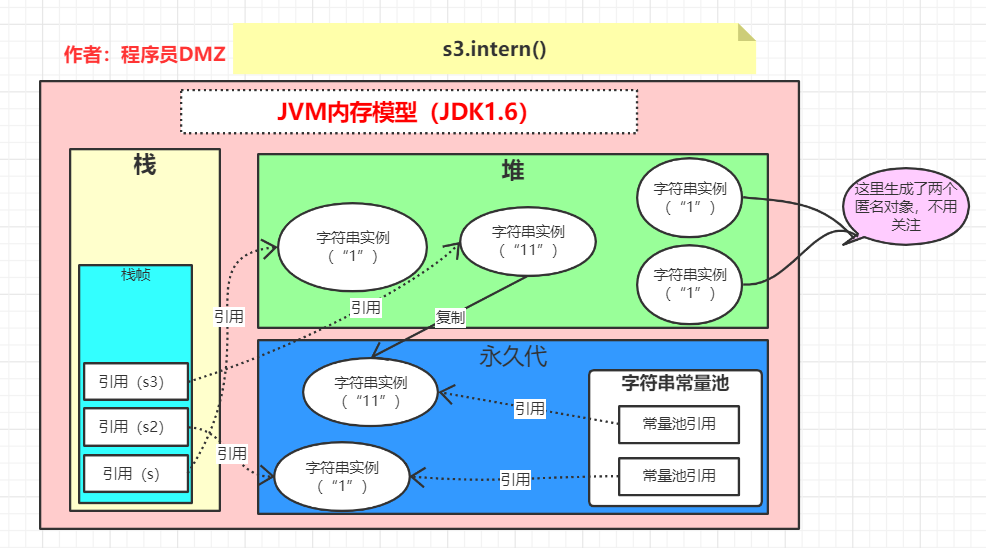
第二步:s3.intern()
调用intern方法后,因为字符串常量池中目前没有 11 这个字面量对应的字符串实例的应用,所以 JVM 会先从堆区复制一个字符串实例到永久代中,再将其引用添加到字符串常量池中,最终的内存状态就如下所示
第三步:String s4 = "11"
这应该没啥好说的了吧,常量池中有了,直接指向对应的字符串实例
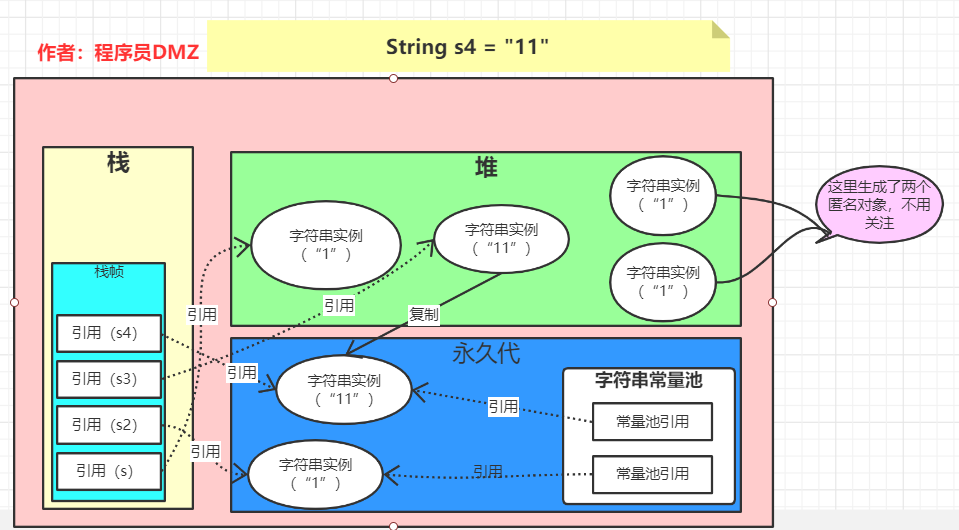
到这里可以发现,s3 跟 s4 指向的根本就是两个不同的对象,所以也返回 false
jdk7 执行流程
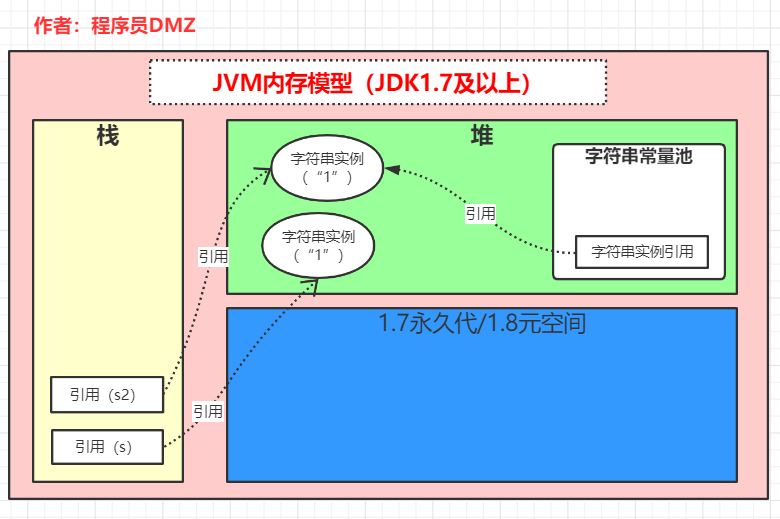
在 jdk1.7 中,s 跟 s2 的执行结果还是一样的,这是因为 String s = new String("1")这行代码本身就创建了两个字符串对象,一个属于被常量池引用的驻留字符串,而另外一个只是堆上的一个普通字符串对象。跟 1.6 的区别在于,1.7 中的驻留字符串位于堆上,而 1.6 中的位于方法区中,但是本质上它们还是两个不同的对象,在下面代码执行完后
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
内存状态为:
但是对于 s3 跟 s4 确不同了,因为在 jdk1.7 中不会再去复制字符串实例了,在 intern 方法执行时在发现堆上有对应的对象之后,直接将这个对应的引用添加到字符串常量池中,所以代码执行完,内存状态对应如下:
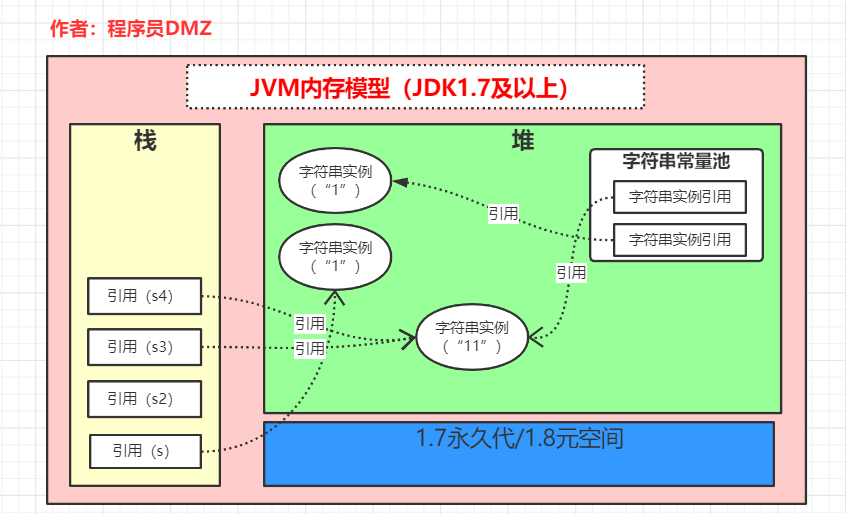
看到了吧,s3 跟 s4 指向的同一个对象,这是因为 intern 方法执行时,直接 s3 这个引用复制到了常量池,之后执行String s4= "11"的时候,直接再将常量池中的引用复制给了 s4,所以 s3==s4 肯定为 true 啦。
在理解了它们之间的差异之后,我们再来思考一个问题,假设我现在将代码改成这个样子,那么运行结果是什么样的呢?
public static void main(String[] args) {
String s = new String("1");
String sintern = s.intern();
String s2 = "1";
System.out.println(sintern == s2);
String s3 = new String("1") + new String("1");
String s3intern = s3.intern();
String s4 = "11";
System.out.println(s3intern == s4);
}
上面这段代码运行起来结果会有差异吗?大家可以自行思考~
在我们对字符串常量池有了一定理解之后会发现,其实通过String name = "dmz"这行代码申明一个字符串,实际的执行逻辑就像下面这段伪代码所示
/**
* 这段代码逻辑类比于
* String s = "字面量";这种方式申明一个字符串
* 其中字面量就是在""中的值
*
*/
public String declareString(字面量) {
String s;
// 这是一个伪方法,标明会根据字面量的值到字符串值中查找是否存在对应String实例的引用
s = findInStringTable(字面量);
// 说明字符串池中已经存在了这个引用,那么直接返回
if (s != null) {
return s;
}
// 不存在这个引用,需要新建一个字符串实例,然后调用其intern方法将其拘留到字符串池中,
// 最后返回这个新建字符串的引用
s = new String(字面量);
// 调用intern方法,将创建好的字符串放入到StringTable中,
// 类似就是调用StringTable.add(s)这也的一个伪方法
s.intern();
return s;
}
按照这个逻辑,我们将我们将上面思考题中的所有字面量进行替换,会发现不管在哪个版本中结果都应该返回 true。
运行时常量池
位置在哪?
位于方法区中,1.6 在永久代,1.7 在元空间中,永久代跟元空间都是对方法区的实现
用来干什么?
jvm 在执行某个类的时候,必须经过加载、连接、初始化,而连接又包括验证、准备、解析三个阶段。而当类加载到内存中后,jvm 就会将 class 常量池中的内容存放到运行时常量池中,由此可知,运行时常量池也是每个类都有一个。在上面我也说了,class 常量池中存的是字面量和符号引用,也就是说他们存的并不是对象的实例,而是对象的符号引用值。而经过解析(resolve)之后,也就是把符号引用替换为直接引用,解析的过程会去查询全局字符串池,也就是我们上面所说的StringTable,以保证运行时常量池所引用的字符串与全局字符串池中所引用的是一致的。
所以简单来说,运行时常量池就是用来存放 class 常量池中的内容的。
总结
我们将三者进行一个比较
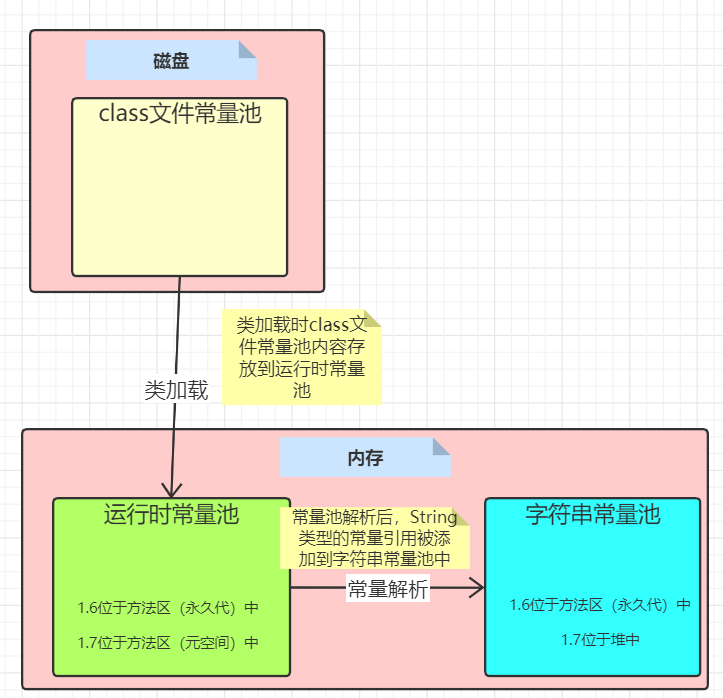
以一道测试题结束
// 环境1.7及以上
public class Clazz {
public static void main(String[] args) {
String s1 = new StringBuilder().append("ja").append("va1").toString();
String s2 = s1.intern();
System.out.println(s1==s2);
String s5 = "dmz";
String s3 = new StringBuilder().append("d").append("mz").toString();
String s4 = s3.intern();
System.out.println(s3 == s4);
String s7 = new StringBuilder().append("s").append("pring").toString();
String s8 = s7.intern();
String s6 = "spring";
System.out.println(s7 == s8);
}
}
答案是 true,false,true。大家可以仔细思考为什么,如有疑惑可以给我留言,或者进群交流!
我叫 DMZ,一个在学习路上匍匐前行的小菜鸟!
参考文章:
R 大博文:请别再拿“String s = new String("xyz");创建了多少个 String 实例”来面试了吧
R 大知乎回答:JVM 常量池中存储的是对象还是引用呢?[2]
Java 中几种常量池的区分[3]
方法区,永久代和元空间[4]
美团:深入解析 String#intern[5]
参考书籍:
《深入理解 Java 虚拟机》第二版
《深入理解 Java 虚拟机》第三版
《Java 虚拟机规范》
参考资料
深入解析 String#intern: https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html
[2]JVM 常量池中存储的是对象还是引用呢?: https://www.zhihu.com/question/57109429/answer/151717241
[3]Java 中几种常量池的区分: http://tangxman.github.io/2015/07/27/the-difference-of-java-string-pool/
[4]方法区,永久代和元空间: https://www.jianshu.com/p/1b61feb2e336
[5]深入解析 String#intern: https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html