目标跟踪 (Object Tracking) 是机器视觉领域的重要课题,根据跟踪目标的数量,可分为单目标跟踪 (Single Object Tracking,简称 SOT) 和多目标跟踪 (Multi Object Tracking,简称 MOT)。多目标跟踪往往因为跟踪 ID 众多、遮挡频繁等,容易出现目标跟丢的现象。借助跟踪器 DeepSORT 与检测器 YOLO v5,可以打造一个高性能的实时多目标跟踪模型。本文将对单目标跟踪和多目标跟踪分别进行介绍,文末将详解 YOLO v5+DeepSORT 的实现过程及具体代码。
单目标跟踪 SOT 是指在视频首帧给出目标,根据上下文信息,在后续帧定位出目标位置,建立跟踪模型对目标的运动状态进行预测。SOT 在智能视频监控、自动驾驶、机器人导航、人机交互等领域应用广泛。足球比赛中利用 SOT 预测足球运动轨迹
最主要的三个难点:目标背景的变化、物体本身的变化、光照强度变化。解决 SOT 问题主要有两种方法:判别式跟踪及生成式跟踪,随着深度学习在图像分类、目标检测等机器视觉相关任务中的成功应用,深度学习也开始大量应用于目标跟踪算法中。本文主要围绕基于深度学习的 SOT 算法进行介绍。各时间节点的代表性目标跟踪算法
2012 年后以 AlexNet 为代表的深度学习方法
被引入到目标跟踪领域中
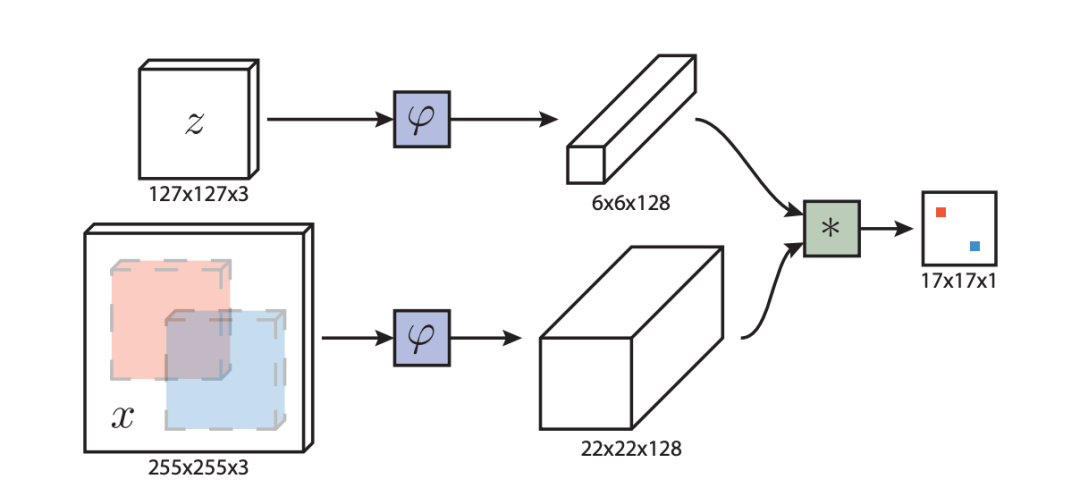
与传统目标跟踪中所用的在线学习方法不同,SiamFC 侧重于在离线阶段学习强嵌入。它将一个基本跟踪算法,与一个在 ILSVRC15 数据集上进行端到端训练的新型全卷积孪生网络 (fully-convolutional Siamese network) 相结合,用于视频中的目标检测。实验证明,在模型测试和训练期间,孪生全卷积深度网络对已有数据的利用更加高效。SiamFC 开创了将孪生网络结构应用于目标跟踪领域的先河,显著提高了深度学习方法跟踪器的跟踪速度,结构简单性能优异。https://arxiv.org/pdf/1606.09549.pdf
提出了 local structure learning method,同时考虑目标的 local pattern 和结构关系。为此,作者设计了一个局部模式检测模块,来自动识别目标物体的辨别区域。https://openaccess.thecvf.com/content_ECCV_2018/papers/Yunhua_Zhang_Structured_Siamese_Network_ECCV_2018_paper.pdf作者提出了一种全新的 triplet loss,用于提取跟踪物体的 expressive deep feature。在不增加输入的情况下,该方法可以利用更多元素进行训练,通过组合原始样本,实现更强大的特征。https://openaccess.thecvf.com/content_ECCV_2018/papers/Xingping_Dong_Triplet_Loss_with_ECCV_2018_paper.pdf作者提出了动态孪生网络,通过一个快速转换学习模型,能够有效地在线学习目标的外观变化和先前帧的背景压制。同时作者还提出了元素多层融合,利用多层深度特征自适应地整合网络输出。DSiam 允许使用任何可行的通用或经过特殊训练的特征,如 SiamFC 和 VGG,且动态孪生网络可以直接在标记的视频序列上进行整合训练,充分利用移动物体丰富的时空信息。https://openaccess.thecvf.com/content_ICCV_2017/papers/Guo_Learning_Dynamic_Siamese_ICCV_2017_paper.pdf多目标跟踪(MOT)是指对视频中每一帧的物体都赋予一个 ID,并将每个 ID 的行为轨迹画出来。在街景视频中进行多目标跟踪
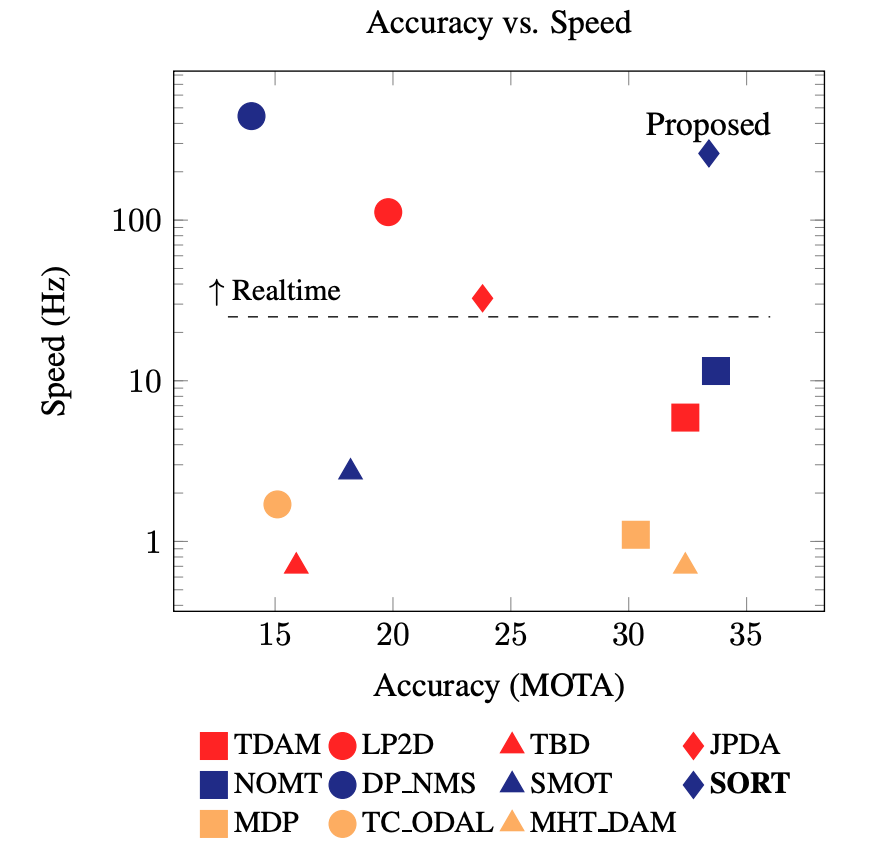
MOT 在智能安防、自动驾驶、医学场景等领域,都有广泛应用。MOT 目前遇到的最大挑战就是遮挡 (Occlusion),即目标之间的彼此遮挡或环境对目标产生的遮挡。Simple Online and Realtime Tracking (SORT) 是一种专注简单高效算法的多目标跟踪方法,它非常实用,可以为在线和实时应用,有效地关联目标。SORT 只是将常见技术(如卡尔曼滤波、匈牙利算法)进行了简单组合,准确率可与当时最先进的在线跟踪器相提并论。SORT 与其他方法的性能比较
横轴表示准确率,纵轴表示速度
模型位置越高、越靠右,综合表现越佳
由于跟踪方法简单易用,跟踪器的更新速度达到了 260 Hz,比当时最先进的跟踪器快 20 倍。
https://arxiv.org/pdf/1602.00763.pdf
DeepSORT 是 SORT 的升级版,它整合了外观信息 (appearance information) 从而提高 SORT 的性能,这使得我们在遇到较长时间的遮挡时,也能够正常跟踪目标,并有效减少 ID 转换的发生次数。DeepSORT 在 MOT Challenge 数据集上的表现
真实街景中遮挡情况非常常见
作者将绝大部分的计算复杂度,都放到了离线预训练阶段,在这个阶段会用一个大规模行人重识别数据集,学习深度关联度量 (deep association metric)。在在线应用阶段,则使用视觉外观空间 (visual appearance space) 中的近邻查询,来建立 measurement-to-track 关联。实验表明,DeepSORT 使得 ID 转换的次数减少了 45%,在高帧率下整体性能优秀。此外 DeepSORT 是一个非常通用的跟踪器,可以被接在任何一个检测器上。https://arxiv.org/pdf/1703.07402.pdf作者提出了一个 MOT 系统,使得目标检测和外观嵌入得以在一个共享模型中学习。也就是说把外观嵌入模型纳入一个 single-shot 检测器中,使该模型可以同时输出检测以及对应的嵌入。作者还进一步提出了一个简单快速的关联方法,可以与联合模型 (joint model) 一起运行。Towards Real-Time MOT 与 SDE 模型与之前的 MOT 系统相比,这两个组件的计算成本都大大降低了,为实时 MOT 算法设计的后续工作,提供了一个整洁快速的基线。这是业内第一个接近实时的 MOT 系统,它的运行速度更快、精度更高、代码也已开源,非常值得参考。https://arxiv.org/pdf/1909.12605v1.pdf该教程在 OpenBayes.com 运行。OpenBayes 是一个开箱即用的机器学习算力云平台,提供 PyTorch、TensorFlow 等主流框架,以及 vGPU、T4、V100 等多种类型的算力方案,计价模式灵活简单,按使用时长收费。本教程选用 vGPU 在 PyTorch 1.8.1 环境中运行。https://openbayes.com/console/open-tutorials/containers/BvxvYMbdefV/overview本项目包括两个部分,首先是 YOLO v5 检测器,用于检测出一系列物体;然后用 DeepSORT 进行跟踪。%cd Yolov5_DeepSort_Pytorch%pip install -qr requirements.txt
import torchfrom IPython.display import Image, clear_output
clear_output()print(f"Setup complete. Using torch {torch.__version__} ({torch.cuda.get_device_properties(0).name if torch.cuda.is_available() else 'CPU'})")
!y | ffmpeg -ss 00:00:00 -i test.avi -t 00:00:03 -c copy out.avi -y
!python track.py --yolo_weights /openbayes/input/input1/crowdhuman_yolov5m.pt --source out.avi --save-vid
!ffmpeg -i /openbayes/home/Yolov5_DeepSort_Pytorch/inference/output/out.avi output.mp4 -y
from IPython.display import HTMLfrom base64 import b64encodemp4 = open('output.mp4','rb').read()data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("""<video controls> <source src="%s" type="video/mp4"></video>""" % data_url)
https://openbayes.com/console/open-tutorials/containers/BvxvYMbdefV/overview
编辑:于腾凯
校对:王欣