
多目标跟踪 | FairMOT:统一检测、重识别的多目标跟踪框架,全新Baseline
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:AI算法与图像处理

论文地址:https://arxiv.org/pdf/2004.01888v2.pdf
代码地址:https://github.com/ifzhang/FairMOT
这篇工作来自华中科技大学和微软亚洲研究院,从结果来看,这篇工作在主流的多目标跟踪数据集上几乎打败之前所有State-of-the-art算法,但标题却称该算法只是个baseline,而且是simple baseline,再次验证大佬们都是谦虚的。
多目标跟踪 (MOT) 是计算机视觉领域中的重要任务,近年来,目标检测和 Re-ID 在各自的发展中都取得巨大进步,并提升了目标跟踪的性能。但是,现有方法无法以视频帧速率执行推断,因为两个网络无法共享特征。当前多目标跟踪最优的方法通常分为两大类:
两步法MOT——使用两个单独的模型,首先用检测模型定位图像中目标的边界框位置,然后用关联模型对每个边界框提取重识别 (Re-identification, Re-ID) 特征,并根据这些特征定义的特定度量将边界框与现有的一个跟踪结果联结起来。其中检测模型中的目标检测是为了发现当前画面所有的目标,ReID则是将当前所有目标与之前帧的目标建立关联,然后可以通过ReID特征向量的距离比较和目标区域交并比(IOU)来通过使用卡尔曼滤波器和匈牙利算法建立关联。两步方法的优点在于,它们可以针对每个任务分别使用最合适的模型,而不会做出折衷。此外,他们可以根据检测到的边界框裁剪图像补丁,并在预测Re-ID功能之前将其调整为相同大小,这有助于处理对象的比例变化。
单步法MOT——在进行目标检测的同时也进行ReID特征提取,核心思想是在单个网络中同时完成对象检测和身份嵌入(Re-ID功能),以通过共享大部分计算来减少推理时间。现有的方法比如Track-RCNN、JDE(Towards real-time multi-object tracking)直接在Mask R-CNN、YOLOv3的检测端并行加入ReID特征向量输出。很显然这能节约计算时间,但作者研究发现此类方法存在目标ID关联不正确的问题。具体来说,该类方法使用了anchor-based 的目标检测,目标的ReID特征是在anchor区域提取的,anchor 和目标区域会出现不对齐的问题,这会导致网络训练时存在严重的歧义。

图1:(a)黄色和红色的锚点造成了估计相同的ID(穿蓝色衬衫的人),尽管图像块非常不同。此外,基于锚的方法通常在粗网格上运行。因此,很有可能在锚点(红色或黄色星形)提取的特征未与对象中心对齐。(b)免锚的做法受歧义的影响较小。
本文作者对影响跟踪器准确性的关键性因素做了以下的分析:
(1)基于Anchor锚点的方法不适合Re-ID
当前的单步法跟踪器都是基于anchor锚的,因为它们是从对象检测器修改而来的。但是,有两个原因造成了锚点不适合学习Re-ID功能。首先,对应于不同图像块的多个锚点可能负责估计同一个目标的 id,这导致严重的歧义(参见图 1)。此外,需要将特征图的大小缩小 1/8,以平衡准确率和速度。对于检测任务而言这是可以接受的,但对于 Re-ID 来说就有些粗糙了,因为目标中心可能无法与在粗糙锚点位置提取的特征一致。
文章中提出解决该问题的方法,是通过将MOT问题看作为在高分辨率特征图上的像素级关键点(目标中心)估计和 id 分类问题。
(2)多层特征聚合
这对于 MOT 问题尤其重要,因为 Re-ID 特征需要利用低级和高级特征来适应小型和大型目标。研究者通过实验发现,这对降低 one-shot 方法的 id 转换数量有所帮助,因为它提升了处理尺度变换的能力。
(3)ReID特征的维数
以前的ReID方法通常学习高维特征,并在其基准上取得了可喜的结果。但是,本文发现低维特征实际上对MOT更好,因为它的训练图像比ReID少(由于 Re-ID 数据集仅提供剪裁后的人像,因此 MOT 任务不使用此类数据集)。学习低维特征有助于减少过拟合小数据的风险,并提高跟踪的稳健性。
针对于第三点实际存在疑问,一开始公布的Fairmot版本用的reid分支是128维度的,但是后来作者团队在MOT20上刷出了MOTA58.7的指标,也更新了github上的Fairmot模型,这时候用的reid维度已经改为512维度,与通用的reid模型接近。但是在实验中发现reid上效果仍然在人员交集处容易跑其他人身上,应该是没有充分训练。
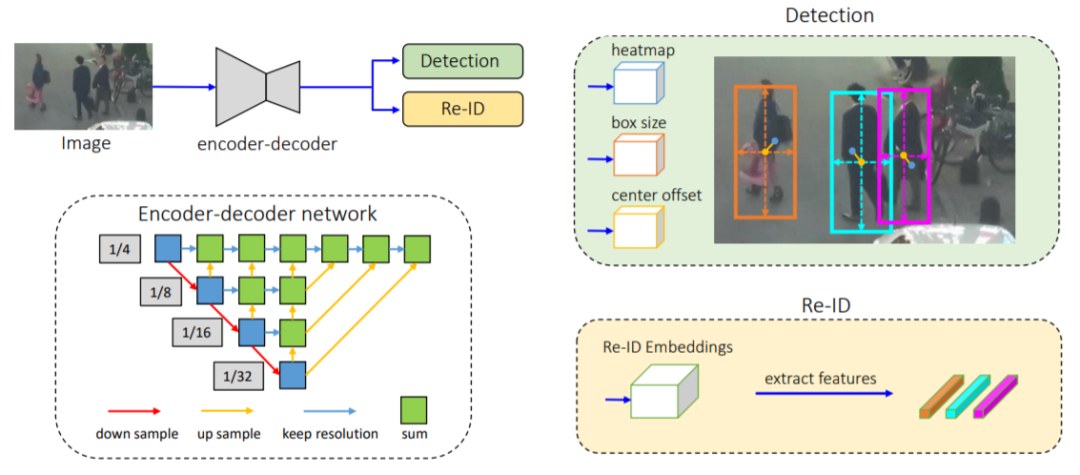
图 2:该研究提出的 one-shot MOT 跟踪器图示。首先将输入图像送入编码器-解码器网络,以提取高分辨率特征图(步幅=4);然后添加两个简单的并行 head,分别预测边界框和 Re-ID 特征;最后提取预测目标中心处的特征进行边界框时序联结。
然后,添加并行分支来估计像素级 Re-ID 特征,这类特征用于预测目标的 id。具体而言,学习既能减少计算时间又能提升特征匹配稳健性的低维 Re-ID 特征。在这一步中,本文用深层聚合算子(Deep Layer Aggregation,DLA)来改进主干网络 ResNet-34 ,从而融合来自多个层的特征,处理不同尺度的目标。
1、主干网络
采用ResNet-34 作为主干网络,以便在准确性和速度之间取得良好的平衡。为了适应不同规模的对象,如图2所示,将深层聚合(DLA)的一种变体应用于主干网络。
与原始DLA 不同,它在低层聚合和低层聚合之间具有更多的跳跃连接,类似于特征金字塔网络(FPN)。此外,上采样模块中的所有卷积层都由可变形的卷积层代替,以便它们可以根据对象的尺寸和姿势动态调整感受野。 这些修改也有助于减轻对齐问题。
2、物体检测分支
本方法中将目标检测视为高分辨率特征图上基于中心的包围盒回归任务。特别是,将三个并行回归头(regression heads)附加到主干网络以分别估计热图,对象中心偏移和边界框大小。 通过对主干网络的输出特征图应用3×3卷积(具有256个通道)来实现每个回归头(head),然后通过1×1卷积层生成最终目标。
Heatmap Head
这个head负责估计对象中心的位置。这里采用基于热图的表示法,热图的尺寸为1×H×W。 随着热图中位置和对象中心之间的距离,响应呈指数衰减。
Center Offset Head
该head负责更精确地定位对象。ReID功能与对象中心的对齐精准度对于性能至关重要。
Box Size Head
该部分负责估计每个锚点位置的目标边界框的高度和宽度,与Re-ID功能没有直接关系,但是定位精度将影响对象检测性能的评估。
3、id嵌入分支 Identity Embedding Branch
id嵌入分支的目标是生成可以区分不同对象的特征。理想情况下,不同对象之间的距离应大于同一对象之间的距离。为了实现该目标,本方法在主干特征之上应用了具有128个内核的卷积层,以提取每个位置的身份嵌入特征。
4、Loss Functions损失函数
Heatmap Loss:采用focal loss的形式

定义为具有focal loss的像素级逻辑回归( pixel-wise logistic regression)
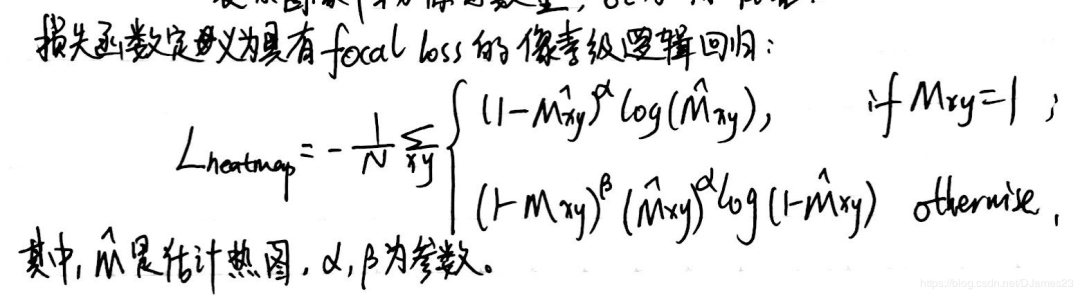
Offset and Size Loss:采用L1 loss

Identity Embedding Loss:参考交叉熵的形式
将对象id嵌入视为分类任务。特别是,训练集中具有相同标识的所有对象实例都被视为一个类。

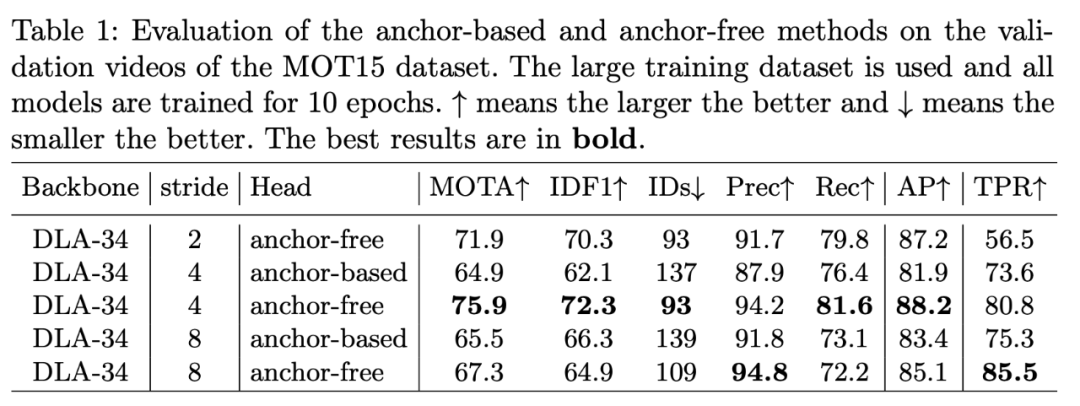
消融实验
2. 多层特征聚合
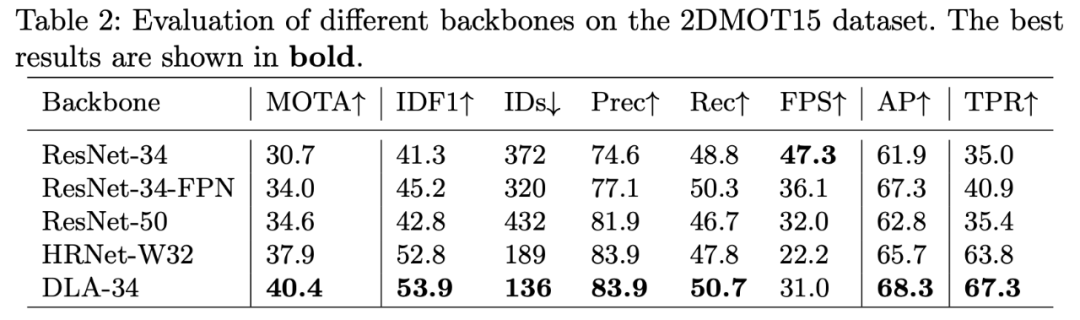
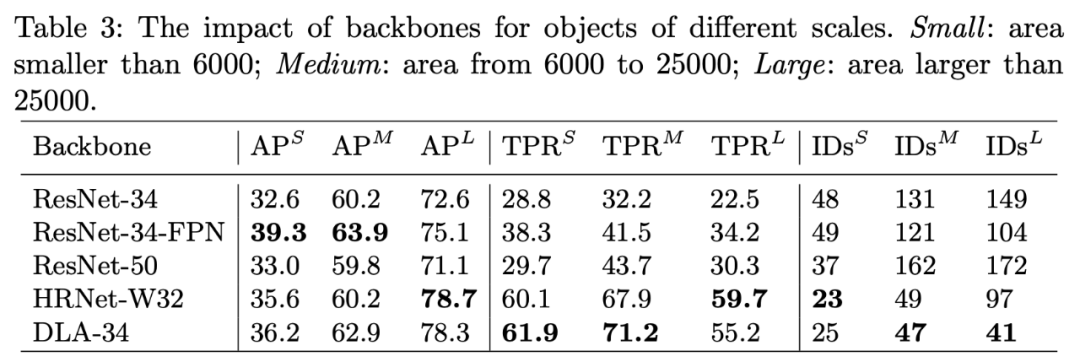
表 3:主干网络对不同尺度目标的影响。
3、Re-ID 特征维度
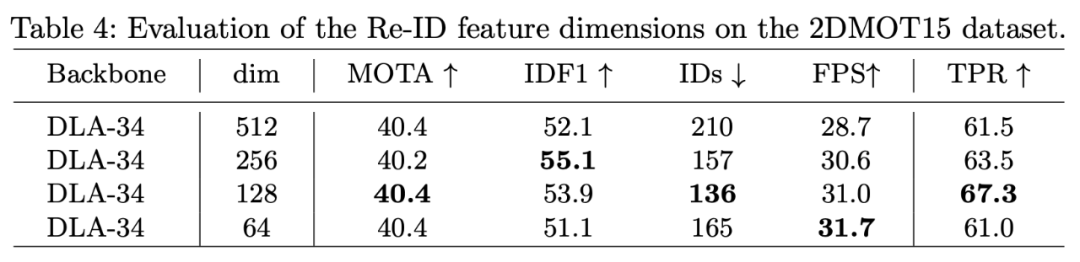
表 4:不同 Re-ID 特征维度在 2DMOT15 数据集上的评估结果
4、与当前最佳模型的比较
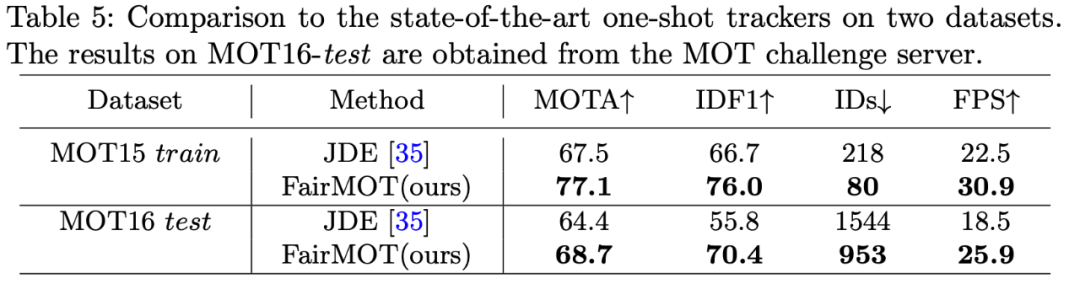
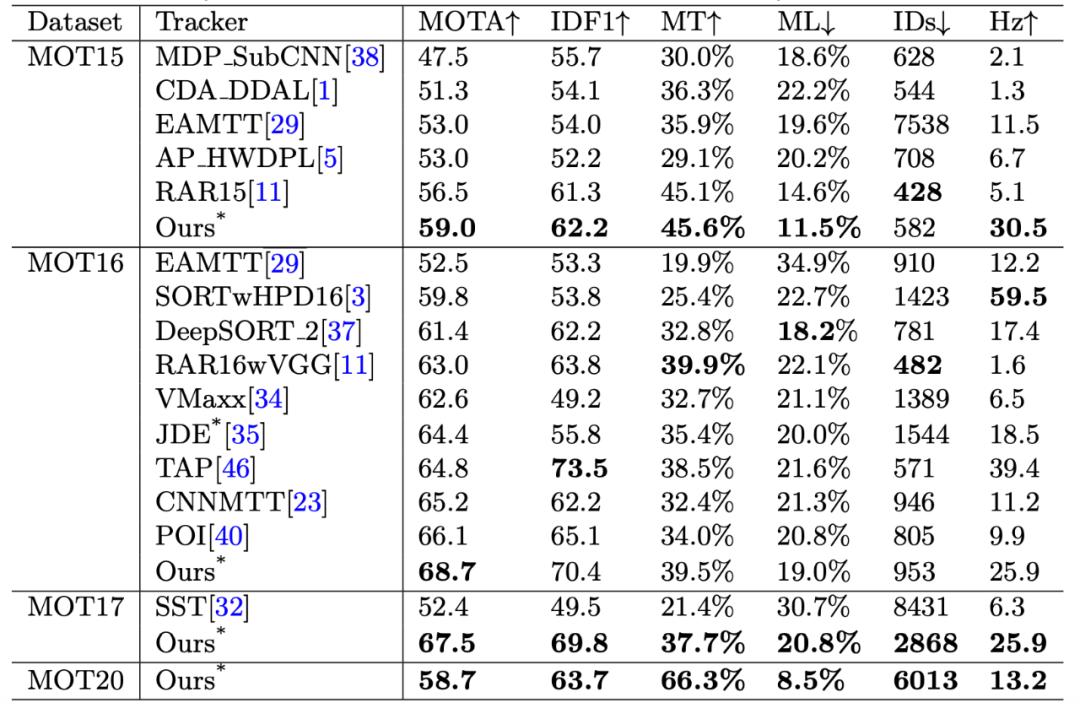
表 6:与「private detector」设定下的 SOTA 结果进行对比。

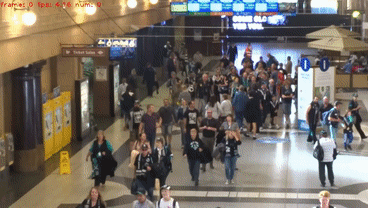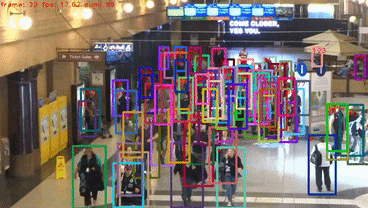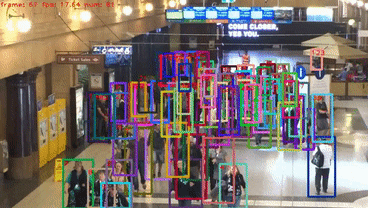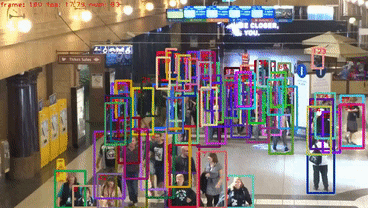
具体实验细节可以参考原文。
参考
https://blog.csdn.net/DJames23/article/details/105482419
https://blog.csdn.net/qq_34919792/article/details/106033055
https://zhuanlan.zhihu.com/p/126558285
https://zhuanlan.zhihu.com/p/127738264
https://cloud.tencent.com/developer/article/1616262
https://blog.csdn.net/sinat_33486980/article/details/105611295
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~