
多目标跟踪(MOT)入门
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
地址 | https://www.zhihu.com/people/longer-61-43
转自 | 新机器视觉
在科学研究中,从方法论上来讲,都应“先见森林,再见树木”。当前,人工智能学术研究方兴未艾,技术迅猛发展,可谓万木争荣,日新月异。对于AI从业者来说,在广袤的知识森林中,系统梳理脉络,才能更好地把握趋势。
最近做了一些多目标跟踪方向的调研,因此把调研的结果以图片加文字的形式展现出来,希望能帮助到入门这一领域的同学。也欢迎大家和我讨论关于这一领域的任何问题。
01

这些是我所了解的多目标跟踪(MOT)的一些相关方向。其中单目标跟踪(VOT/SOT)、目标检测(detection)、行人重识别(Re-ID)都是非常热门的方向。而偏视频的相关方向就比较冷门。而且今年五月DukeMTMC因为隐私问题不再提供MTMCT的数据了,MTMCT的研究也是举步维艰。
02
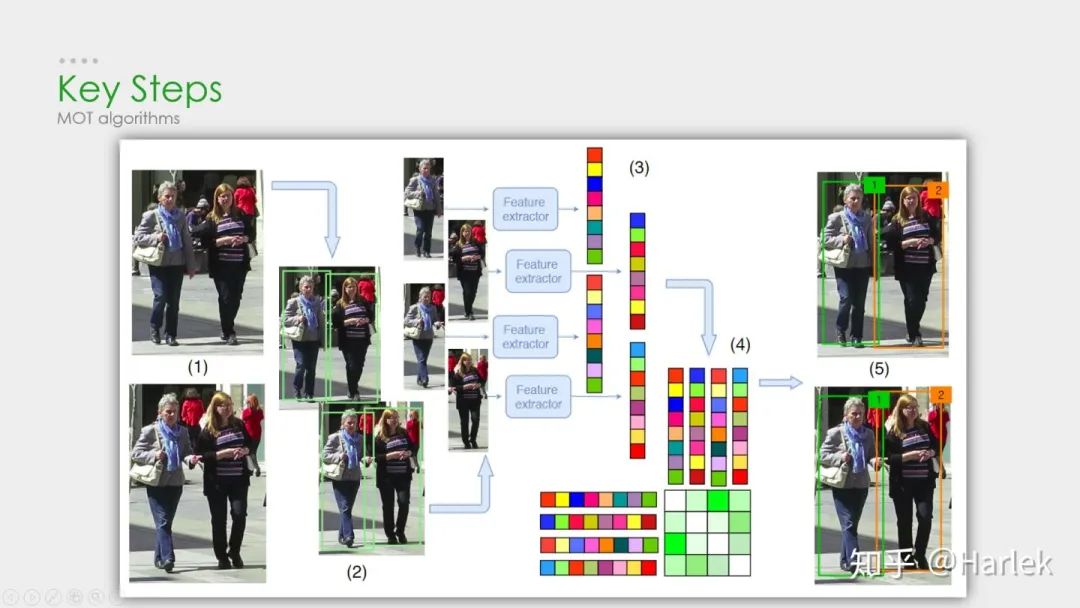
MOT算法的通常工作流程:
(1)给定视频的原始帧;
(2)运行对象检测器以获得对象的边界框;
(3)对于每个检测到的物体,计算出不同的特征,通常是视觉和运动特征;
(4)之后,相似度计算步骤计算两个对象属于同一目标的概率;
(5)最后,关联步骤为每个对象分配数字ID。
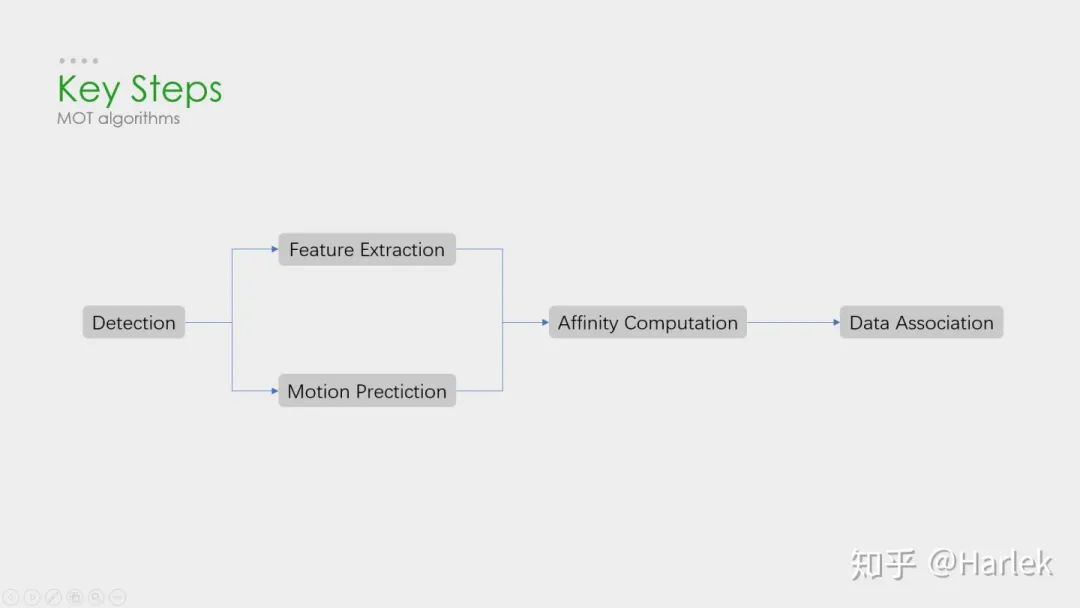
因此绝大多数MOT算法无外乎就这四个步骤:
①检测
②特征提取、运动预测
③相似度计算
④数据关联。
其中影响最大的部分在于检测,检测结果的好坏对于最后指标的影响是最大的。
但是,多目标追踪的研究重点又在相似度计算和数据关联这一块。所以就有一个很大的问题:你设计出更好的关联算法可能就提升了0.1个点,但别人用一些针对数据集的trick消除了一些漏检可能就能涨好几个点。所以研究更好的数据关联的回报收益很低。因此多目标追踪这一领域虽然工业界很有用,但学术界里因为指标数据集的一些原因,入坑前一定要三思。
03

关于评价指标:
第一个是传统的标准,现在已经没人用了,就不介绍了。
第二个是06年提出的CLEAR MOT。现在用的最多的就是MOTA。但是这个指标FN、FP的权重占比很大,更多衡量的是检测的质量,而不是跟踪的效果。
第三个是16年提出的ID scores。因为都是基于匹配的指标,所以能更好的衡量数据关联的好坏。
04

数据集用的最多的是MOTChallenge,专注于行人追踪的。
第二个KITTI的是针对自动驾驶的数据集,有汽车也有行人,在MOT的论文里用的很少。
还有一些其他比较老的数据集现在都不用了。
15年的都是采集的老的数据集的视频做的修正。
16年的是全新的数据集,相比于15年的行人密度更高、难度更大。特别注意这个DPM检测器,效果非常的差,全是漏检和误检。
17年的视频和16年一模一样,只是提供了三个检测器,相对来说更公平。也是现在论文的主流数据集。
19年的是针对特别拥挤情形的数据集,只有CVPR19比赛时才能提交。

这个是MOT16公开检测器上的结果。可以看到从17年开始,MOTA就涨的很慢了。关注一下这个帧率有20Hz的算法MOTDT也是我后面要讲的一个。
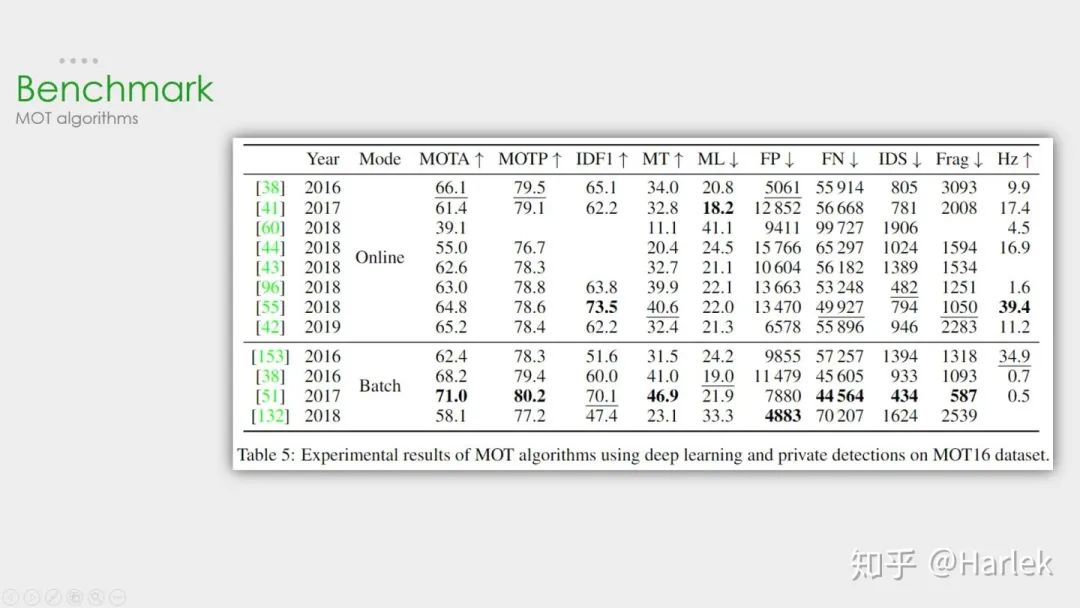
这个是MOT16私有检测器上的结果。可以看到检测器性能的好坏对于结果的影响非常重要。SOTA算法换了私有检测器后性能直接涨了快20个点。

这个是MOT17公开检测器上这几年比较突出的算法。注意因为这个数据集用了三个检测器,所以FP、FN这些指标也都几乎是16数据集的三倍。
05
SORT和DeepSORT
关键算法
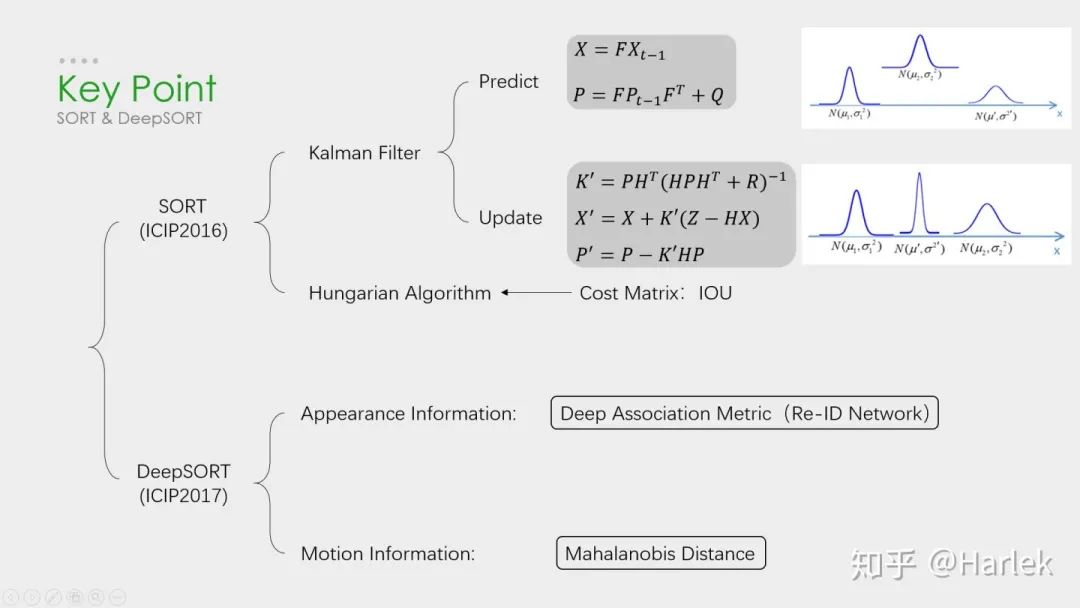
从这两个工业界关注度最高的算法说起。
SORT作为一个粗略的框架,核心就是两个算法:卡尔曼滤波和匈牙利匹配。
卡尔曼滤波分为两个过程:预测和更新。预测过程:当一个小车经过移动后,且其初始定位和移动过程都是高斯分布时,则最终估计位置分布会更分散,即更不准确;更新过程:当一个小车经过传感器观测定位,且其初始定位和观测都是高斯分布时,则观测后的位置分布会更集中,即更准确。
匈牙利算法解决的是一个分配问题。SK-learn库的linear_assignment_和scipy库的linear_sum_assignment都实现了这一算法,只需要输入cost_matrix即代价矩阵就能得到最优匹配。不过要注意的是这两个库函数虽然算法一样,但给的输出格式不同。具体算法步骤也很简单,是一个复杂度  的算法。
的算法。
DeepSORT的优化主要就是基于匈牙利算法里的这个代价矩阵。它在IOU Match之前做了一次额外的级联匹配,利用了外观特征和马氏距离。
外观特征就是通过一个Re-ID的网络提取的,而提取这个特征的过程和NLP里词向量的嵌入过程(embedding)很像,所以后面有的论文也把这个步骤叫做嵌入(起源应该不是NLP,但我第一次接触embedding是从NLP里)。然后是因为欧氏距离忽略空间域分布的计算结果,所以增加里马氏距离作为运动信息的约束。
SORT
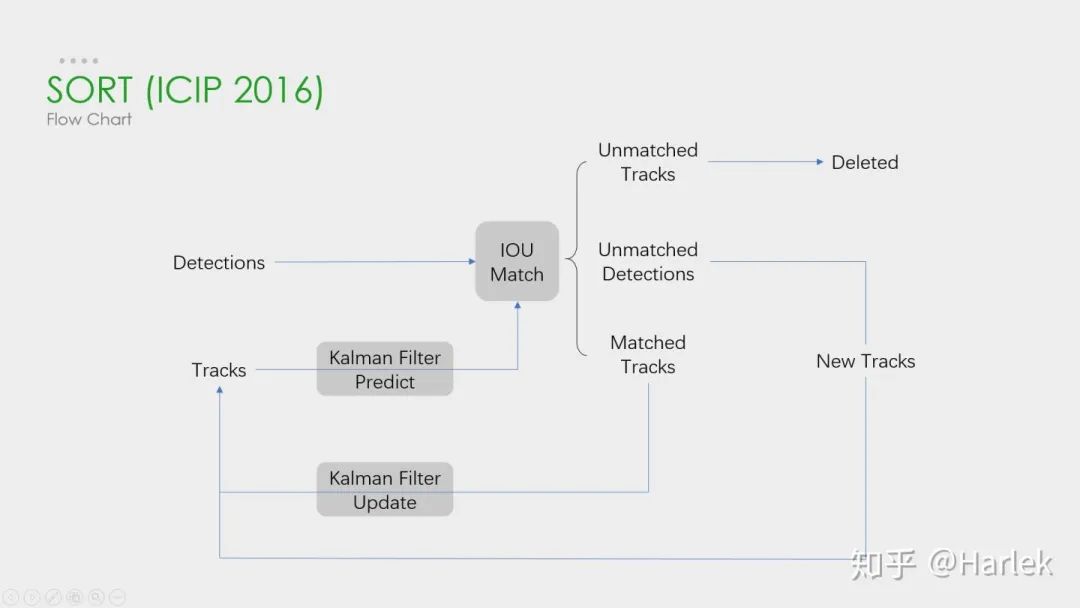
这个SORT的流程图非常重要,可以看到整体可以拆分为两个部分,分别是匹配过程和卡尔曼预测加更新过程,都用灰色框标出来了。一定要把整个流程弄明白。后面的多目标追踪的大框架基本都由此而来。
关键步骤:轨迹卡尔曼滤波预测→ 使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(IOU匹配) → 卡尔曼滤波更新
对于没有匹配上的轨迹,也不是马上就删掉了,有个T_lost的保存时间,但SORT里把这个时间阈值设置的是1,也就是说对于没匹配上的轨迹相当于直接删了。
关于这点论文里的原话是:
首先,恒定速度模型不能很好地预测真实的动力学,其次,我们主要关注的是帧到帧的跟踪,其中对象的重新识别超出了本文的范围。
这篇文章的机翻在《SORT》论文翻译
http://www.harlek.cn/2019/12/06/sort-lun-wen-fan-yi/
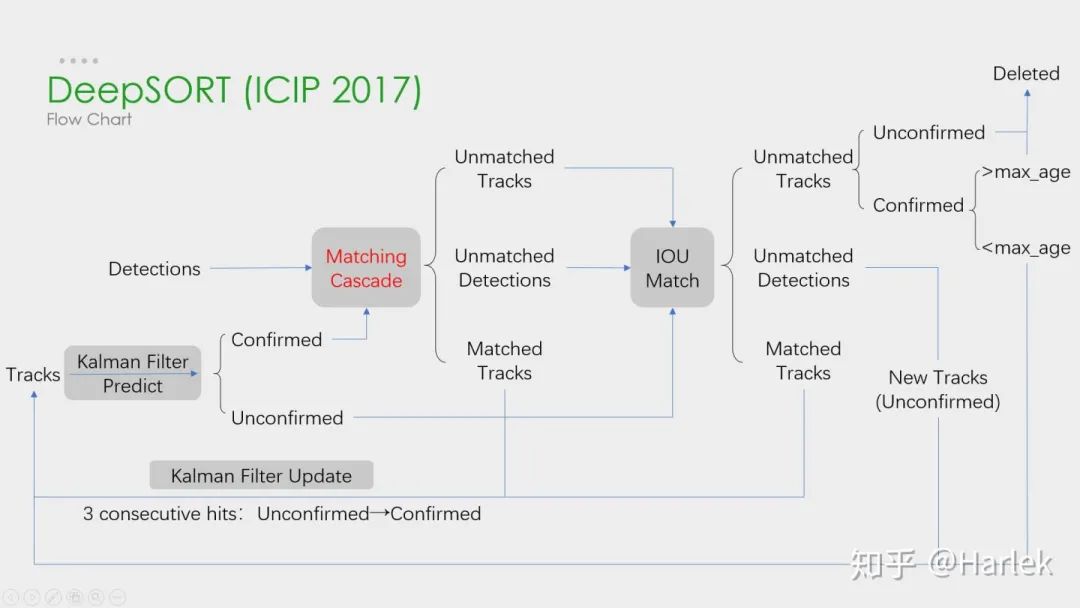
这是DeepSORT算法的流程图,和SORT基本一样,就多了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。
这篇文章的机翻在《DeepSORT》论文翻译
http://www.harlek.cn/2019/12/06/deepsort-lun-wen-fan-yi/
关键步骤:轨迹卡尔曼滤波预测→ 使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(级联匹配和IOU匹配) → 卡尔曼滤波更新
级联匹配是核心,就是红色部分,DeepSORT的绝大多数创新点都在这里面,具体过程看下一张图。
关于为什么新轨迹要连续三帧命中才确认?个人认为有这样严格的条件和测试集有关系。因为测试集给的检测输入非常的差,误检有很多,因此轨迹的产生必须要更严格的条件。
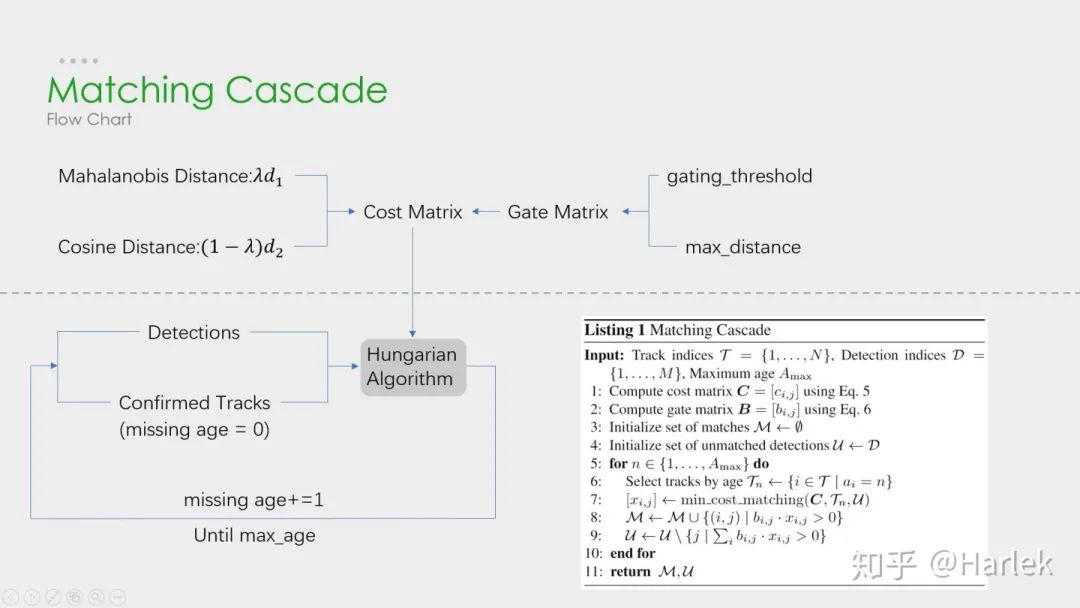
级联匹配流程图里上半部分就是特征提取和相似度估计,也就是算这个分配问题的代价函数。主要由两部分组成:代表运动模型的马氏距离和代表外观模型的Re-ID特征。
级联匹配流程图里下半部分数据关联作为流程的主体。为什么叫级联匹配,主要是它的匹配过程是一个循环。从missing age=0的轨迹(即每一帧都匹配上,没有丢失过的)到missing age=30的轨迹(即丢失轨迹的最大时间30帧)挨个的和检测结果进行匹配。也就是说,对于没有丢失过的轨迹赋予优先匹配的权利,而丢失的最久的轨迹最后匹配。
论文关于参数λ(运动模型的代价占比)的取值是这么说的:
在我们的实验中,我们发现当相机运动明显时,将λ= 0设置是一个合理的选择。
因为相机抖动明显,卡尔曼预测所基于的匀速运动模型并不work,所以马氏距离其实并没有什么作用。但注意也不是完全没用了,主要是通过阈值矩阵(Gate Matrix)对代价矩阵(Cost Matrix)做了一次阈值限制。
关于DeepSORT算法的详细代码解读我比较推荐:目标跟踪初探(DeepSORT)
https://zhuanlan.zhihu.com/p/90835266
但关于卡尔曼滤波的公式讲的不是很详细,具体推导可以看看 Kalman Filter 卡尔曼滤波
http://www.harlek.cn/2019/12/02/qia-er-man-lu-bo/
改进策略
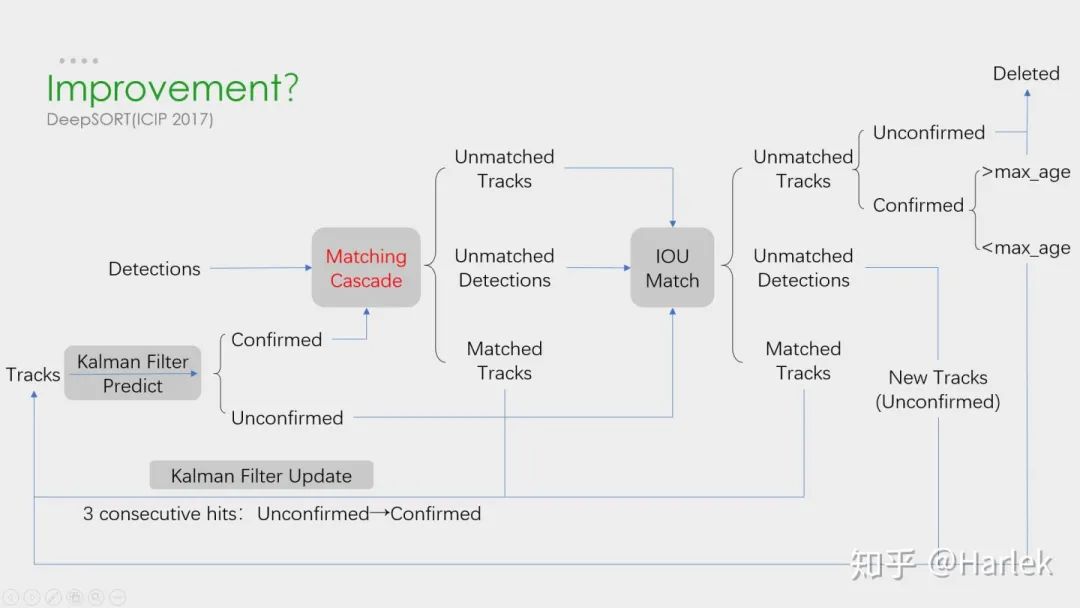
看到这个DeepSORT的流程图不知道大家可以想到什么优化的地方?其实有几个点是很容易想到的。

第一点,把Re-ID网络和检测网络融合,做一个精度和速度的trade off;
第二点,对于轨迹段来说,时间越长的轨迹是不是更应该得到更多的信任,不仅仅只是级联匹配的优先级,由此可以引入轨迹评分的机制;
第三点,从直觉上来说,检测和追踪是两个相辅相成的问题,良好的追踪可以弥补检测的漏检,良好的检测可以防止追踪的轨道飘逸,用预测来弥补漏检这个问题在DeepSORT里也并没有考虑;
第四点,DeepSORT里给马氏距离也就是运动模型设置的系数为0,也就是说在相机运动的情况下线性速度模型并不work,所以是不是可以找到更好的运动模型。
06
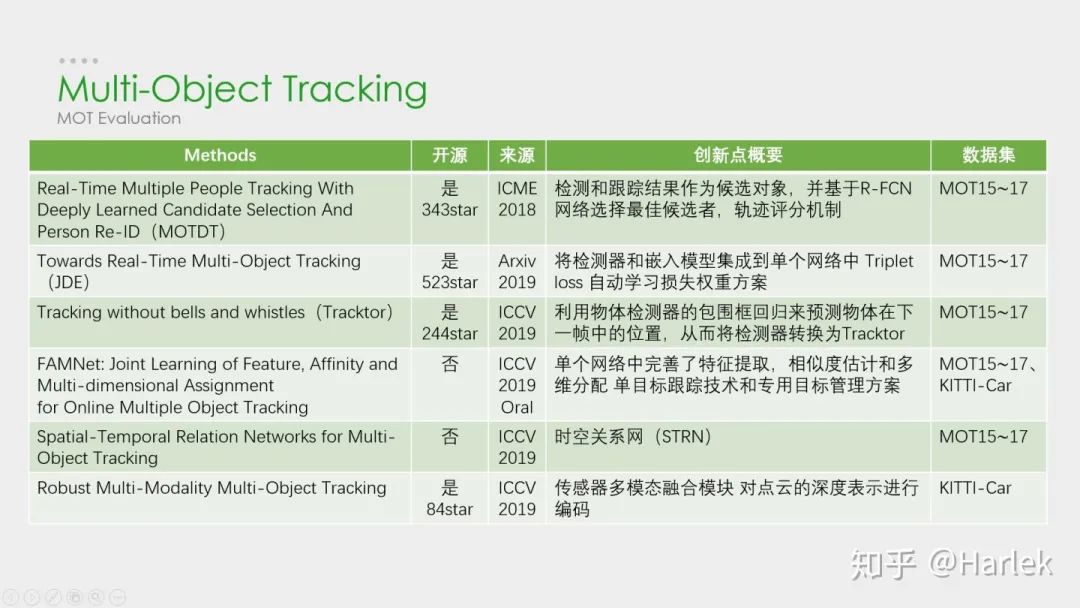
这是最近比较新的一些方法。
工业界青睐的算法在学术界其实并不重视,一方面是因为开源的原因,另一方面可以看到顶会的算法都不是注重速度的,通常用了很复杂的模块和trick来提升精度。
而且这些trick不是一般意义的trick了,是针对这个数据集的或者说针对糟糕检测器的一些trick, 对于实际应用几乎没有帮助。
第一篇论文是基于DeepSORT改进的,它的创新点在于引入了轨迹评分机制,时间越久的轨迹可信度就越高,基于这个评分就可以把轨迹产生的预测框和检测框放一起做一个NMS,相当于是用预测弥补了漏检。
第二篇论文是今年9月份发在arxiv上的一篇论文,它的工作是把检测网络和嵌入网络结合起来,追求的是速度和精度的trade off。
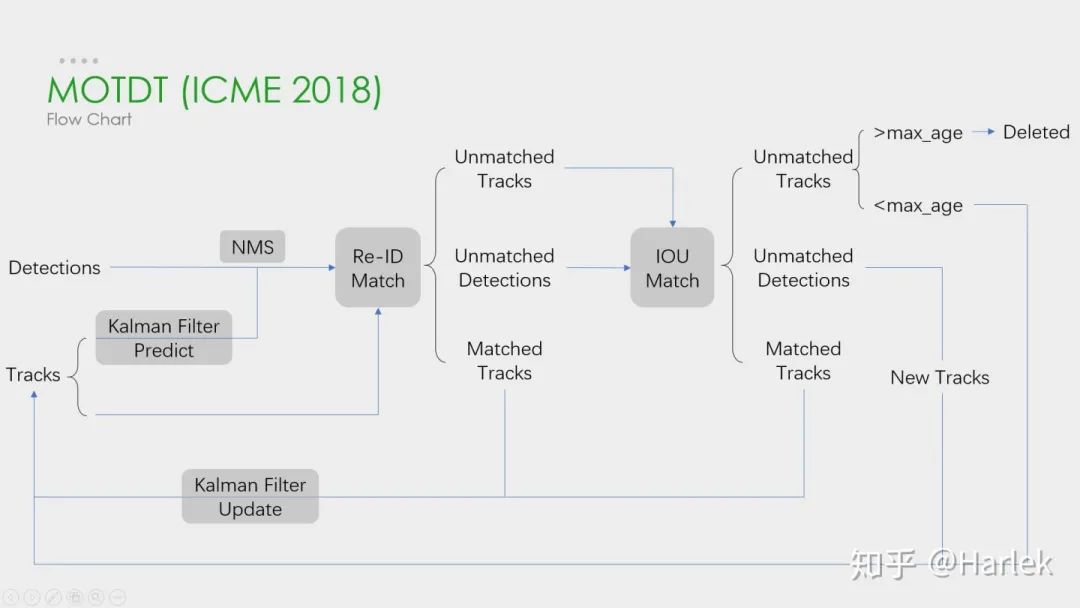
这是刚才列举的第一篇论文(MOTDT)的流程图,大概和DeepSORT差不多。这个图画的比较简单,其实在NMS之前有个基于SqueezeNet的区域选择网络R-FCN和轨迹评分的机制。这两个东西的目的就是为了产生一个统一检测框和预测框的标准置信度,作为NMS的输入。
这篇文章的翻译在《Real-Time Multiple People Tracking With Deeply Learned Candidate Selection And Person Re-ID》论文翻译
http://www.harlek.cn/2019/12/02/real-time-multiple-people-tracking-with-deeply-learned-candidate-selection-and-person-re-id-lun-wen-fan-yi/
JDE
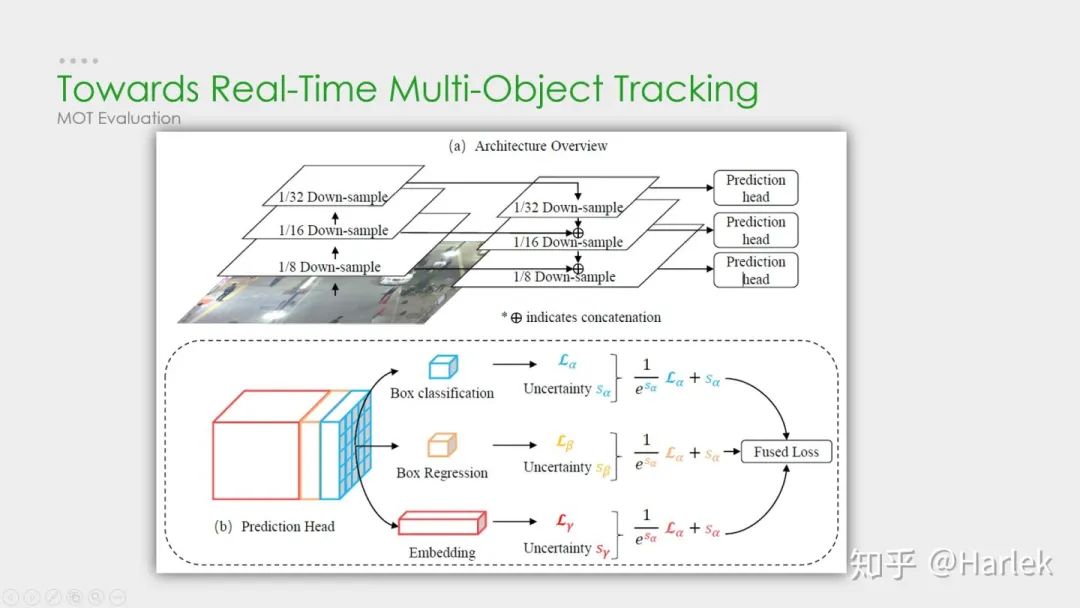
这是刚才第二篇论文(JDE)里的结构图。这个方法是基于YOLOv3和MOTDT做的。它网络前面都和YOLOv3一样的,主要就是在特征图里多提取了一个嵌入(embedding)向量,采取的是类似于交叉熵的triplet loss。因为是多任务学习,这篇论文还用了一篇18年的论文提出来的自动学习损失权重方案:通过学习一组辅助参数自动地对非均匀损失进行加权。最后的结果是精度上差不太多,FPS高了很多。
这篇文章的翻译在 《Towards Real-Time Multi-Object Tracking》论文翻译
http://www.harlek.cn/2019/11/27/towards-real-time-multi-object-tracking-lun-wen-fan-yi/
07

最后用多目标追踪未来的一些思考作为结尾,这句话是最近的一篇关于多目标追踪的综述里的。
它在最后提出对未来的方向里有这样一句话,用深度学习来指导关联问题。其实现在基于检测的多目标追踪都是检测模块用深度学习,Re-ID模块用深度学习,而最核心的数据关联模块要用深度学习来解决是很困难的。现在有一些尝试是用RNN,但速度慢、效果不好,需要走的路都还很长。
我个人觉得短期内要解决实际问题,还是从Re-ID的方面下手思考怎样提取更有效的特征会更靠谱,用深度学习的方法来处理数据关联不是短时间能解决的。
参考文献:
[1] Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In2016 IEEE International Conference on Image Processing (ICIP), pages 3464–3468. IEEE, 2016.
[2] Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep associationmetric. In2017 IEEE International Conference on Image Processing (ICIP), pages 3645–3649. IEEE, 2017.
[3] Chen Long, Ai Haizhou, Zhuang Zijie, and Shang Chong. Real-time multiple people tracking with deeplylearned candidate selection and person re-identification. InICME, 2018.
[4] Zhongdao Wang, Liang Zheng, Yixuan Liu, Shengjin Wang. Towards Real-Time Multi-Object Tracking. arXiv preprint arXiv:1909.12605
[5] Gioele Ciaparrone, Francisco Luque Sánchez, Siham Tabik, Luigi Troiano, Roberto Tagliaferri, Francisco Herrera. Deep Learning in Video Multi-Object Tracking: A Survey. arXiv preprint arXiv:1907.12740

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~