
汇总 | OpenCV4中的非典型深度学习模型
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转载 | 计算机视觉life
引言 ·
前面给大家分别汇总了OpenCV中支持的图像分类与对象检测模型,视觉视觉任务除了分类与检测还有很多其他任务,这里我们就来OpenCV中支持的非分类与检测的视觉模型汇总一下。注意一点,汇总支持的模型都是OpenCV4.4 Github上已经提供的,事实上除了官方的提供的模型,读者还可以自己探索更多非官方模型支持。这里的汇总模型主要来自OpenCV社区官方测试过的。
语义分割网络
OpenCV4 DNN支持的语义分割网络FCN与ENet、ResNet101_DUC_HDC等三个语义分割模型。
FCN
其中FCN主要是基于VGG16~VGG19作为基础网络,速度很慢,该网络是在2015年时候提出,是早期很典型的图像语义分割网络,不是一个对称的卷积反卷积分割网络,在编码阶段网络过长,解码网络很少,结果堪忧!网络结构如下:
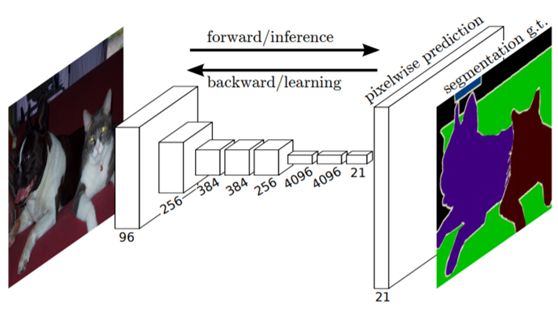
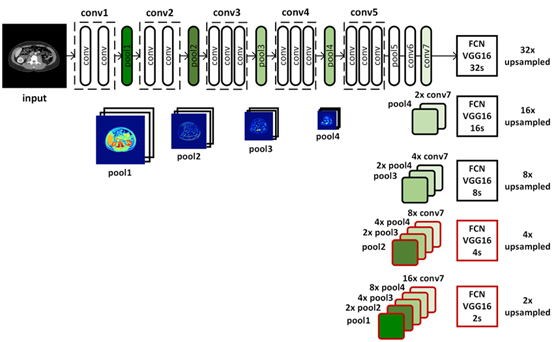
分别支持不同分辨率的上采样。
论文下载地址:
https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdfENet
ENet是一种实时语义分割网络,在2016年提出的,关于ENet语义分割网络,我其实之前写过一篇文章,详细介绍过,这里就不再啰嗦了,直接看这个链接即可:
论文下载地址:
https://arxiv.org/pdf/1606.02147.pdfResNet101_DUC_HDC
该模型在编码网络中基于残差网络与混合空洞卷积(HDC-Hybrid Dilated Convolution),在解码阶段采用密集上采样卷积(DUC-Dense Upsampling Convolution),最终实现了像素级别的图像语义分割网络。网络模型结构如下:
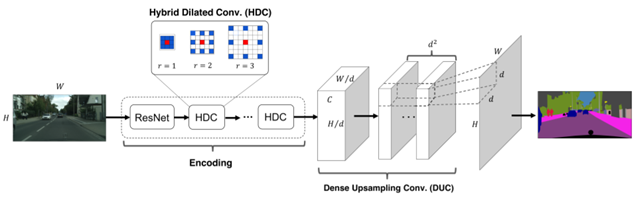
该论文在2017发表,论文地址如下:
https://arxiv.org/pdf/1702.08502.pdf姿态评估
OpenCV DNN支持的姿态评估是基于OpenPose网络实现的身体与手部姿态评估,OpenPose是一个开源的姿态评估项目支持2D与3D模型的姿态评估,提供了C++/Python的API调用接口。模型可以从它github地址获得
https://github.com/CMU-Perceptual-Computing-Lab/openpose相关的模型主要来自它们的系列论文, 姿态评估的基本原理与流程如下:


完整的姿态评估流程入上图,首先预测热图与PAF,然后进行匹配与解析,最终得到输出的姿态评估结果。相关的论文地址如下
https://arxiv.org/pdf/1812.08008v2.pdfhttps://arxiv.org/pdf/1611.08050.pdf
图像处理
OpenCV中图像处理网络支持图像色彩迁移、图像风格迁移、边缘检测。
色彩迁移:
其中灰度图像转换彩色图像的模型结构如下:
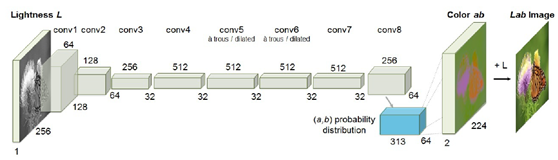
其中有个重要的输入特征点是要把RGB彩色图像转换为LAB通道图像,然后对AB输入,最后结果重新加上L分量。代码在这里
http://richzhang.github.io/colorization/风格迁移
风格迁移网络主要是来自于2016李飞飞等提出感知损失的图像风格迁移与超分辨率论文实现的,网络结构如下:
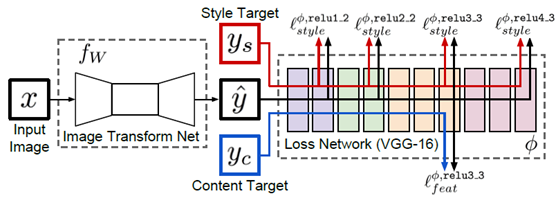
github地址如下:
https://github.com/jcjohnson/fast-neural-style边缘检测
OpenCV中传统的图像边缘检测算法是Canny,现在OpenCV支持基于深度学习的边缘检测算法HED,它与Canny算法的边缘提取效果对比如下:

该论文是在2015年提出的,模型结构如下:
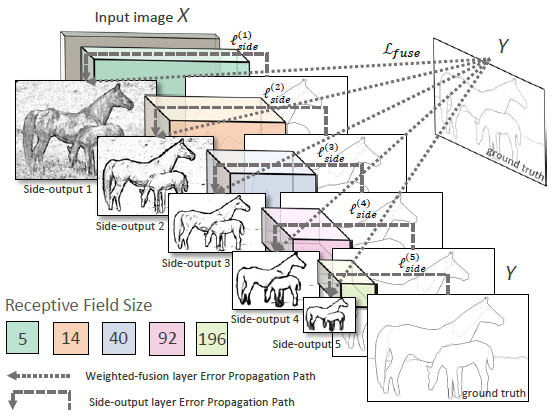
作者选择了VGGNet作为特征提取与基础网络。
论文地址:
https://arxiv.org/pdf/1504.06375.pdf人脸识别
人脸识别来自OpenFace,OpenFace是一种典型的移动端实时的人脸识别模型,跟它相似的还有LightCNN模型。OpenFace是基于facenet的Inception网络作为backbone网络训练生存的torch网络模型,然后基于SVM实现了分类推理,完整的OpenFace项目结构如下:
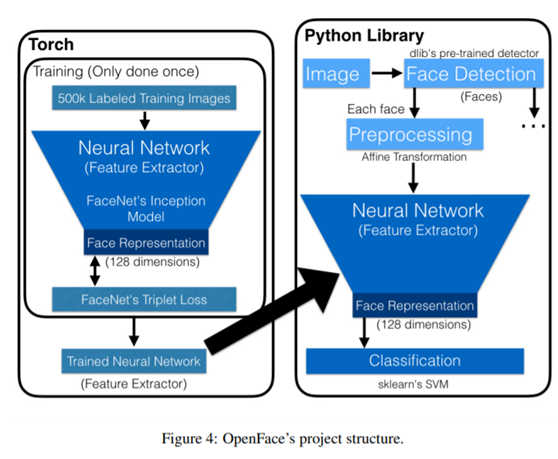
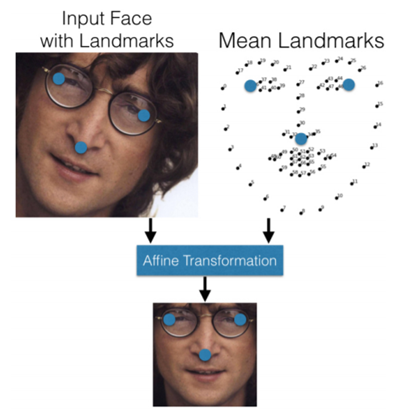
其中预处理阶段的人脸对齐示意图如下:
关于FaceNet的人脸识别论文
https://arxiv.org/pdf/1503.03832.pdfOpenCV DNN支持的8位的量化之后的人脸识别模型,最终输出的向量是128维的,模型下载可以从Github地址:
https://github.com/cmusatyalab/openface场景文字检测
场景文字检测来自2017年旷视科技提出的EAST场景文字检测模型,相关的模型结构如下:
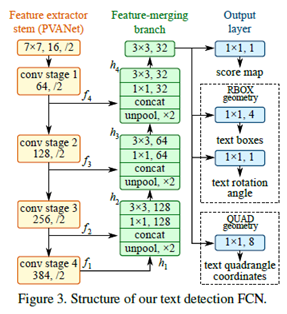
最终输出的文本区域解析后处理如下:
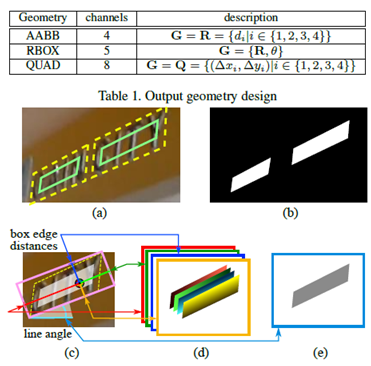
最常见的是解析位RBOX,即带角度的旋转矩形(最小外接矩形)。
论文地址如下:
https://arxiv.org/pdf/1704.03155.pdf最后总结一下,上述网络均支持在OpenCV4.4版本上直接推理运行,或者自定义数据学习之后的在OpenCV4 DNN部署,推理调用。